本文
主要针对CPU的两个漏洞熔断(Meltdown)和幽灵(Spectre),谈谈自己的理解。
| 版本 | 说明 |
|---|---|
| 0.1 | 初版发布 |
参考
| 名称 | 作者 | 来源 |
|---|---|---|
| 《谈谈幽灵和熔断两兄弟》 | 看雪学院-ixiaohuo | 简书 |
专业术语与缩略语
| 缩写 | 全称 | 说明 |
|---|---|---|
| OoO | Out of Order | 乱序执行 |
概述
这两组漏洞来源于为了提高CPU性能而采用的乱序执行和预测执行技术。乱序执行是指CPU并不是严格按照指令的顺序串行执行,而是根据相关性对指令进行并行执行,最后顺序提交。预测执行是CPU根据当前掌握的信息预测某个条件判断的结果,然后选择对应的分支提前执行。
不管是乱序执行和预测执行,总之会使一些指令提前执行,当乱序执行和预测执行发生错误时,会将先前执行的指令作废,flush流水线,保证程序的正确性。但是,CPU进行flush时会作废掉load/store指令,但并不会恢复CPU缓存原始状态,而这两组漏洞正是利用了这一设计上的缺陷进行测信道攻击。
利用乱序执行的是熔断(Meltdown),利用预测执行的是幽灵(Spectre)。
重要概念
乱序执行
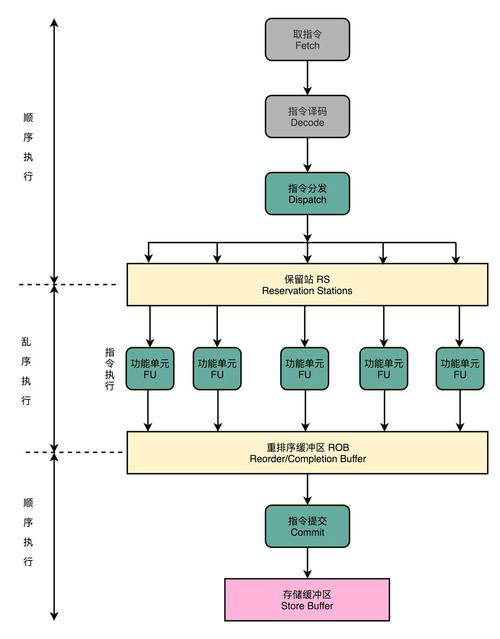
为了进一步提升CPU的性能,基于超标量流水技术的微架构被广泛应用于现代CPU当中,微架构可以依据指令相关性进行乱序执行。顺序提交。乱序执行可以使无依赖指令先执行,以减少指令依赖导致流水线的堵塞,这样可以尽可能保证运算单元不空闲,从而提高处理器性能,最后指令顺序提交,可以保证软件层面的执行顺序。
以下是程序指令,由于指令1/2/3之间存在依赖关系,所以乱序执行处理器中,指令4/5/6可以先于指令2/3执行。
(1) LDR R1, [R0]
(2) ADD R2, R1, 1
(3) SUB R3, R2, 1
(4) ADD R5, R4, 1
(5) ADD R5, R4, 1
(6) ADD R5, R4, 1
分支预测
条件分支指令通常具有两路后续执行分支。即不采取(not taken)跳转,顺序执行后面紧挨JMP的指令;以及采取(taken)跳转到另一块程序内存去执行那里的指令。是否条件跳转,只有在该分支指令在指令流水线中通过了执行阶段(execution stage)才能确定下来。
如果没有分支预测器,处理器将会等待分支指令确定了是否taken,才把下一条指令送入流水线。这种技术叫做流水线停顿或者分支延迟间隙。分支预测器会预测是否taken以及目标地址,直接将后续指令送入流水线,来避免流水线停顿造成的时间浪费。如果后来发现分支预测错误,那么流水线需要作废推测执行的指令,flush流水线。
数据缓存
由于CPU的计算速度要远远的快于存储的读写速度,为了弥补因存储速度造成的计算延迟,提升计算机整体的性能,出现了缓存、主存储器、辅助存储器的三级存储结构,其中缓存的作用是改善主存储器与CPU的速度匹配问题,往往被集成到CPU中。
CPU高速缓存,其容量远小于内存,但速度却可以接近处理器的频率。当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(hit),则不经访问内存直接返回该数据;如果不存在(miss),则要先把内存中的相应数据载入缓存,再将其返回处理器。
之所以CPU高速缓存容量远小于内存,但其仍具有很大的意义就是因为局部性原则:
- 空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的。
- 时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息。
幽灵
幽灵利用的是分支预测机制。
//此段代码非严格符合某语法类型,仅为描述逻辑使用
bit [511:0] array1 [256]; //512宽度是因为cacheline大小为64Byte,256深度是因为1byte表示最大为256。
bit [7:0] array2 [16]; //8宽度是因为作为array1的索引,深度16无特殊意义。
//program
mv r0 #array2_size
str r0 [array2_size_addr]
function1
//清除array1缓存区
//将array2所有元素设置为0
endfunction
function2(input x)
ldr r1 [array2_size_addr_addr] //为了与分支指令形成依赖,使array1的访问可以先执行。
ldr r2 [r1] //r1 也就是array2_size_addr
...
if(x < r1)
{
ldr r2 array2[x];
ldr r3 array1[r2 * 512];
}
endfunction
function3 //依次访问array1所有元素,记录返回时间。
for i is 0 to 255
{
ldr r2 [array1_base_addr + i]
}
endfunction
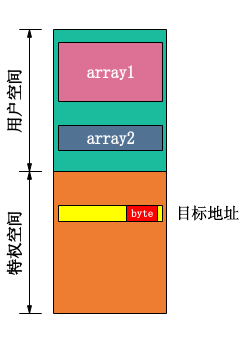
- 第一步先定义array1和array2两个数组空间,同时清除array1的缓存区和将array2所有元素设置为0。
- 第二步多次执行function2,输入符合x小于array2_size的值,训练分支预测器,使其默认为跳转taken。
- 第三步将x设为目标地址(x大于array2_size),执行function2,此时分支指令前的ldr指令会阻碍分支指令执行,而访问array2的指令会先执行,最终会因为if条件不满足而flush流水线,但是数据已经缓存至cache。
- 第四步执行function3,扫描array1的所有元素,记录返回时间,由于之前清除了array1的所有缓存区,function2也只是元素0添加至了缓存区,ldr指令从cache和内存拿数据有明显的时间差,换句话说,存在两个结果:
- 如果扫描结果只有元素0访问最快,则目标地址的数据byte值为0;
- 如果扫描结果有0元素和某index元素访问最快,则目标地址的数据byte值为index。
熔断
幽灵利用的是乱序执行机制。
//此段代码非严格符合某语法类型,仅为描述逻辑使用
bit [511:0] array1 [256]; //512宽度是因为cacheline大小为64Byte,256深度是因为1byte表示最大为256。
//program
function1
//清除array1缓存区
endfunction
function2
ldr r0 byte[x] //x为目标地址,非法操作
ldr r1 array1[r0 * 512];
endfunction
function3 //依次访问array1所有元素,记录返回时间。
for i is 0 to 255
{
ldr r2 [array1_base_addr + i]
}
endfunction
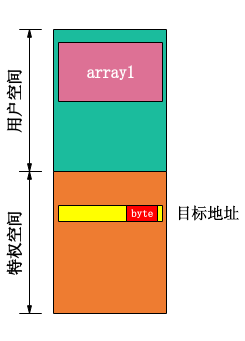
- 第一步先定义array1数组空间,同时清除array1的缓存区。
- 第二步执行function2,访问目标地址(非法),并将返回数据作为array1的index访问array1。
- 第三步执行function3,扫描array1的所有元素,记录返回时间,由于之前清除了array1的所有缓存区,function2也只是元素0添加至了缓存区,ldr指令从cache和内存拿数据有明显的时间差,如果扫描结果为某index元素访问最快,则目标地址的数据byte值为index。
解决方案
待补充
文章原创,可能存在部分错误,欢迎指正,联系邮箱 cao_arvin@163.com。