本文
主要对版本控制工具Git进行简单介绍,以及一些高级场景的应用。
| 版本 | 说明 |
|---|---|
| 0.1 | 初版发布 |
背景
本文非原创,整理自掘金小册收费文章《Git 原理详解及实用指南》,作者: 抛物线。
什么是Git
什么是版本控制
所谓版本控制,意思就是在文件的修改历程中保留修改历史,让你可以方便地撤销之前对文件的修改操作。
版本控制的三个功能需求:
- 版本控制:在项目开发中我们需要能够回退到任何一个版本状态。
- 主动提交:在项目开发中我们需要能够主动提交版本状态,而不是自动保存修改内容某版本,这样可以避免大量的无效版本状态。
- 中央仓库:在项目开发中大多数是多人合作的,需要有一个中央仓库作为代码的存储中心,所有人的改动都会上传到这里,所有人也从这里下载到别人上传的改动。
总结:开发团队中的每个人向中央仓库主动提交自己的改动和同步别人的改动,并在需要的时候查看和操作历史版本,这就是版本控制系统。
中央式版本控制系统
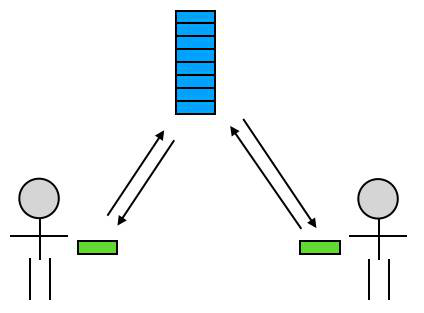
假设你在一个三人团队,你们计划开发一个软件或者系统,并决定使用中央式 VCS 来管理代码。于是:
- 作为项目的主工程师,你独自一人花两天时间搭建了项目的框架;
- 然后,你在公司的服务器上创建了一个中央仓库,并把你的代码提交到了中央仓库上;
- 你的两个队友从中央仓库取到了你的初始代码,从此刻开始,你们三人开始并行开发;
- 在之后的开发过程中,你们三人为了工作方便,总是每人独立负责开发一个功能,在这个功能开发完成后,这个人就把他的这些新代码提交到中央仓库;
- 每次当有人把代码提交到中央仓库的时候,另外两个人就可以选择把这些代码同步到自己的机器上,保持自己的本地代码总是最新的。
而对于团队中的每个人来说,就会更简单一点:
- 第一次加入团队时,把中央仓库的代码取下来;
- 写完的新功能提交到中央仓库;
- 同事提交到中央仓库的新代码,及时同步下来。
这样,一个三人的团队就成功做到了各自在自己的电脑上开发同一个项目,并且互不影响,就好像你们三个人是在同一台电脑上操作一样。
分布式版本控制系统
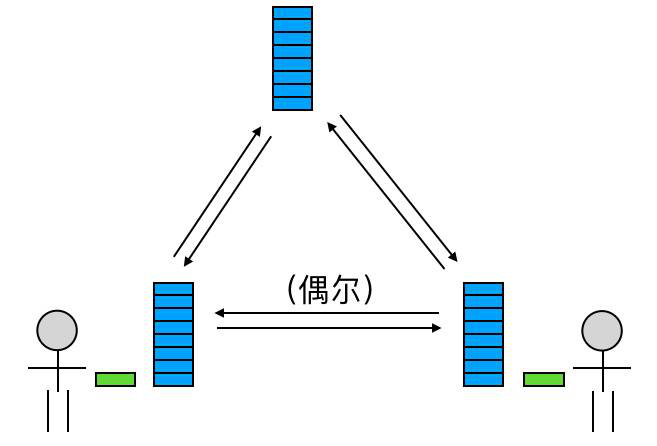
分布式与中央式相比多了本地仓库,一部分版本历史保存在本地仓库,代码同步和版本历史保存在中央仓库。
依然以三人团队为例,分布式 VCS 的工作模型大致是这样:
- 首先,你作为主工程师,独立搭建了项目架构,并把这些代码提交到了本地仓库;
- 然后,你在服务器上创建了一个中央仓库,并把 1)中的提交从本地仓库推送到了服务器的中央仓库;
- 其他同事把中央仓库的所有内容克隆到本地,拥有了各自的本地仓库,从此刻开始,你们三人开始并行开发;
- 在之后的开发过程中,你们三人总是每人独立负责开发一个功能,在这个功能开发过程中,一个人会把它的每一步改动提交到本地仓库。注意:由于本地提交无需立即上传到中央仓库,所以每一步提交不必是一个完整功能,而可以是功能中的一个步骤或块。
- 在一个人把某个功能开发完成之后,他就可以把这个功能相关的所有提交从本地仓库推送到中央仓库;
- 每次当有人把新的提交推送到中央仓库的时候,另外两个人就可以选择把这些提交同步到自己的机器上,并把它们和自己的本地代码合并。
优点与缺点
分布式 VCS 的优点:
- 大多数的操作可以在本地进行,所以速度更快,而且由于无需联网,所以即使不在公司甚至没有在联网,你也可以提交代码、查看历史,从而极大地减小了开发者的网络条件和物理位置的限制(例如,你可以在飞机上提交代码、切换分支等等);
- 由于可以提交到本地,所以你可以分步提交代码,把代码提交做得更细,而不是一个提交包含很多代码,难以 review 也难以回溯。
分布式 VCS 的缺点:
- 由于每一个机器都有完整的本地仓库,所以初次获取项目(Git 术语:clone)的时候会比较耗时;
- 由于每个机器都有完整的本地仓库,所以本地占用的存储比中央式 VCS 要高。
- 补充:项目的大多数内容都是文本形式的代码,再加上版本控制工具可以将文本内容极大的压缩,所以实际上内存大和下载慢的问题并不严重。
如何上手之单人开发
已经有 Git 经验的可以跳过这一节。
安装Git
点击去这里下载个Git,选择对应的平台版本(Linux or Windows),安装到你的机器上。
建个练习仓库
学习的时候最好别拿团队的正式项目练手,先在 GitHub 上建一个自己的练习项目。
- 访问Github。
- 注册或登录您的账号。
- 点击右上角的「New Repository」来新建远程仓库。
- 填写仓库名称(其他的设置可以先不管,默认即可),点击创建。
- 点击右边的「Clone or download」,然后把仓库的 clone 地址复制到剪贴板。
- 把远程仓库取到本地,在 Terminal 或 cmd 中切换到你希望放置项目的目录中,然后输入“git clone 你刚复制的地址”,然后输入正确的用户名和密码。
- 自己写个提交试试:在克隆到本地的仓库目录下新建个文件,比如temp.txt
- 使用“git status” 查看当前状态,temp.txt 文件目前属于 “untracked” 状态,意思是该文件未添加到仓库里,也就没有进行版本追踪。
- 使用“git add temp.txt”将其添加到仓库,仓库开始对齐进行版本追踪。可以看看再使用“git status”会有什么变化。
- 使用add后文件添加到了本地仓库的暂存区,现在需要提交到本地仓库,“git commit -m “这里写提交注释””,可以看看再使用“git status”会有什么变化,再使用“git log”查看提交历史,可以看到此次的提交。
- 修改temp.txt文件,执行“git status”会发现文件被修改的提示,重复添加和提交命令,再使用“git log”查看提交历史,可以看到两次的提交。
- 推送到远程仓库:使用 git push 来把本地提交上传到远程中央仓库。可以在github网页上看到自己本地内容已经更新到远程仓库。
总结
单人开发的基本工作模式如下:
- 从 GitHub 把中央仓库 clone 到本地(使用命令: git clone)
- 把写完的代码提交(先用 git add 文件名 把文件添加到暂存区,再用 git commit 提交)
- 在这个过程中,可以使用 git status 来随时查看工作目录的状态
- 每个文件有 “changed / unstaged”(已修改), “staged”(已修改并暂存), “commited”(已提交) 三种状态,以及一种特殊状态 “untracked”(未跟踪)
- 提交一次或多次之后,把本地提交 push 到中央仓库(git push)
如何上手之多人协作
对于 Git 来说,团队合作和个人独立工作最大的不同在于,你会提交代码,别人也会提交;你会 push,别人也会 push,因此除了把代码上传,每个人还需要把别人最新的代码下载到自己的电脑。而且,这些工作都是并行进行的。
把别人的新提交拿到本地
- 首先你需要一饰多角,除非有同事和你一起练习。为了模拟同事的操作,你需要创建两个文件夹worker1和worker2,在这两个文件夹下将远程仓库clone到本地。现在两个本地仓库就可以代表两个同事在操作了。
- worker1提交代码并push到中央仓库:切换worker1的本地仓库,帮他创建个文件写点代码,并依次进行add、commit、push。此时远程中央仓库可以看到已经更新的内容。
- worker2更新远程仓库到本地:切换worker2的本地仓库,使用“git pull”将远程仓库内容更新到本地,这时候可以看到worker1的修改的内容。
多人合作的基本工作模型
这就完成了一次简单的合作流程:
- worker1 commit 代码到他的本地,并 push 到 GitHub 中央仓库
- worker2把 GitHub 的新提交通过 pull 指令来取到你的本地
比如worker1是同事,worker2是自己,通过这个流程,你和同事就可以简单地合作了:你写了代码,commit,push 到 GitHub,然后他 pull 到他的本地;他再写代码,commit, push 到 GitHub,然后你再 pull 到你的本地。你来我往,配合得不亦乐乎。
但是,这种合作有一个严重的问题:同一时间内,只能有一个人在工作。你和同事其中一个人写代码的时候,另一个人不能做事,必须等着他把工作做完,代码 push 到 GitHub 以后,自己才能把 push 上去的代码 pull 到自己的本地。而如果同时做事,就会发生冲突:当一个人先于另一个人 push 代码(这种情况必然会发生),那么后 push 的这个人就会由于中央仓库上含有本地没有的提交而导致 push 失败。因为 Git 的push 其实是用本地仓库的 commits 记录去覆盖远端仓库的 commits 记录(注:这是简化概念后的说法,push 的实质和这个说法略有不同),而如果在远端仓库含有本地没有的 commits 的时候,push (如果成功)将会导致远端的 commits 被擦掉。这种结果当然是不可行的,因此 Git 会在 push 的时候进行检查,如果出现这样的情况,push 就会失败。
解决push冲突
在现实的团队开发中,全队是同时并行开发的,所以必然会出现当一人 push 代码时,中央仓库已经被其他同事先一步 push 了的情况。为了不让文段显得太过混乱,这里我就不带着你一步步模拟这个过程了。如果你希望模拟的话,这里是步骤:
- 切换到worker1,做一个 commit,然后 push 到 GitHub
- 切换到worker2,做一个不一样的 commit。
这个时候,远端中央仓库已经有了别人 push 的 commit,现在你如果 push 的话,由于 GitHub 的远端仓库上含有本地仓库没有的内容,所以这次 push 被拒绝了。
这种冲突的解决方式其实很简单:先用 pull 把远端仓库上的新内容取回到本地和本地合并,然后再把合并后的本地仓库向远端仓库推送。这次的 git pull 操作并没有像之前的那样直接结束,而是进入了上图这样的一个输入提交信息的界面。这是因为当 pull 操作发现不仅远端仓库包含本地没有的 commits,而且本地仓库也包含远端没有的 commits 时,它就会把远端和本地的独有 commits 进行合并,自动生成一个新的 commit ,而上图的这个界面,就是这个自动生成的 commit 的提交信息界面。另外,和手动的 commit 不同,这种 commit 会自动填入一个默认的提交信息,简单说明了这条 commit 的来由。你可以直接退出界面来使用这个自动填写的提交信息,也可以修改它来填入自己提交信息。在退出提交信息的界面后,这次 pull 就完成了:远端仓库被取到了本地,并和本地仓库进行了合并。在这个时候,就可以再 push 一次了。由于现在本地仓库已经包含了所有远端仓库的 commits,所以这次 push 不会再失败。
补充:这种“把不同的内容进行合并,生成新的提交”的操作,叫做合并,它所对应的 Git 指令是 merge。事实上,git pull 这个指令的内部实现就是把远程仓库使用 git fetch 取下来以后再进行 merge 操作的。
总结
多人协作的基本工作模式如下:
- 写完所有的 commit 后,不用考虑中央仓库是否有新的提交,直接 push 就好
- 如果 push 失败,就用 pull 把本地仓库的提交和中央仓库的提交进行合并,然后再 push 一次
到此为止,这个工作模型已经是一个最简单的可用的工作模型了。一个小团队如果对版本管理没有什么要求的话,这个工作模型已经可以让团队用来合作开发了。复杂的版本管理还会设计branch,不过对于新人上手,应该先掌握以上内容就基本可以应付日常操作了。
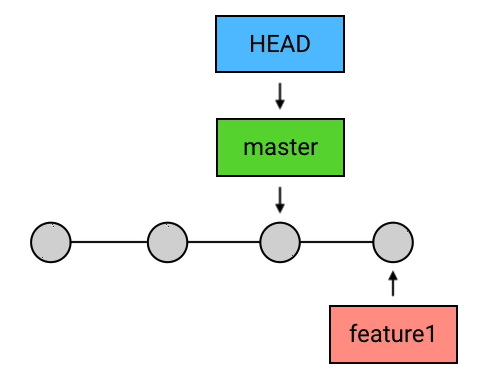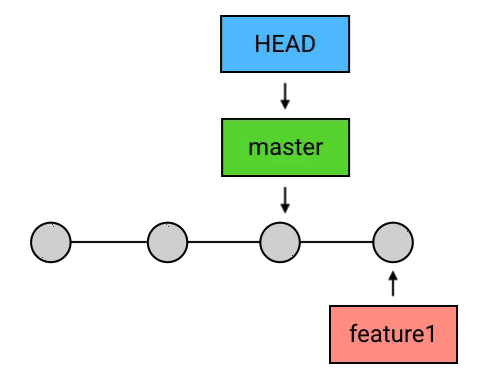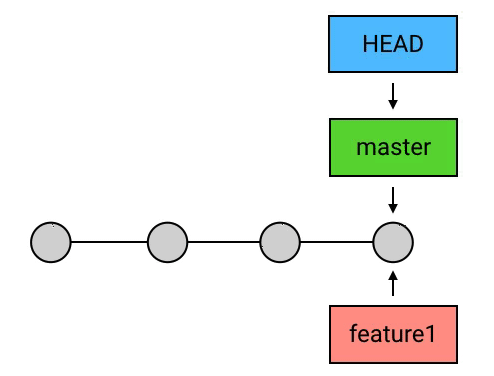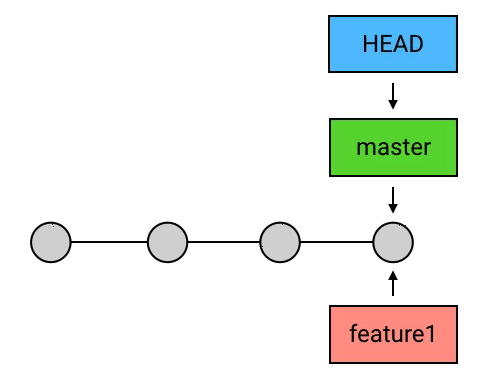
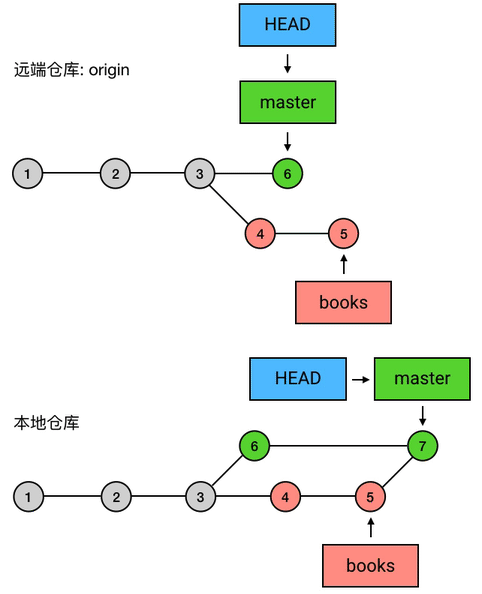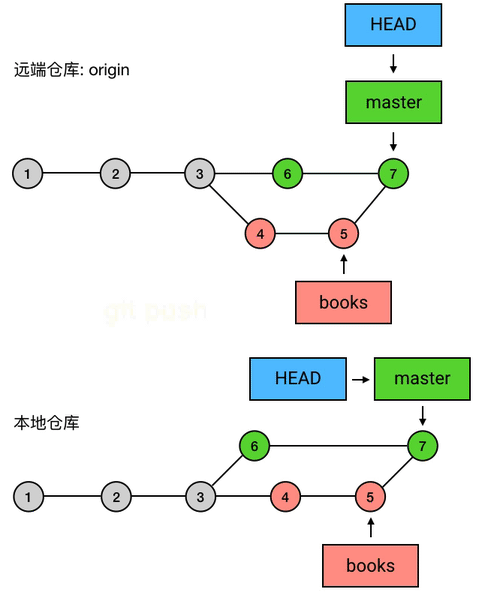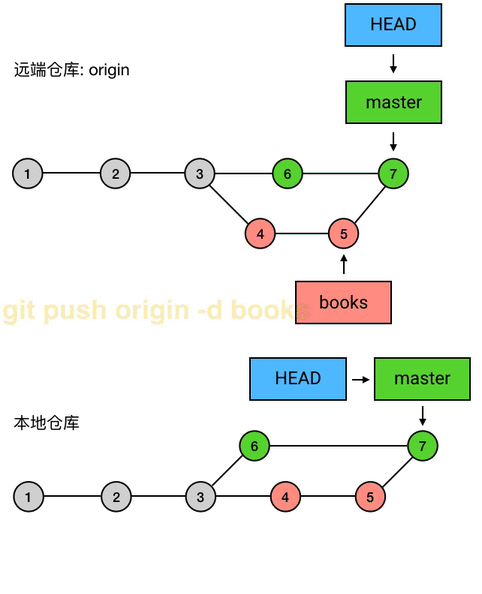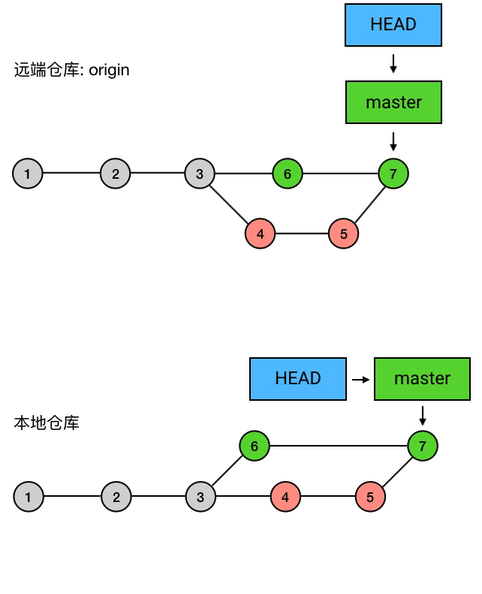
进阶1:HEAD、master 与 branch
引用:commit 的快捷方式
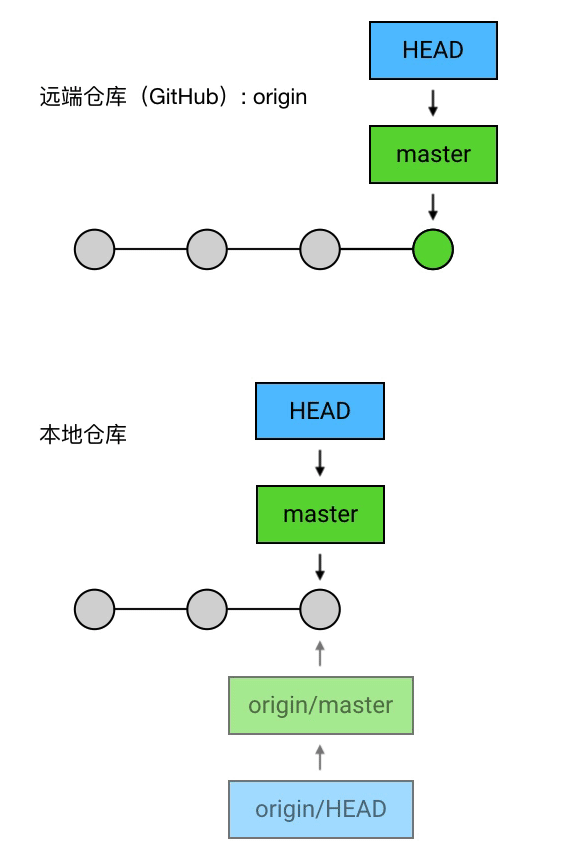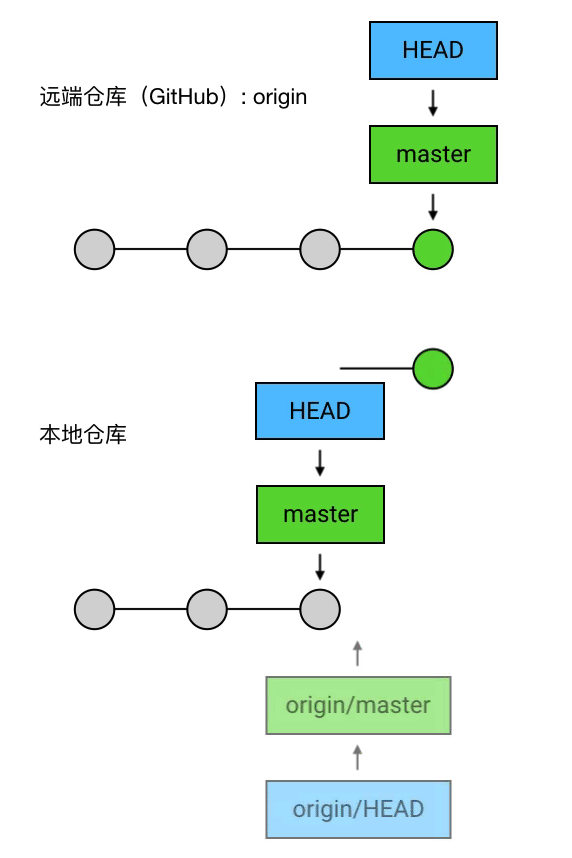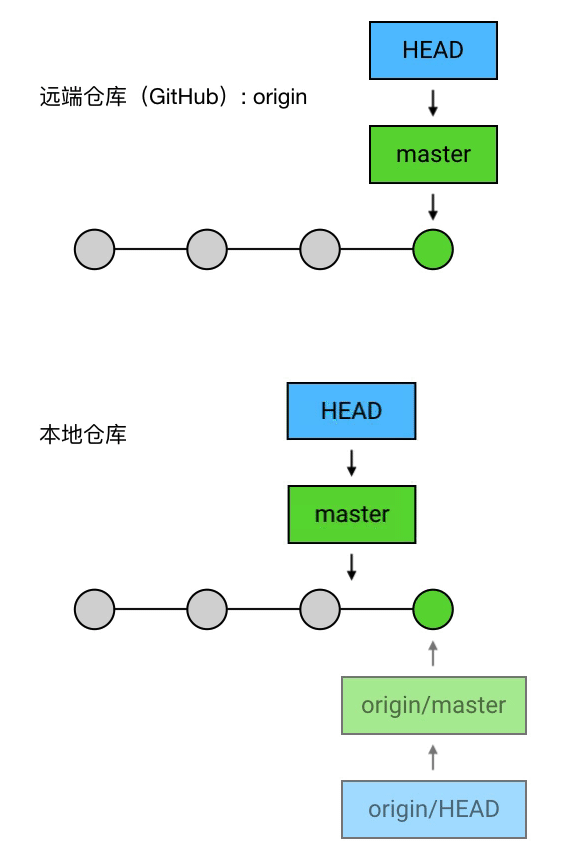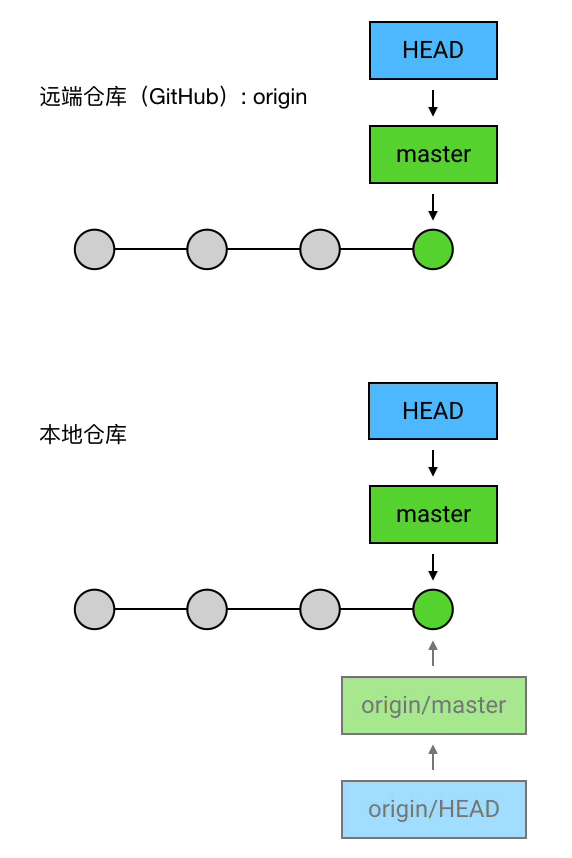
首先使用“git log”查看一些提交信息:第一行的 commit 后面括号里的 HEAD -> master, origin/master, origin/HEAD ,是几个指向这个 commit 的引用。在 Git 的使用中,经常会需要对指定的 commit 进行操作。每一个 commit 都有一个它唯一的指定方式——它的 SHA-1 校验和,也就是上图中每个黄色的 commit 右边的那一长串字符。两个 SHA-1 值的重复概率极低,所以你可以使用这个 SHA-1 值来指代 commit,也可以只使用它的前几位来指代它(例如第一个 78bb0ab7d541…16b77,你使用 78bb0ab 甚至 78bb 来指代它通常也可以),但毕竟这种没有任何含义的字符串是很难记忆的,所以 Git 提供了「引用」的机制:使用固定的字符串作为引用,指向某个 commit,作为操作 commit 时的快捷方式。
HEAD:当前 commit 的引用
这个括号里的 HEAD 是引用中最特殊的一个:它是指向当前 commit 的引用。所谓 当前 commit 这个概念很简单,它指的就是当前工作目录所对应的 commit。
当前 commit 就是第一行中的那个最新的 commit。每次当有新的 commit 的时候,工作目录自动与最新的 commit 对应;而与此同时,HEAD 也会转而指向最新的 commit。事实上,当使用 checkout、reset 等指令手动指定改变当前 commit 的时候,HEAD 也会一起跟过去。
总之,当前 commit 在哪里,HEAD 就在哪里,这是一个永远自动指向当前 commit 的引用,所以你永远可以用 HEAD 来操作当前 commit。
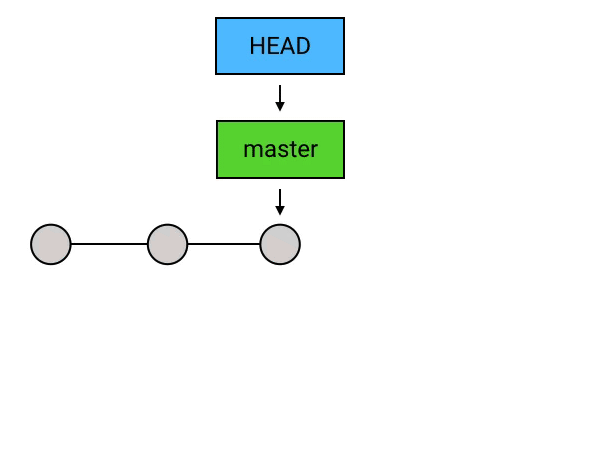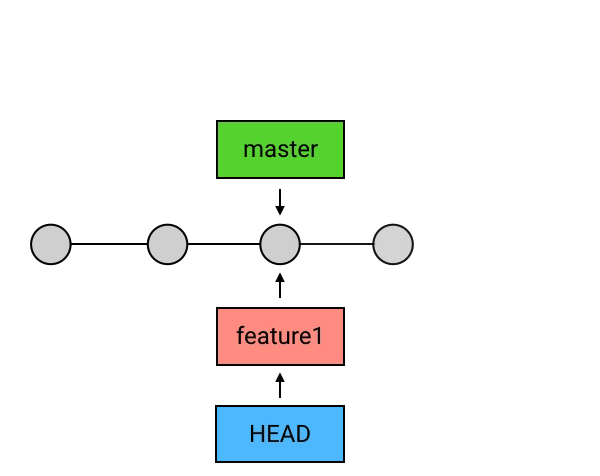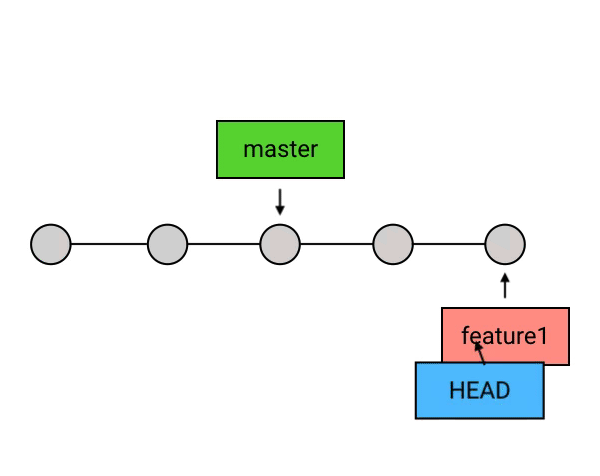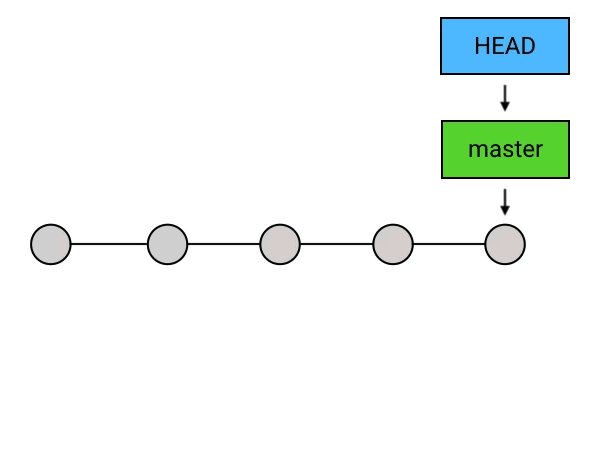
branch
HEAD 是 Git 中一个独特的引用,它是唯一的。而除了 HEAD 之外,Git 还有一种引用,叫做 branch(分支)。HEAD 除了可以指向 commit,还可以指向一个 branch,当它指向某个 branch 的时候,会通过这个 branch 来间接地指向某个 commit;另外,当 HEAD 在提交时自动向前移动的时候,它会像一个拖钩一样带着它所指向的 branch 一起移动。
“git log”显示结果中,HEAD -> master 中的 master 就是一个 branch 的名字,而它左边的箭头 -> 表示 HEAD 正指向它(当然,也会间接地指向它所指向的 commit)。如果我在这时创建一个 commit,那么 HEAD 会带着 master 一起移动到最新的。
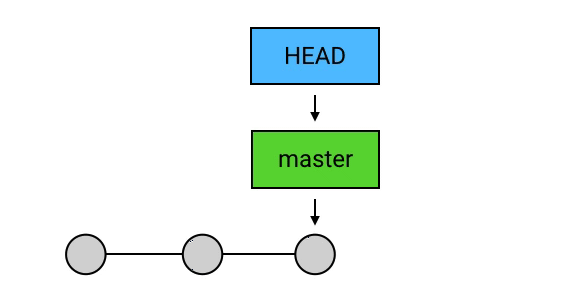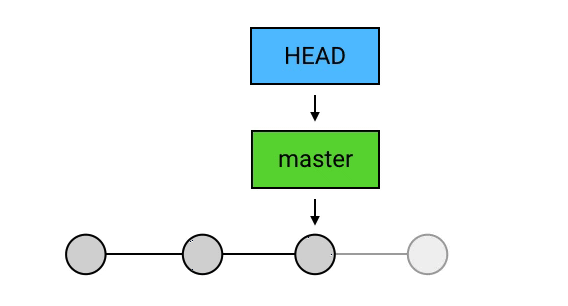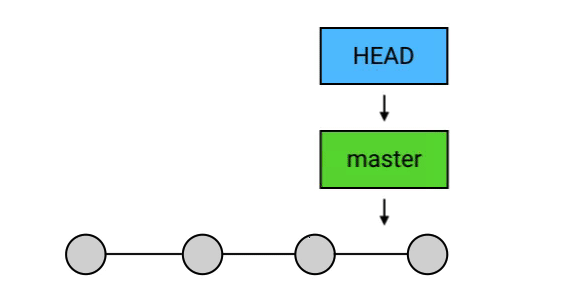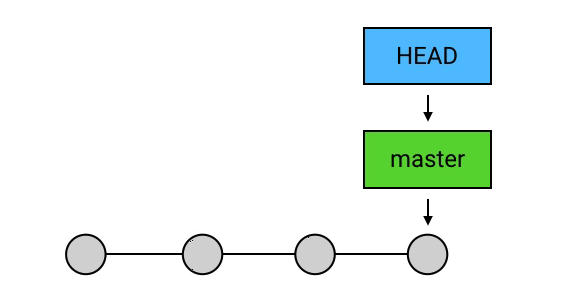
master:默认的 branch
上面的这个 master ,其实是一个特殊的 branch:它是 Git 的默认 branch(俗称主 branch / 主分支)。
所谓的「默认 branch」,主要有两个特点:
- 新创建的 repository(仓库)是没有任何 commit 的。但在它创建第一个 commit 时,会把 master 指向它,并把 HEAD 指向 master。
- 当有人使用 git clone 时,除了从远程仓库把 .git 这个仓库目录下载到工作目录中,还会 checkout (签出) master(checkout 的意思就是把某个 commit 作为当前 commit,把 HEAD 移动过去,并把工作目录的文件内容替换成这个 commit 所对应的内容)。
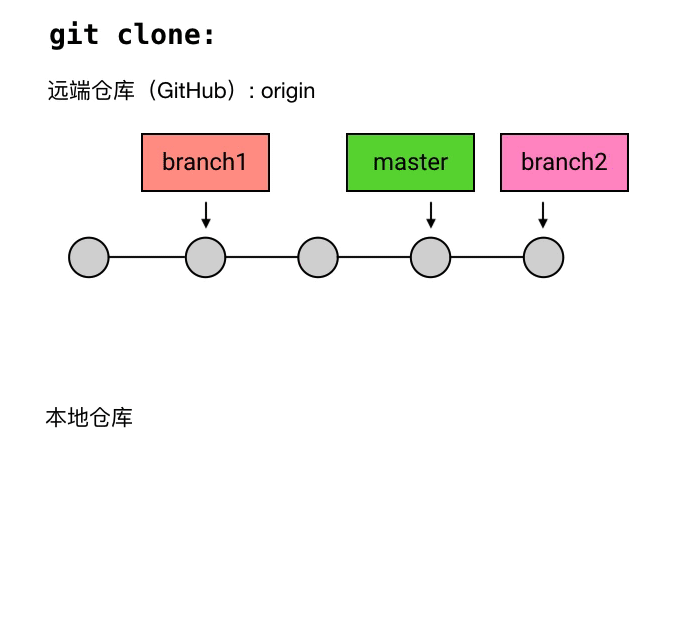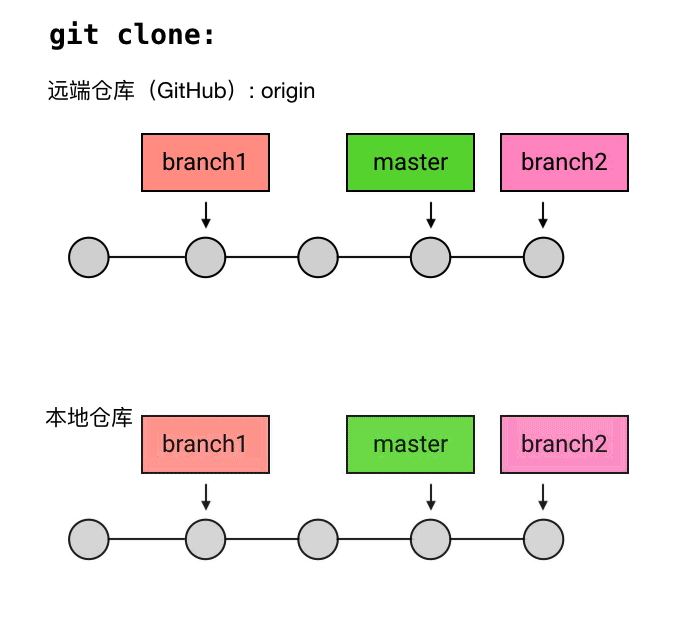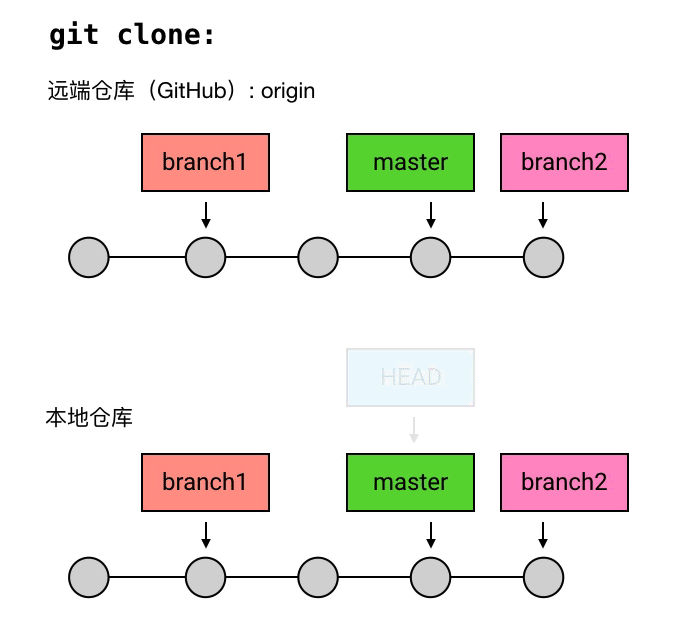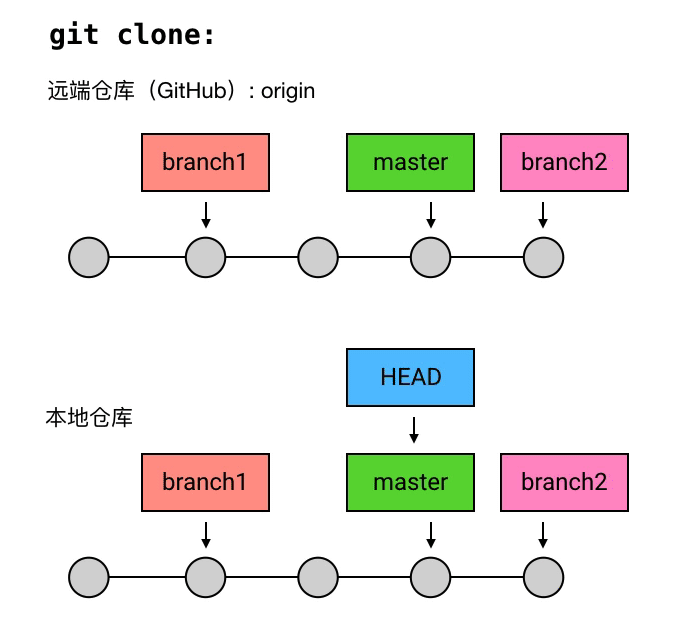
branch 的通俗化理解
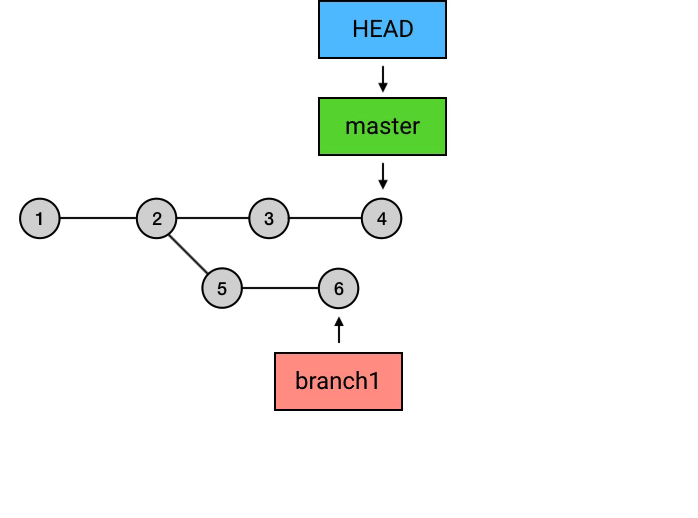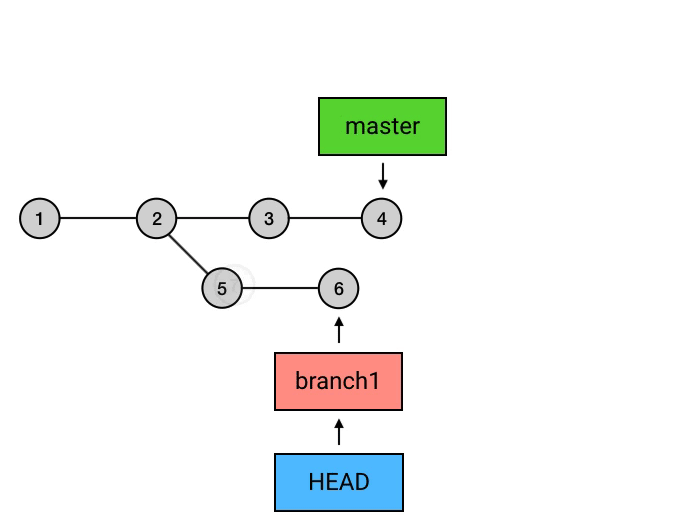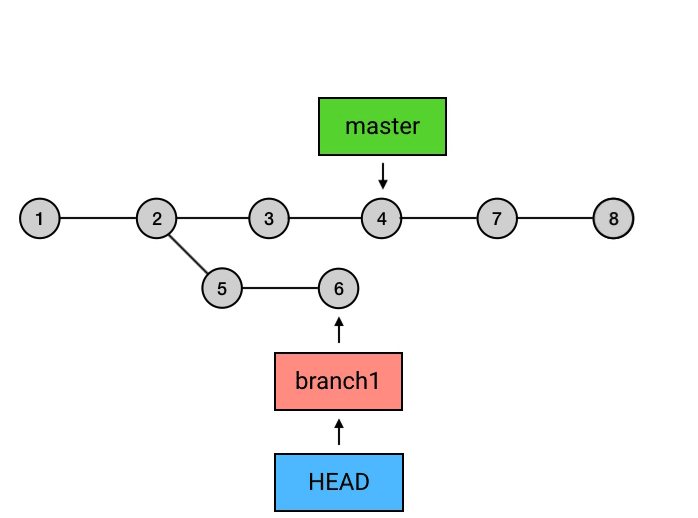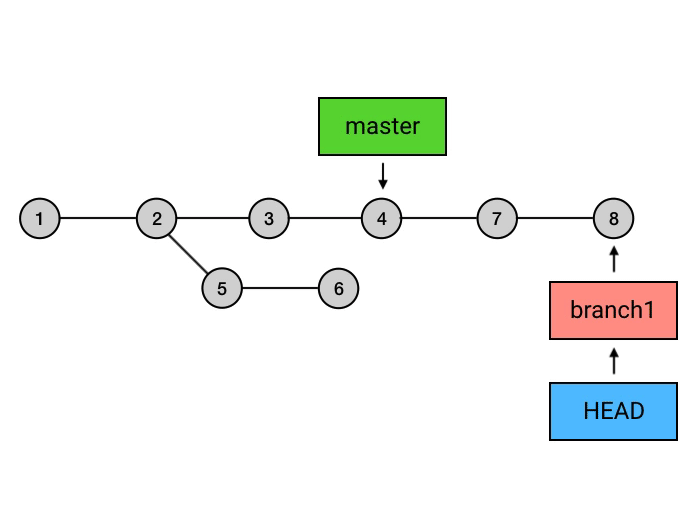
尽管在 Git 中,branch 只是一个指向 commit 的引用,但它有一个更通俗的理解:你还可以把一个 branch 理解为从初始 commit 到 branch 所指向的 commit 之间的所有 commits 的一个「串」。这种理解方式比较符合 branch 这个名字的本意(branch 的本意是树枝,可以延伸为事物的分支),也是大多数人对 branch 的理解。不过如果你选择这样理解 branch,需要注意下面两点:
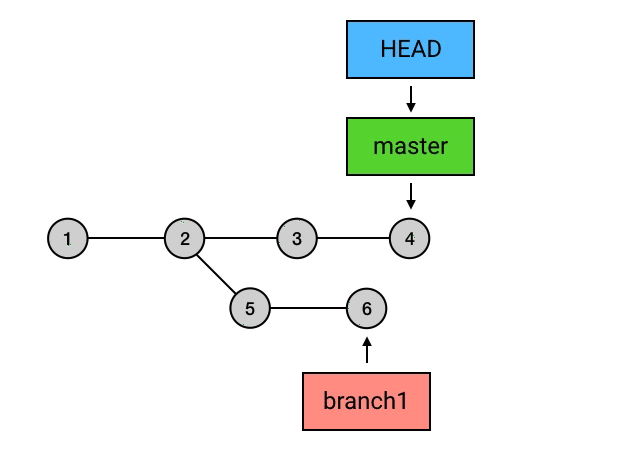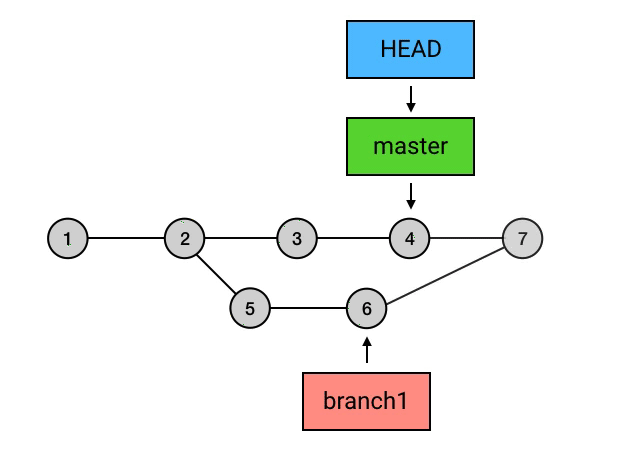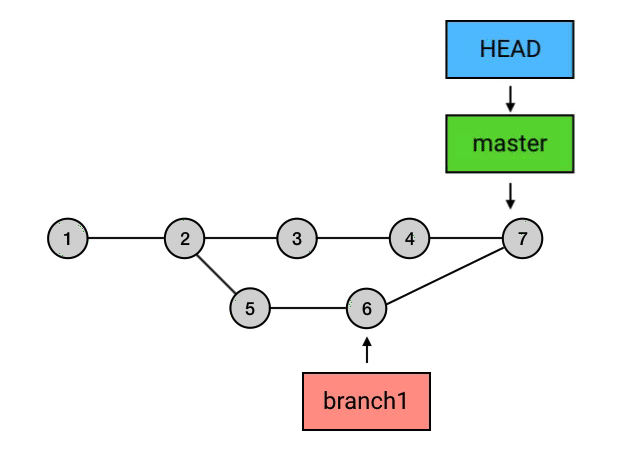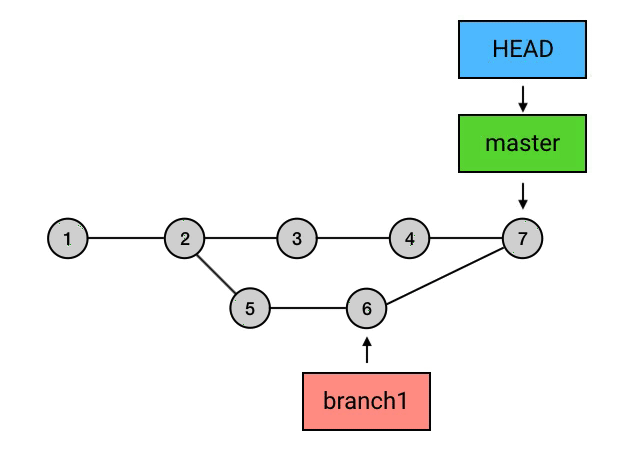
- 所有的 branch 之间都是平等的,如下图,branch1 是 1 2 5 6 的串,而不要理解为 2 5 6 或者 5 6 。其实,起点在哪里并不是最重要的,重要的是你要知道,所有 branch 之间是平等的,master 除了上面我说的那几点之外,并不比其他 branch 高级。这个认知的理解对于 branch 的正确使用非常重要。
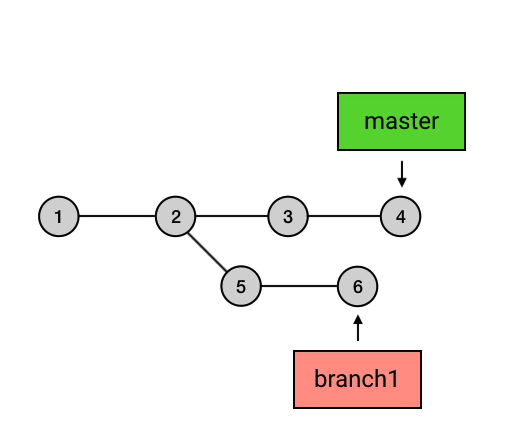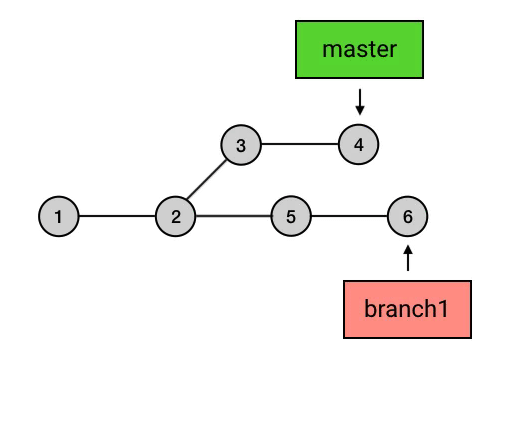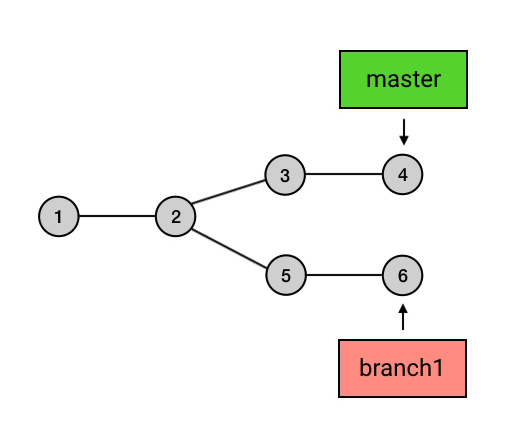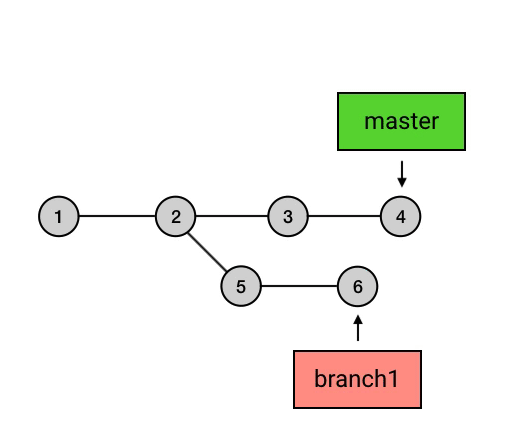
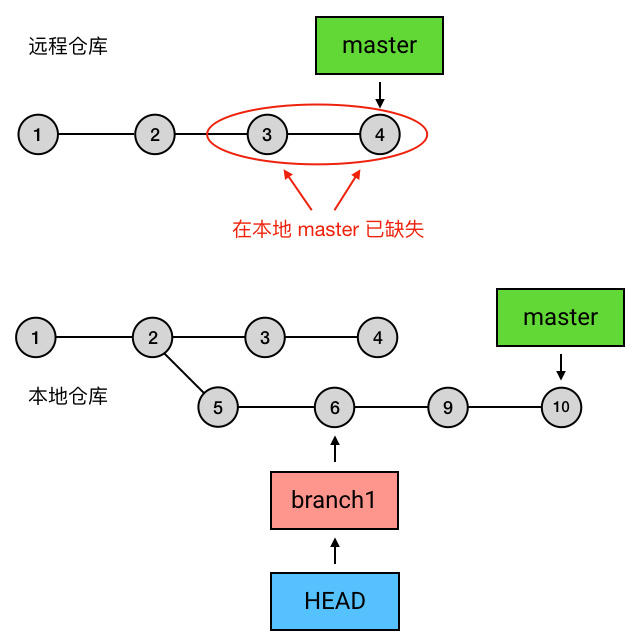
- branch 包含了从初始 commit 到它的所有路径,而不是一条路径。并且,这些路径之间也是彼此平等的。如下图,master 在合并了 branch1 之后,从初始 commit 到 master 有了两条路径。这时,master 的串就包含了 1 2 3 4 7 和 1 2 5 6 7 这两条路径。而且,这两条路径是平等的,1 2 3 4 7 这条路径并不会因为它是「原生路径」而拥有任何的特别之处。
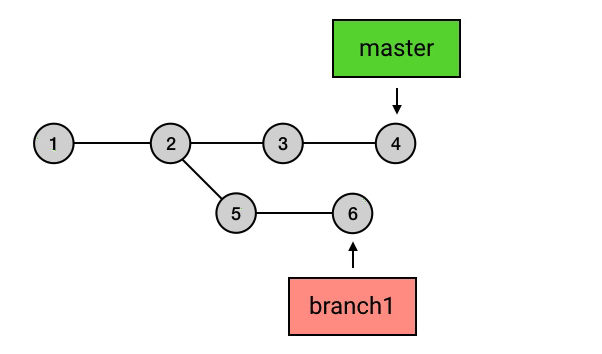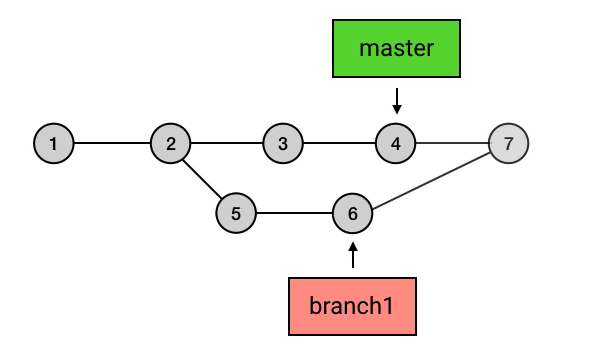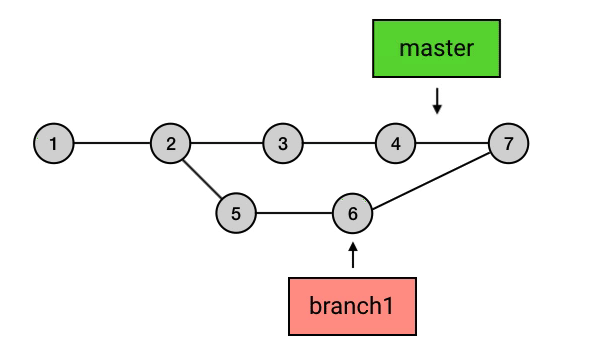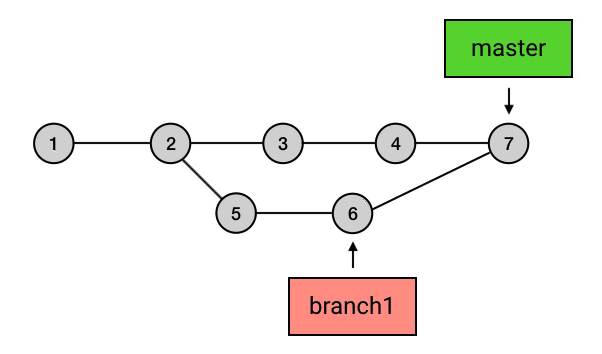
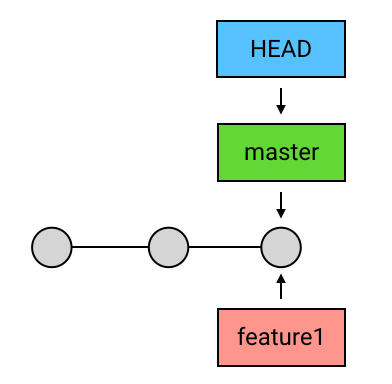
branch 的创建、切换和删除
创建 branch:
如果你想在某处创建 branch ,只需要输入一行 git branch 名称。例如“git branch feature1”
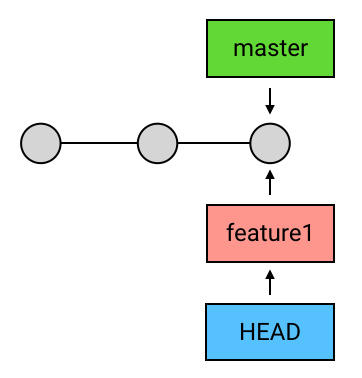
切换 branch:
新建的 branch 并不会自动切换,你的 HEAD 在这时依然是指向 master 的。你需要用 checkout 来主动切换到你的新 branch 去“git checkout feature1”。(也可以使用git checkout -b 名称 来把上面两步操作合并执行)
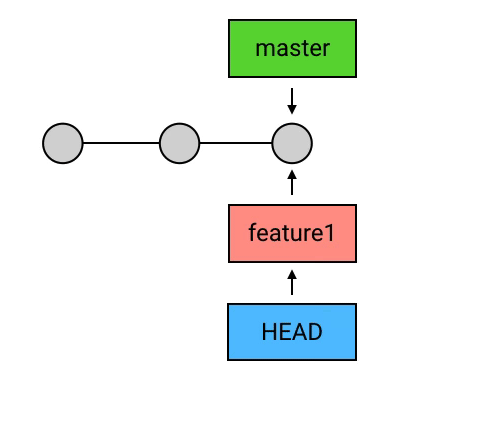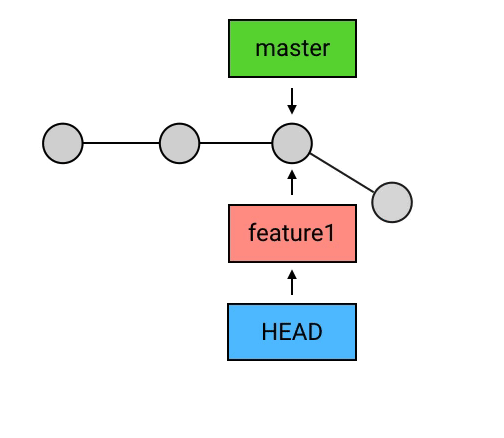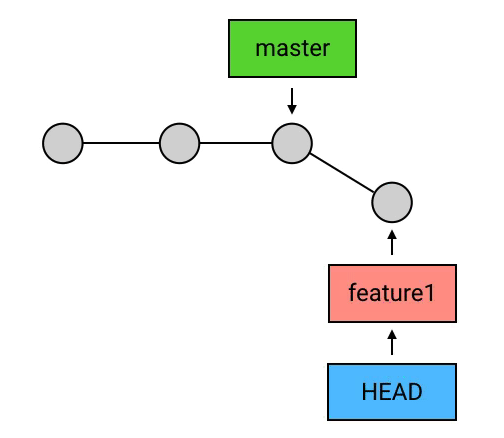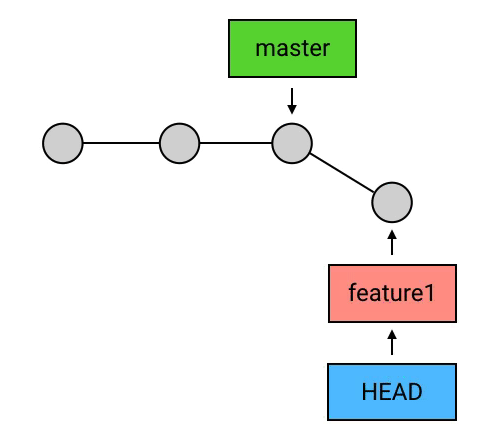
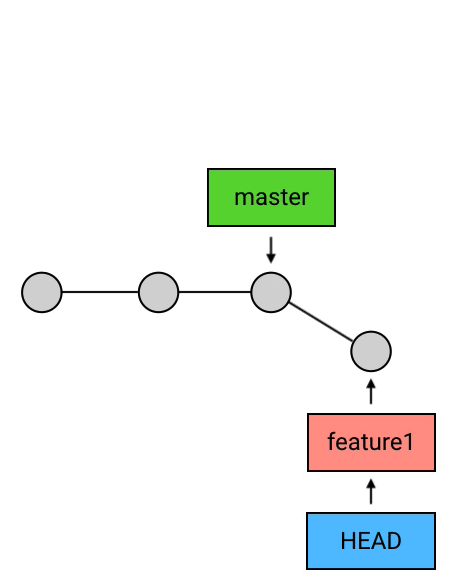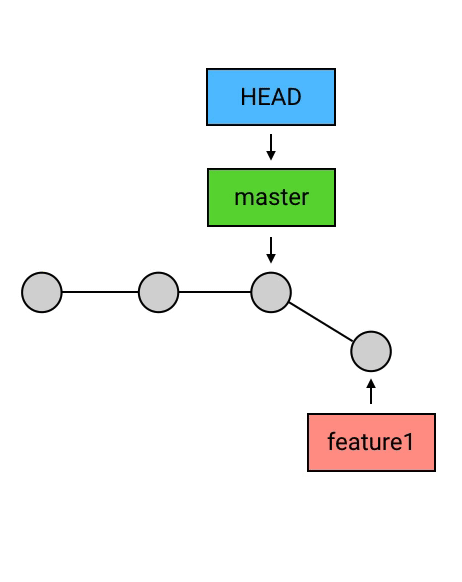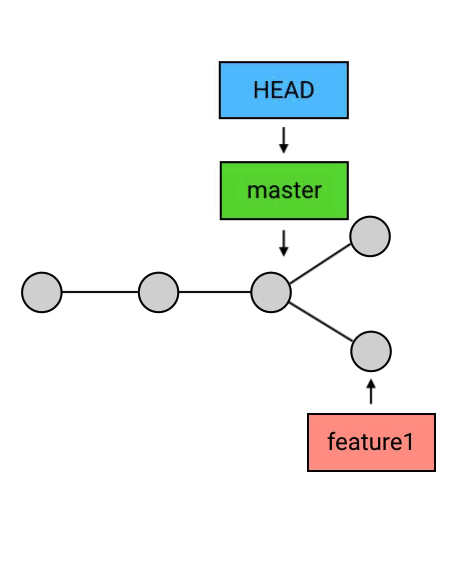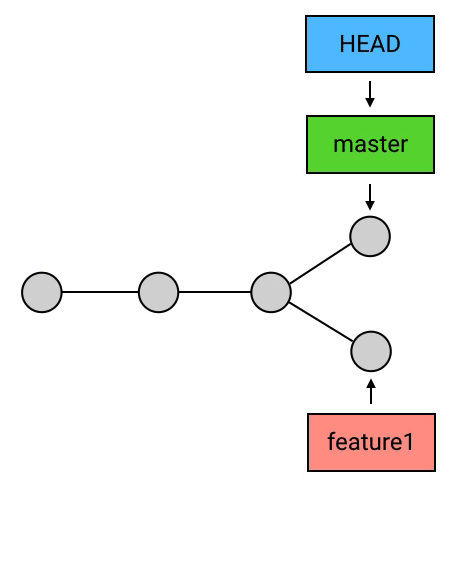
删除 branch:
删除 branch 的方法非常简单:git branch -d 名称。例如要删除 feature1 这个 branch:“git branch -d feature1”
需要说明的有三点:
- HEAD 指向的 branch 不能删除。如果要删除 HEAD 指向的 branch,需要先用 checkout 把 HEAD 指向其他地方。
- 由于 Git 中的 branch 只是一个引用,所以删除 branch 的操作也只会删掉这个引用,并不会删除任何的 commit。(不过如果一个 commit 不在任何一个 branch 的「路径」上,或者换句话说,如果没有任何一个 branch 可以回溯到这条 commit(也许可以称为野生 commit?),那么在一定时间后,它会被 Git 的回收机制删除掉。)
- 出于安全考虑,没有被合并到 master 过的 branch 在删除时会失败(因为怕你误删掉「未完成」的 branch 啊),这种情况如果你确认是要删除这个 branch (例如某个未完成的功能被团队确认永久毙掉了,不再做了),可以把 -d 改成 -D,小写换成大写,就能删除了。
引用的本质
所谓「引用」(reference),其实就是一个个的字符串。这个字符串可以是一个 commit 的 SHA-1 码(例:c08de9a4d8771144cd23986f9f76c4ed729e69b0),也可以是一个 branch(例:ref: refs/heads/feature3)。
Git 中的 HEAD 和每一个 branch 以及其他的引用,都是以文本文件的形式存储在本地仓库 .git 目录中,而 Git 在工作的时候,就是通过这些文本文件的内容来判断这些所谓的「引用」是指向谁的。
总结
- HEAD 是指向当前 commit 的引用,它具有唯一性,每个仓库中只有一个 HEAD。在每次提交时它都会自动向前移动到最新的 commit 。
- branch 是一类引用。HEAD 除了直接指向 commit,也可以通过指向某个 branch 来间接指向 commit。当 HEAD 指向一个 branch 时,commit 发生时,HEAD 会带着它所指向的 branch 一起移动。
- master 是 Git 中的默认 branch,它和其它 branch 的区别在于:
- 新建的仓库中的第一个 commit 会被 master 自动指向;
- 在 git clone 时,会自动 checkout 出 master。
- branch 的创建、切换和删除:
- 创建 branch 的方式是 git branch 名称 或 git checkout -b 名称(创建后自动切换);
- 切换的方式是 git checkout 名称;
- 删除的方式是 git branch -d 名称。
进阶2:push的本质
在之前的内容里,我粗略地说过,push 指令做的事是把你的本地提交上传到中央仓库去,用本地的内容来覆盖掉远端的内容。这个说法其实是不够准确的,但 Git 的知识系统比较庞大,在你对 Git 了解比较少的时候,用「上传本地提交」来解释会比较好理解;而在你知道了 branch,并且明白了 branch 的具体含义以后,我就可以告诉你 push 到底是什么了。
push:把 branch 上传到远端仓库
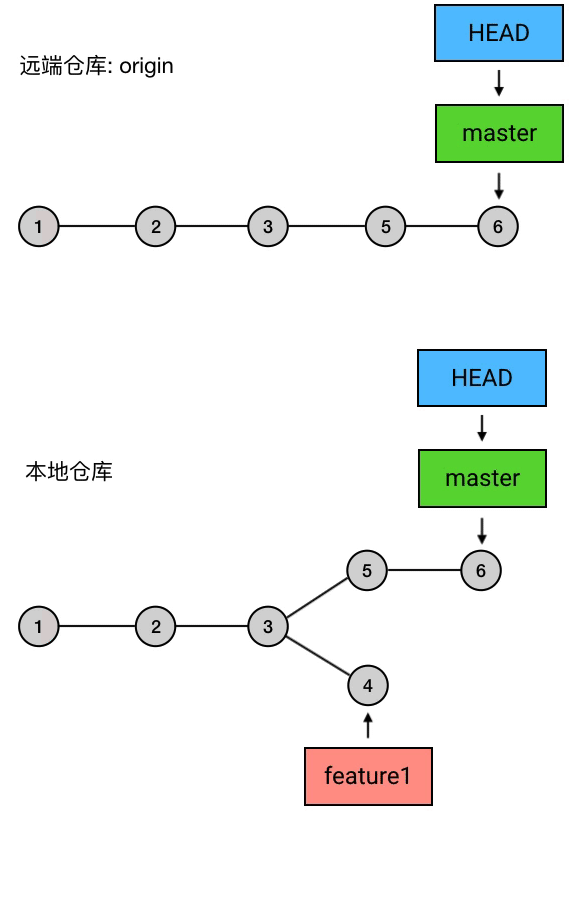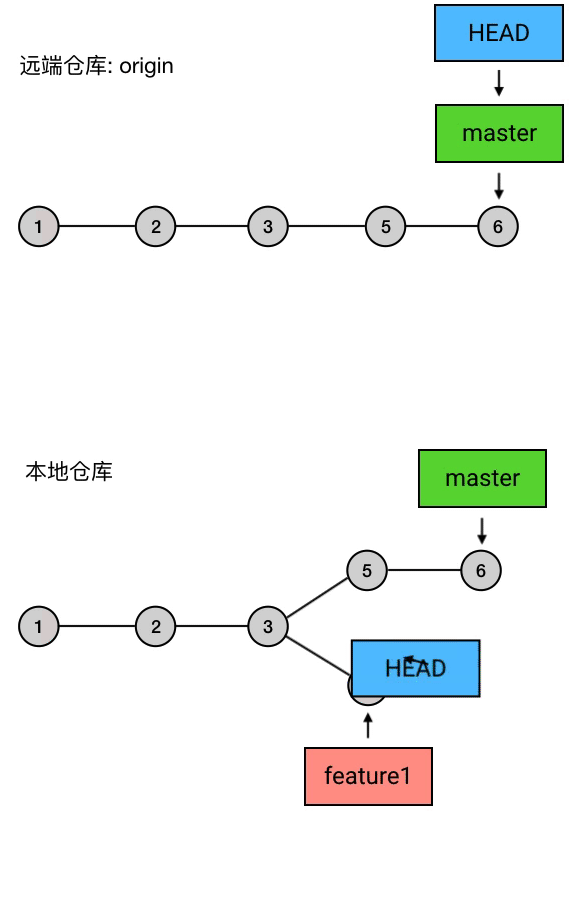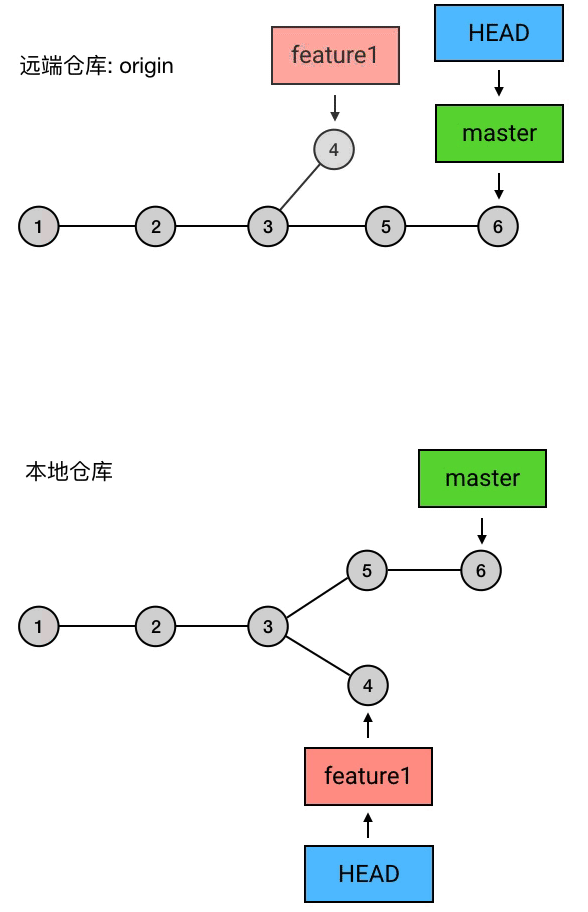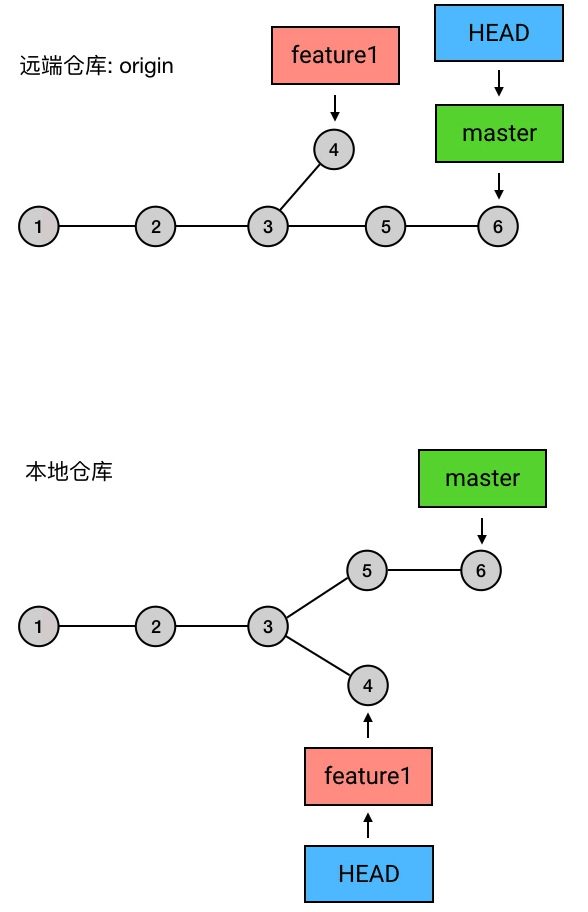
实质上,push 做的事是:把当前 branch 的位置(即它指向哪个 commit)上传到远端仓库,并把它的路径上的 commits 一并上传。
例如,我现在的本地仓库有一个 master ,它超前了远程仓库两个提交;另外还有一个新建的 branch 叫 feature1,远程仓库还没有记载过它。这时我执行 git push,就会把 master 的最新位置更新到远端,并且把它的路径上的 5 6 两个 commits 上传:
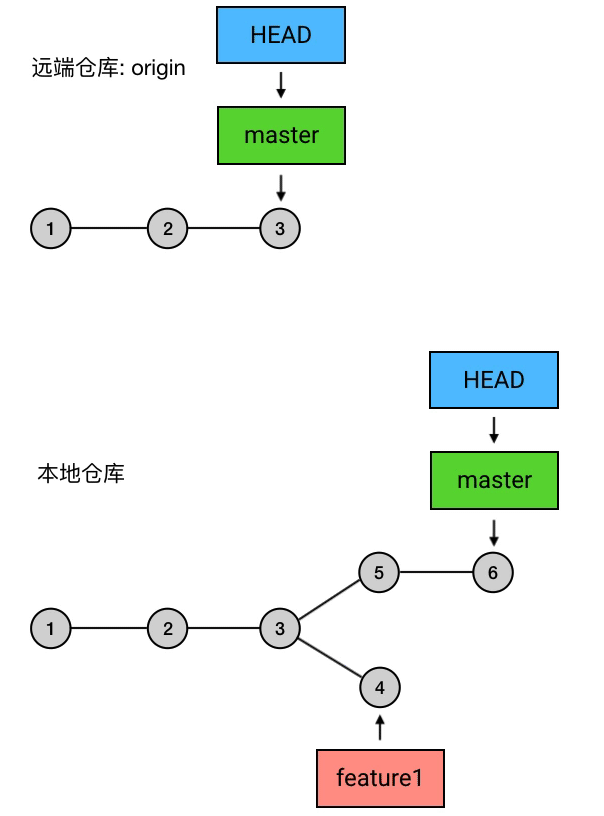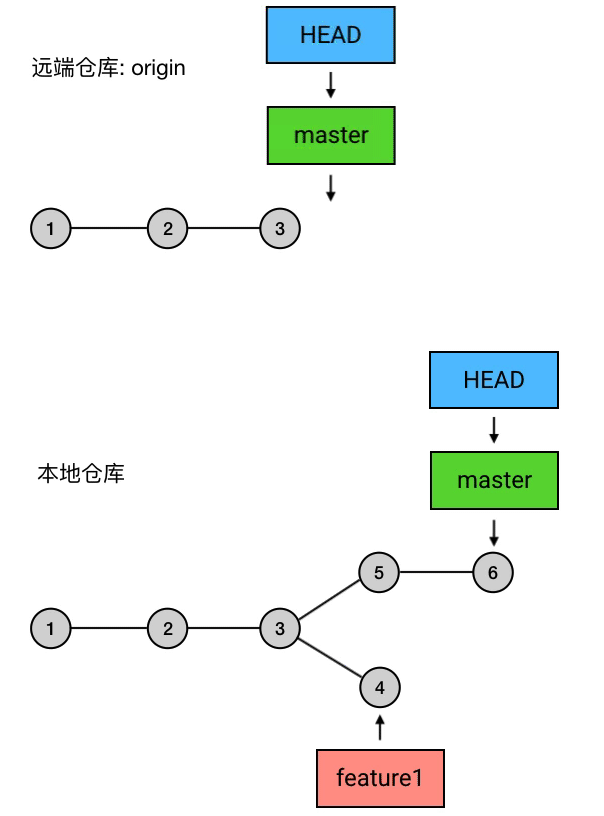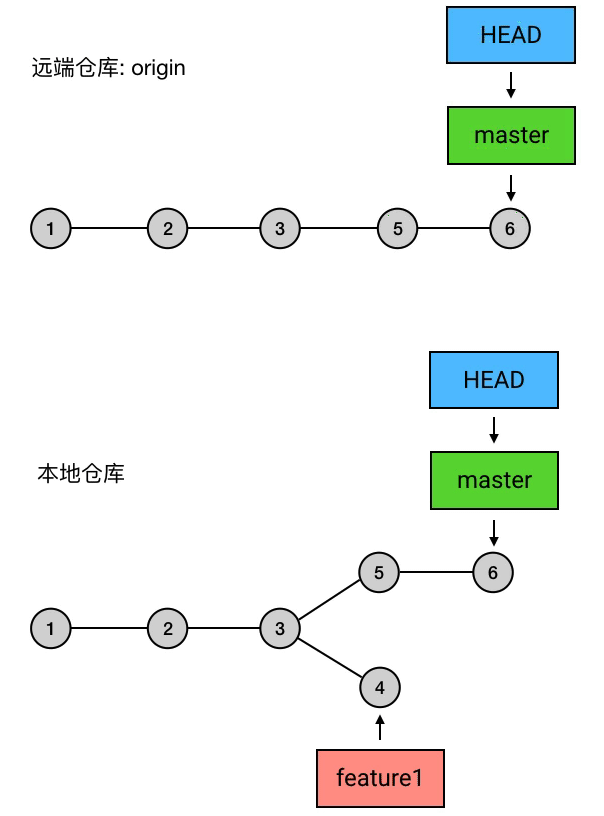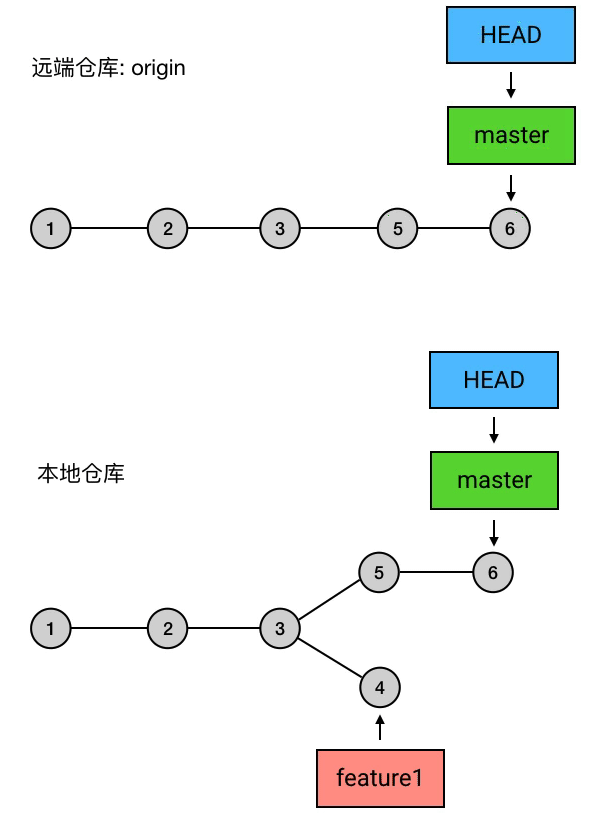
|
|
这里的 git push 和之前有点不同:多了 origin feature1 这两个参数。其中 origin 是远程仓库的别名,是你在 git clone 的时候 Git 自动帮你起的;feature1 是远程仓库中目标 branch 的名字。这两个参数合起来指定了你要 push 到的目标仓库和目标分支,意思是「我要 push 到 origin 这个仓库的 feature1 分支」。
在 Git 中(2.0 及它之后的版本),默认情况下,你用不加参数的 git push 只能上传那些之前从远端 clone 下来或者 pull 下来的分支,而如果需要 push 你本地的自己创建的分支,则需要手动指定目标仓库和目标分支(并且目标分支的名称必须和本地分支完全相同),就像上面这样。你也可以通过 git config 指令来设置 push.default 的值来改变 push 的行为逻辑,例如可以设置为「所有分支都可以用 git push 来直接 push,目标自动指向 origin 仓库的同名分支」(对应的 push.default 值:current)。
总结
- push 是把当前的分支上传到远程仓库,并把这个 branch 的路径上的所有 commits 也一并上传。
- push 的时候,如果当前分支是一个本地创建的分支,需要指定远程仓库名和分支名,用 git push origin branch_name 的格式,而不能只用 git push;或者可以通过 git config 修改 push.default 来改变 push 时的行为逻辑。
- push 的时候上传当前分支,并不会上传 HEAD;远程仓库的 HEAD 是永远指向默认分支(即 master)的。
进阶3:merge commits
含义和用法
merge 的意思是「合并」,它做的事也是合并:指定一个 commit,把它合并到当前的 commit 来。具体来讲,merge 做的事是: 从目标 commit 和当前 commit (即 HEAD 所指向的 commit)分叉的位置起,把目标 commit 的路径上的所有 commit 的内容一并应用到当前 commit,然后自动生成一个新的 commit。merge命令为“git merge branch1”。如下图,Git 会把 5 和 6 这两个 commit 的内容一并应用到 4 上,然后生成一个新的提交,并跳转到提交信息填写的界面,merge 操作会帮你自动地填写简要的提交信息。在提交信息修改完成后(或者你打算不修改默认的提交信息),就可以退出这个界面,然后这次 merge 就算完成了。
适用场景
- 合并分支: 当一个 branch 的开发已经完成,需要把内容合并回去时,用 merge 来进行合并。
- pull 的内部操作: 之前说过,pull 的实际操作其实是把远端仓库的内容用 fetch 取下来之后,用 merge 来合并。
特殊情况 1:冲突
为什么产生冲突
merge 在做合并的时候,是有一定的自动合并能力的:如果一个分支改了 A 文件,另一个分支改了 B 文件,那么合并后就是既改 A 也改 B,这个动作会自动完成;如果两个分支都改了同一个文件,但一个改的是第 1 行,另一个改的是第 2 行,那么合并后就是第 1 行和第 2 行都改,也是自动完成。
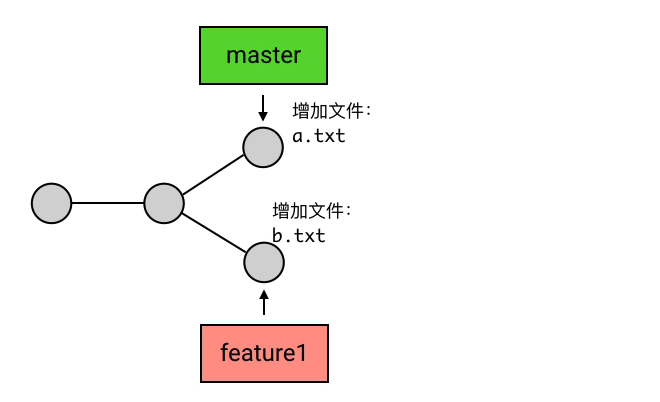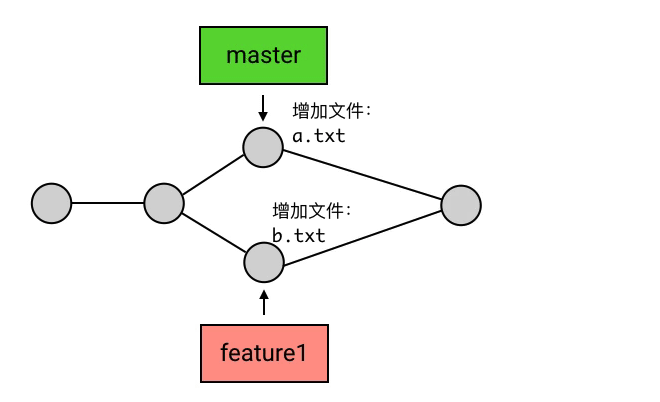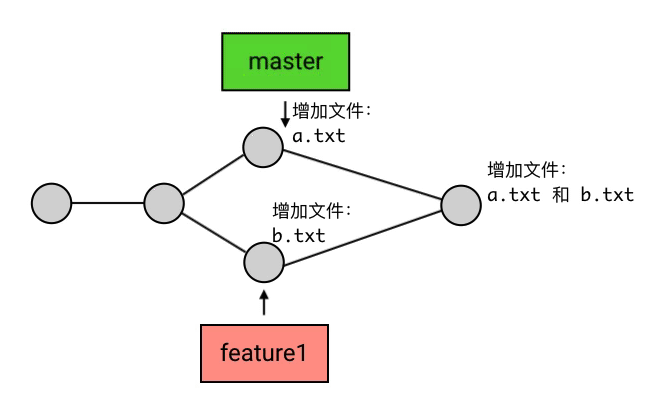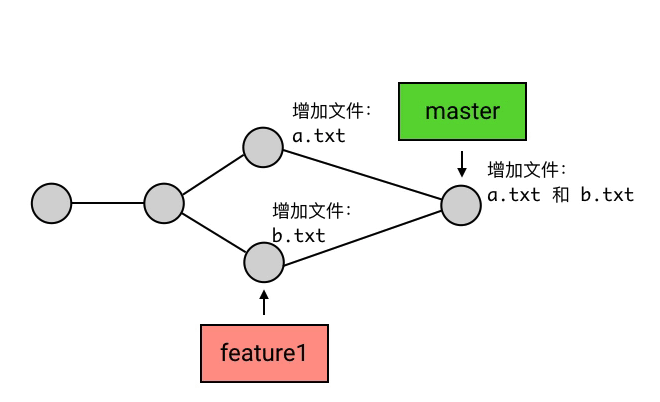
解决冲突
Git 虽然没有帮你完成自动 merge,但它对产生冲突的文件还是做了一些工作:它把两个分支冲突的内容放在了一起,并用符号标记出了它们的边界以及它们的出处。打开文件会发现文件内容标记为 HEAD 中的的内容和 feature1 中的内容。这两个内容 Git 不知道应该怎样合并,于是把它们放在一起,由你来决定。假设你决定保留 HEAD 的修改,那么只要删除掉 feature1 的修改,再把 Git 添加的那三行 «< = »> 辅助文字也删掉,保存文件退出,所谓的「解决掉冲突」就完成了。
手动提交
解决完冲突以后,就可以进行第二步—— commit 了(需要先add)。提交后可以看到,被冲突中断的 merge,在手动 commit 的时候依然会自动填写提交信息。这是因为在发生冲突后,Git 仓库处于一个「merge 冲突待解决」的中间状态,在这种状态下 commit,Git 就会自动地帮你添加「这是一个 merge commit」的提交信息。
放弃解决冲突,取消 merge?
同理,由于现在 Git 仓库处于冲突待解决的中间状态,所以如果你最终决定放弃这次 merge,也需要执行一次 merge –abort 来手动取消它:“git merge –abort”。输入这行代码,你的 Git 仓库就会回到 merge 前的状态。
特殊情况 2:HEAD 领先于目标 commit
如果 merge 时的目标 commit 和 HEAD 处的 commit 并不存在分叉,而是 HEAD 领先于目标 commit,那么 merge 就没必要再创建一个新的 commit 来进行合并操作,因为并没有什么需要合并的。在这种情况下, Git 什么也不会做,merge 是一个空操作。
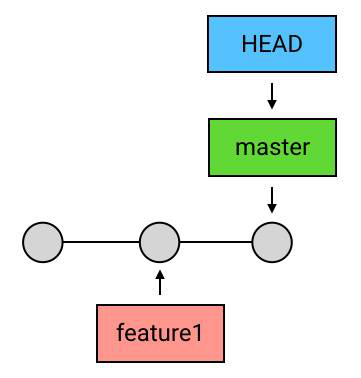
特殊情况 3:HEAD 落后于 目标 commit——fast-forward
而另一种情况:如果 HEAD 和目标 commit 依然是不存在分叉,但 HEAD 不是领先于目标 commit,而是落后于目标 commit,那么 Git 会直接把 HEAD(以及它所指向的 branch,如果有的话)移动到目标 commit。这种操作有一个专有称谓,叫做 “fast-forward”(快速前移)。
总结
- merge 的含义:从两个 commit「分叉」的位置起,把目标 commit 的内容应用到当前 commit(HEAD 所指向的 commit),并生成一个新的 commit;
- merge 的适用场景:
- 单独开发的 branch 用完了以后,合并回原先的 branch;
- git pull 的内部自动操作。
- merge 的三种特殊情况:
- 冲突:
- 原因:当前分支和目标分支修改了同一部分内容,Git 无法确定应该怎样合并;
- 应对方法:解决冲突后手动 commit。
- HEAD 领先于目标 commit:Git 什么也不做,空操作;
- HEAD 落后于目标 commit:fast-forward。
- 冲突:
进阶4:Feature Branching:最流行的工作流
简介
这种工作流的核心内容可以总结为两点:
- 任何新的功能(feature)或 bug 修复全都新建一个 branch 来写;
- branch 写完后,合并到 master,然后删掉这个 branch。
代码分享
举例说明
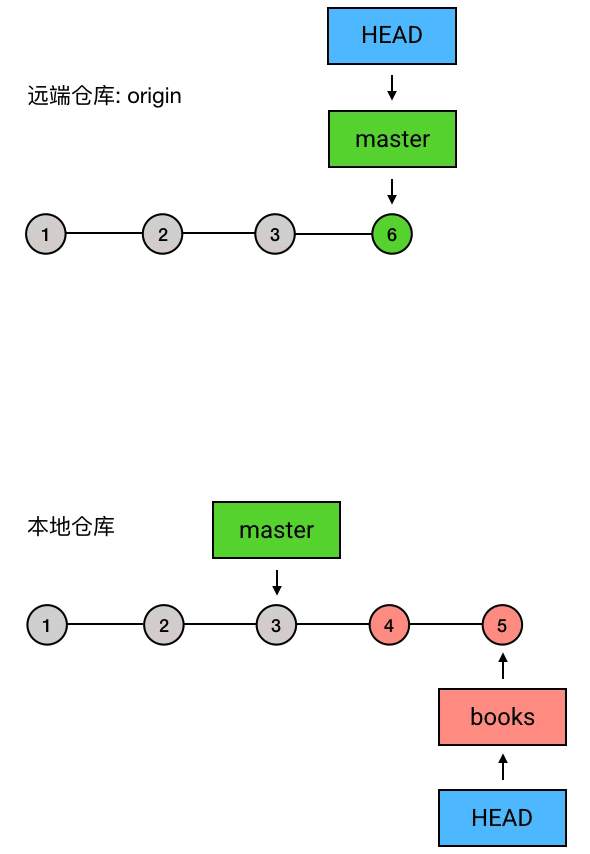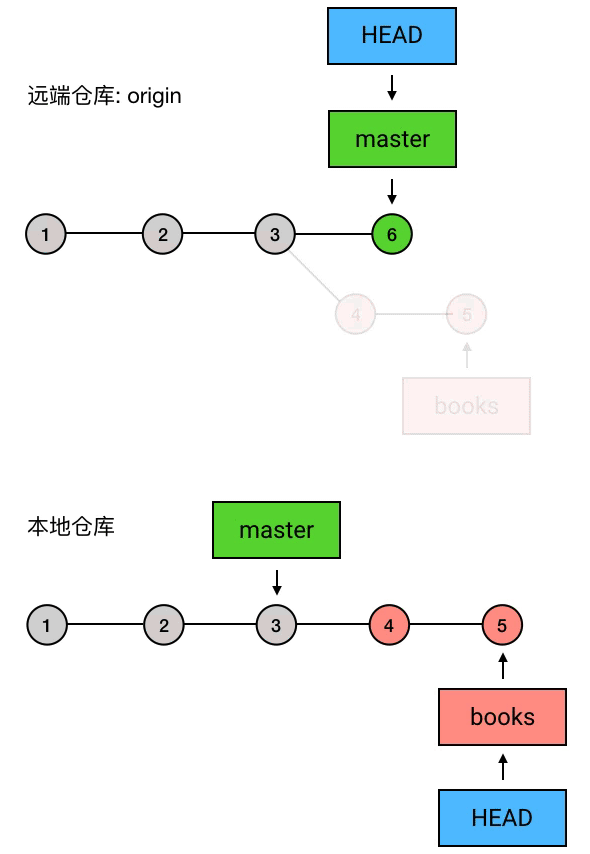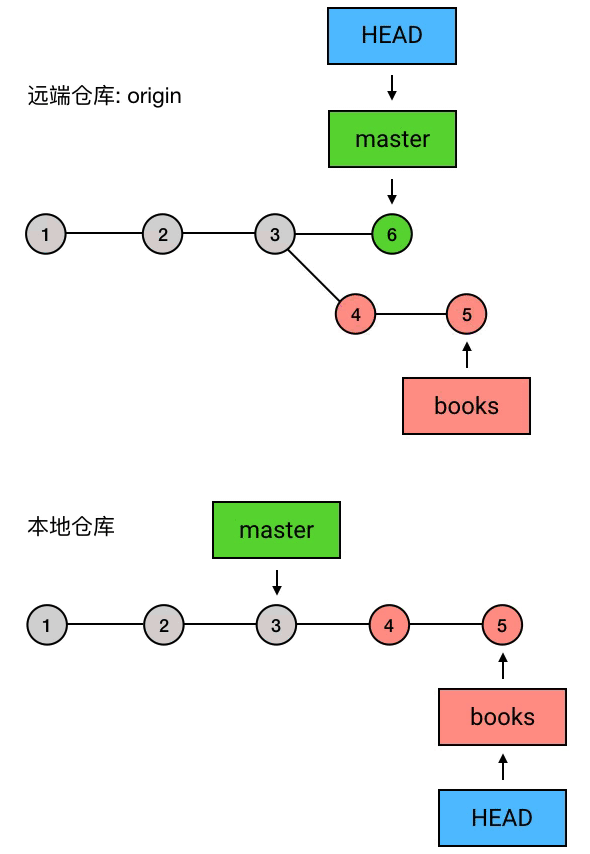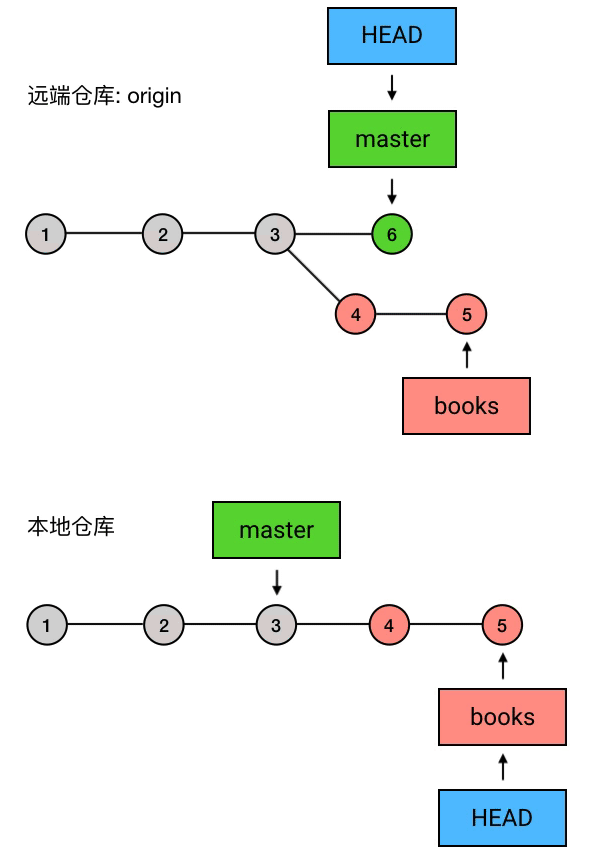
假设你在一个叫做「掘金」的团队工作,现在你要开发一个叫做「掘金小册」的功能(呵呵),于是你创建了一个新的 branch 叫做 books,然后开始在 books 上进行开发工作。
|
|
在十几个 commits 过后,「掘金小册」的基本功能开发完毕,你就把代码 push 到中央仓库(例如 GitHub)去,然后告诉同事:「嘿,小册的基本功能写完了,分支名是 books,谁有空的话帮我 review 一下吧。」
|
|
|
|
如果同事没意见
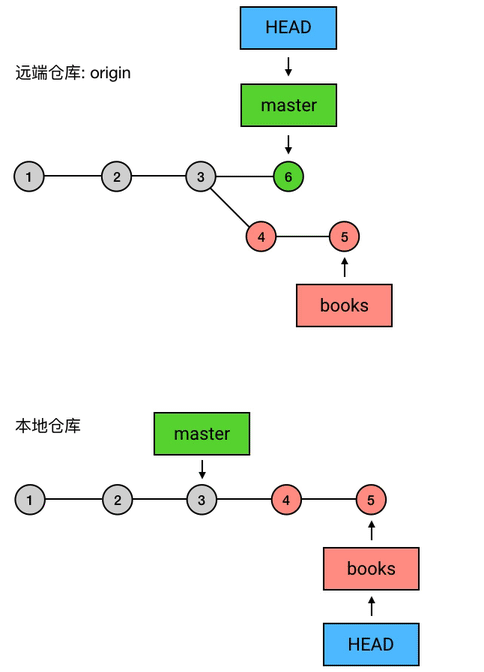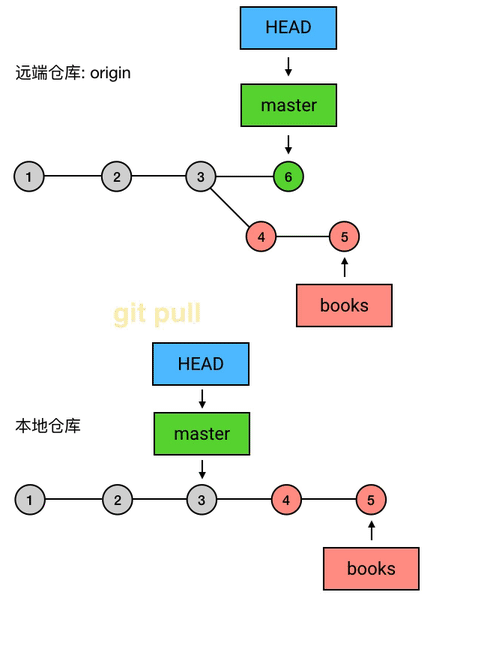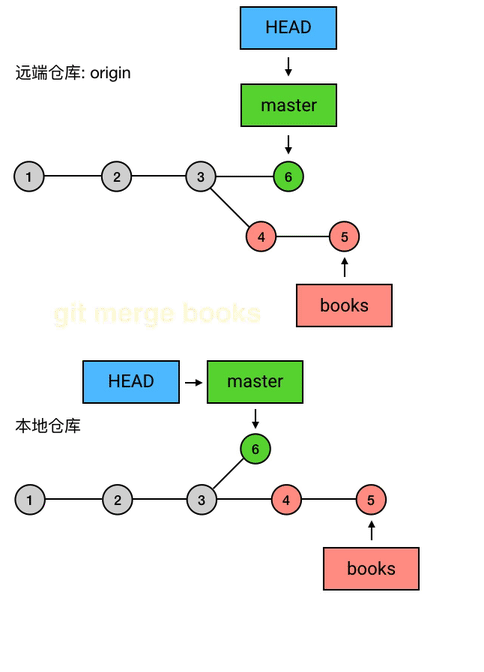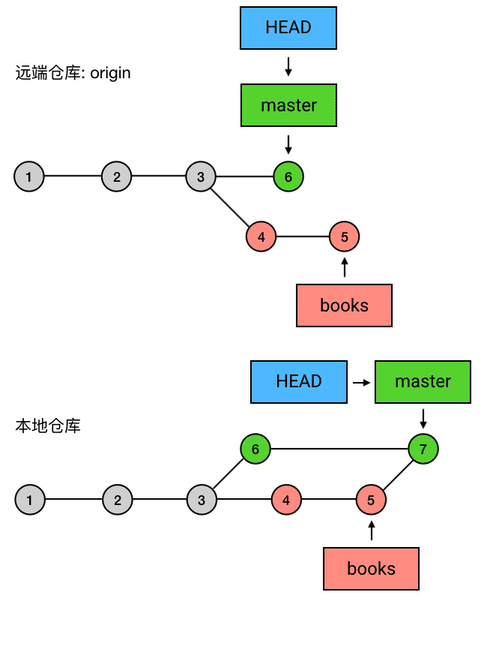
读完以后,小明对你说,嗯我看完了,我觉得不错,可以合并到 master!于是你就把 books 合并到了 master 上去。
|
|
|
|
如果同事有意见
上面讲的是小明对你的代码没有意见,而假如他在你的代码里看到了问题,例如他跑来对你说:「嘿,你的代码缩进为什么用的是 TAB?快改成空格,不然砍死你哦。」这时,你就可以把你的缩进改成空格,然后做一个新的提交,再 push 上去,然后通知他:「我改完啦!」小明 pull 下来你的新提交看了看:「嗯,这下可以合并了。」
于是你依照上面的那一套操作,把代码合并进 master,并 push 了上去,然后删掉了 books。瞧,代码在同事竖大拇指之前都不会正式发布到 master,挺方便的吧?
一人多任务
除了代码分享的便捷,基于 Feature Branch 的工作流对于一人多任务的工作需求也提供了很好的支持。
安安心心做事不被打扰,做完一件再做下一件自然是很美好的事,但现实往往不能这样。对于程序员来说,一种很常见的情况是,你正在认真写着代码,忽然同事过来跟你说:「内个……你这个功能先放一放吧,我们最新讨论出要做另一个更重要的功能,你来做一下吧。」
其实,虽然这种情况确实有点烦,但如果你是在独立的 branch 上做事,切换任务是很简单的。你只要稍微把目前未提交的代码简单收尾一下,然后做一个带有「未完成」标记的提交(例如,在提交信息里标上「TODO」),然后回到 master 去创建一个新的 branch 就好了。
|
|
如果有一天需要回来继续做这个 branch,你只要用 checkout 切回来,就可以继续了。
总结
- 每个新功能都新建一个 branch 来写。
- 写完以后,把代码分享给同事看;写的过程中,也可以分享给同事讨论。
- 分支确定可以合并后,把分支合并到 master ,并删除分支。
进阶5:关于 add
add .
add 指令除了 git add 文件名 这种用法外,还可以使用 add . 来直接把工作目录下的所有改动全部放进暂存。这个用法没什么特别的好处,但就俩个字:方便,不过要注意不要误添加其他文件,不想添加到仓库的要使用.gitignore文件。
add 添加文件改动,而非文件名
假如你修改了文件 a.txt,然后把它 add 进了暂存区,然后你又往 a.txt 里写了几行东西。这时候你再 status 一下的话,会发现你的 a.txt 既在 “Changes to be commited” 的暂存区,又在 “Changes not staged for commit”。不用觉得奇怪,这是因为通过 add 添加进暂存区的不是文件名,而是具体的文件改动内容。你在 add 时的改动都被添加进了暂存区,但在 add 之后的新改动并不会自动被添加进暂存区。在这时如果你提交,那么你那些新的改动是不会被提交的。
进阶6:看看我都改了什么
log -p 查看详细历史
-p 是 –patch 的缩写,通过 -p 参数,你可以看到具体每个 commit 的改动细节,log -p 可以看到每一个 commit 的每一行改动,所以很适合用于代码 review。
log –stat 查看简要统计
如果你只想大致看一下改动内容,但并不想深入每一行的细节(例如你想回顾一下自己是在哪个 commit 中修改了 games.txt 文件),那么可以把选项换成 –stat。
show 查看具体的 commit
如果你想看某个具体的 commit 的改动内容,可以用 show。
-
看当前 commit:直接输入“git show”
-
看任意一个 commit:在 show 后面加上这个 commit 的引用(branch 或 HEAD 标记)或它的 SHA-1 码“git show 5e68b0d8”。
-
看指定 commit 中的指定文件:在 commit 的引用或 SHA-1 后输入文件名”git show 5e68b0d8 shopping\ list.txt“
-
看未提交的内容:如果你想看未提交的内容,可以用 diff。
-
比对暂存区和上一条提交:使用 git diff –staged 可以显示暂存区和上一条提交之间的不同。换句话说,这条指令可以让你看到「如果你立即输入 git commit,你将会提交什么」”git diff –staged/–cached“。
-
比对工作目录和暂存区:使用 git diff (不加选项参数)可以显示工作目录和暂存区之间的不同。换句话说,这条指令可以让你看到「如果你现在把所有文件都 add,你会向暂存区中增加哪些内容」“git diff”。
-
比对工作目录和上一条提交:使用 git diff HEAD 可以显示工作目录和上一条提交之间的不同,它是上面这二者的内容相加。换句话说,这条指令可以让你看到「如果你现在把所有文件都 add 然后 git commit,你将会提交什么」不过需要注意,没有被 Git 记录在案的文件(即从来没有被 add 过 的文件,untracked files 并不会显示出来。)”git diff HEAD“(也可以换为其他commit)
总结
- 查看历史中的多个 commit: git log
- 查看详细改动: git log -p
- 查看大致改动:git log –stat
- 查看具体某个 commit:show
- 要看最新 commit ,直接输入 git show ;要看指定 commit ,输入 git show commit的引用或SHA-1
- 如果还要指定文件,在 git show 的最后加上文件名
- 查看未提交的内容:diff
- 查看暂存区和上一条 commit 的区别:git diff –staged(或 –cached)
- 查看工作目录和暂存区的区别:git diff 不加选项参数
- 查看工作目录和上一条 commit 的区别:git diff HEAD
高级1:不喜欢 merge 的分叉?用 rebase 吧
rebase——在新位置重新提交
rebase ,又是一个中国人看不懂的词。这个词的意思,你如果查一下的话是“变基”。(哈?玩个 Git 就弯了?)其实这个翻译还是比较准确的。rebase 的意思是,给你的 commit 序列重新设置基础点(也就是父 commit)。展开来说就是,把你指定的 commit 以及它所在的 commit 串,以指定的目标 commit 为基础,依次重新提交一次。
|
|
|
|
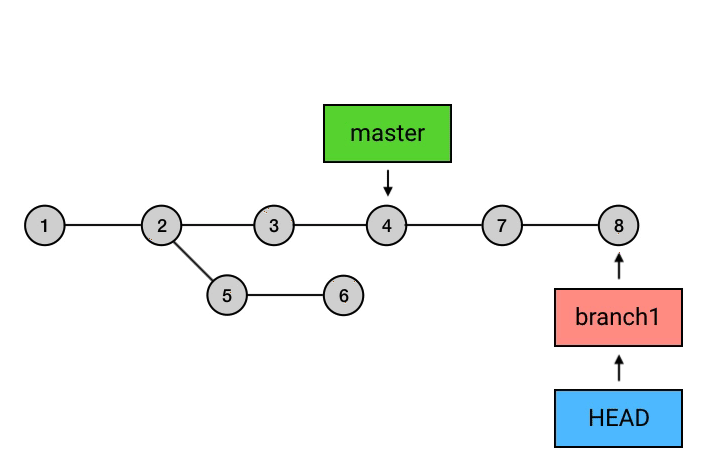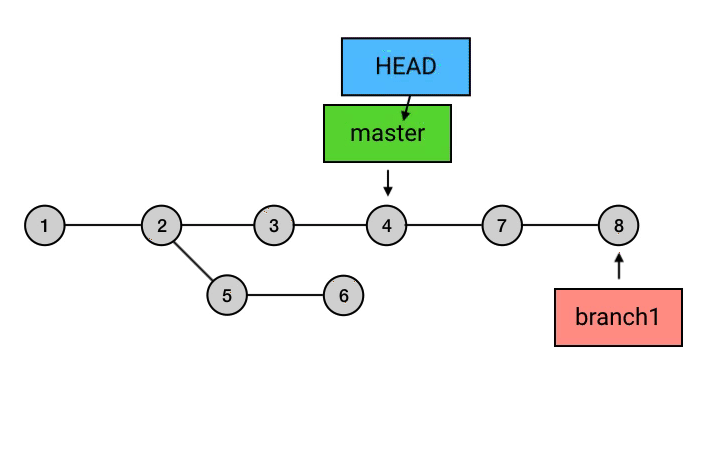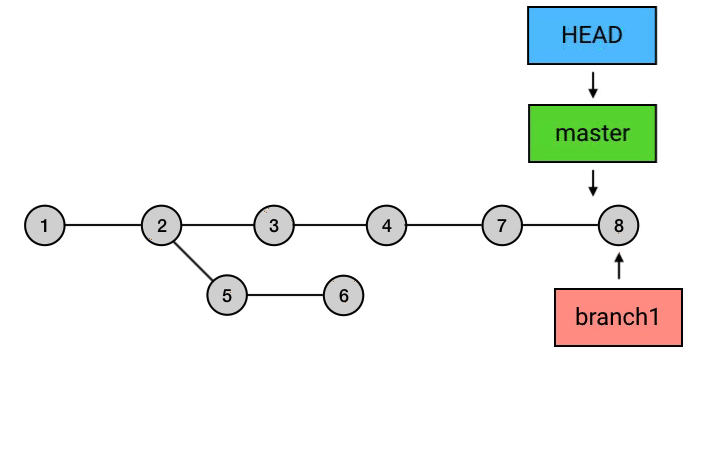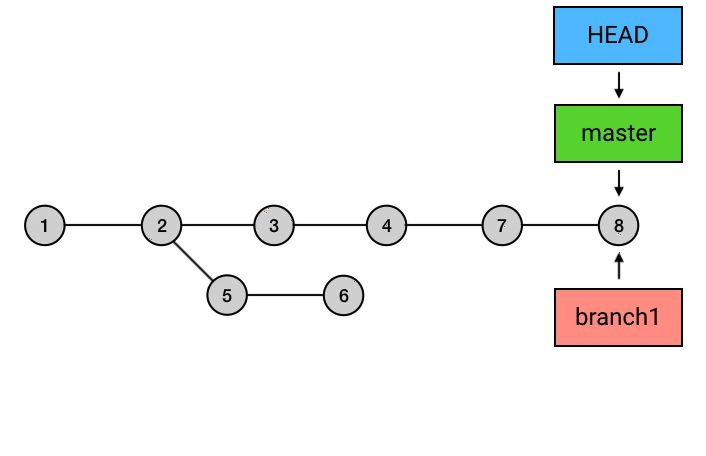
为什么要从 branch1 来 rebase,然后再切回 master 再 merge 一下这么麻烦,而不是直接在 master 上执行 rebase?从图中可以看出,rebase 后的 commit 虽然内容和 rebase 之前相同,但它们已经是不同的 commits 了。如果直接从 master 执行 rebase 的话,就会是下面这样:
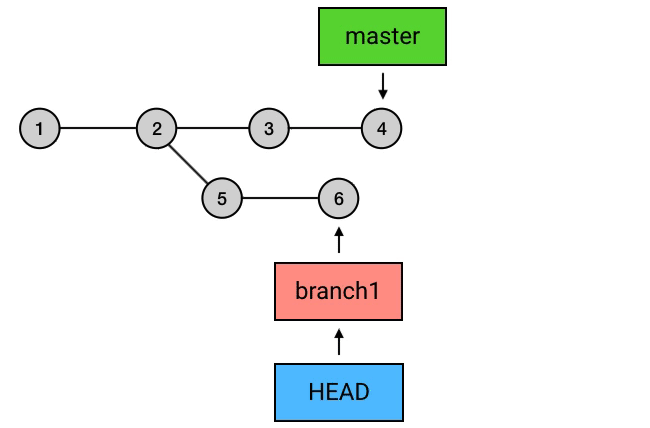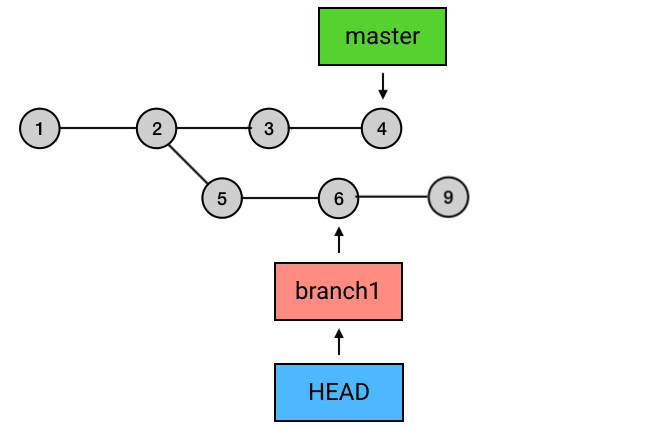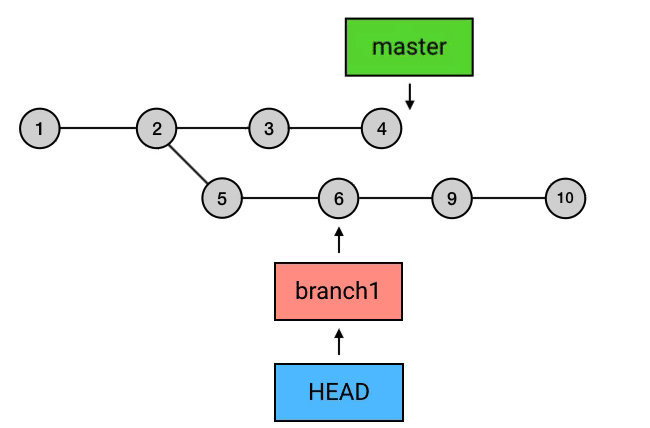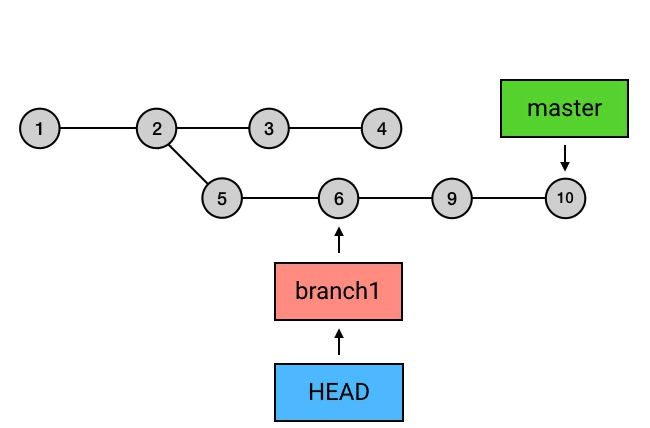
总结
本节介绍的是 rebase 指令,它可以改变 commit 序列的基础点。它的使用方式很简单:
|
|
需要说明的是,rebase 是站在需要被 rebase 的 commit 上进行操作,这点和 merge 是不同的。
高级2:刚刚提交的代码,发现写错了怎么办?
刚提交了一个代码,发现有几个字写错了,怎么修复?当场再写一个修复这几个错别字的 commit?可以是可以,不过还有一个更加优雅和简单的解决方法:commit -—amend。
“amend” 是「修正」的意思。在提交时,如果加上 –amend 参数,Git 不会在当前 commit 上增加 commit,而是会把当前 commit 里的内容和暂存区(stageing area)里的内容合并起来后创建一个新的 commit,用这个新的 commit 把当前 commit 替换掉。所以 commit –amend 做的事就是它的字面意思:对最新一条 commit 进行修正。
|
|
Git 会把你带到提交信息编辑界面。可以看到,提交信息默认是当前提交的提交信息。你可以修改或者保留它,然后保存退出。然后,你的最新 commit 就被更新了。
总结
这一节的内容只有一点:用 commit –amend 可以修复当前提交的错误。使用方式:
|
|
需要注意的有一点:commit –amend 并不是直接修改原 commit 的内容,而是生成一条新的 commit。
高级3:写错的不是最新的提交,而是倒数第二个?
rebase -i:交互式 rebase
如果不是最新的 commit 写错,就不能用 commit –amend 来修复了,而是要用 rebase。不过需要给 rebase 也加一个参数:-i。
rebase -i 是 rebase –interactive 的缩写形式,意为「交互式 rebase」。所谓「交互式 rebase」,就是在 rebase 的操作执行之前,你可以指定要 rebase 的 commit 链中的每一个 commit 是否需要进一步修改。那么你就可以利用这个特点,进行一次「原地 rebase」。
例如你是在写错了 commit 之后,又提交了一次才发现之前写错了。
开启交互式 rebase 过程
现在再用 commit –amend 已经晚了,但可以用 rebase -i:
|
|
补充说明:在 Git 中,有两个「偏移符号」: ^ 和 ~。
- ^ 的用法:在 commit 的后面加一个或多个 ^ 号,可以把 commit 往回偏移,偏移的数量是 ^ 的数量。例如:master^ 表示 master 指向的 commit 之前的那个 commit; HEAD^^ 表示 HEAD 所指向的 commit 往前数两个 commit。
- ~ 的用法:在 commit 的后面加上 ~ 号和一个数,可以把 commit 往回偏移,偏移的数量是 ~ 号后面的数。例如:HEAD~5 表示 HEAD 指向的 commit往前数 5 个 commit。
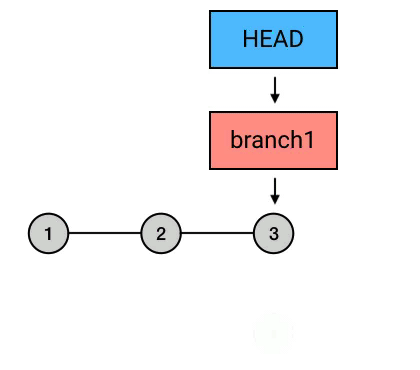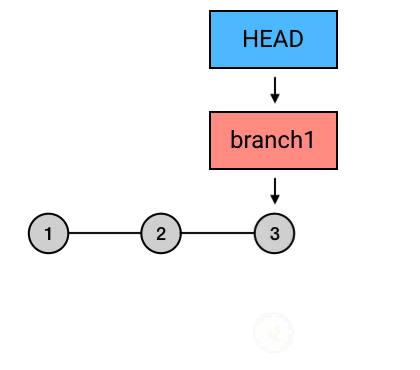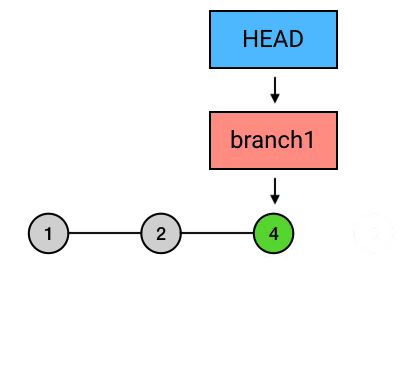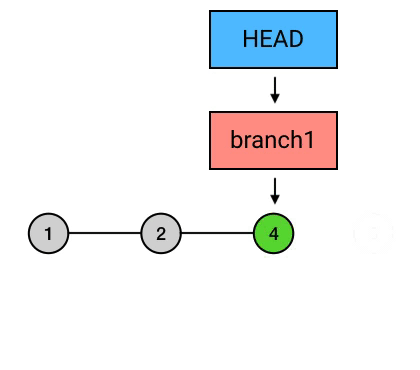
上面这行代码表示,把当前 commit ( HEAD 所指向的 commit) rebase 到 HEAD 之前 2 个的 commit 上:
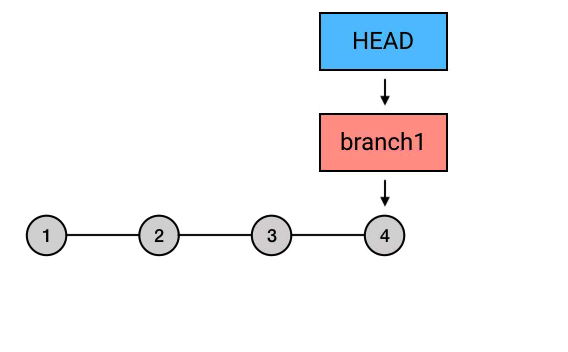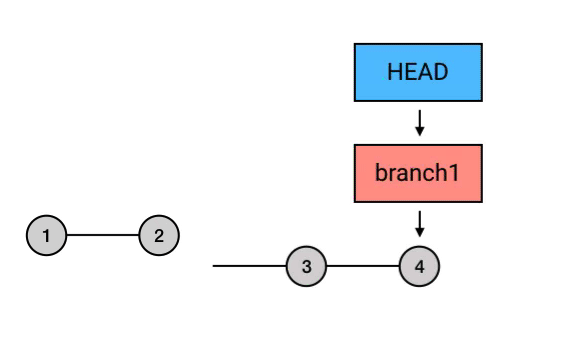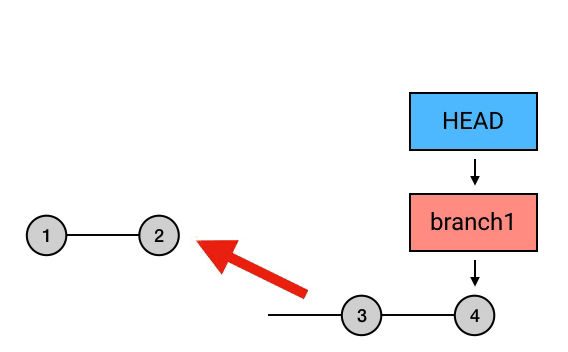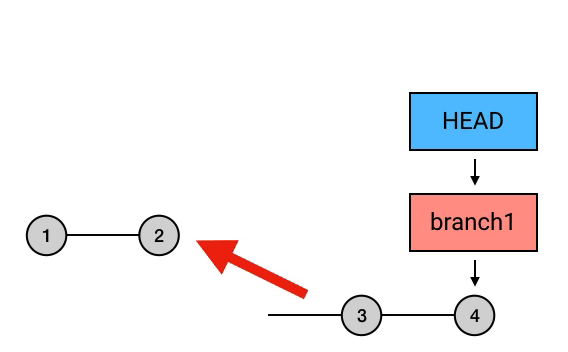
如果没有 -i 参数的话,这种「原地 rebase」相当于空操作,会直接结束。而在加了 -i 后,就会跳到一个编辑界面。
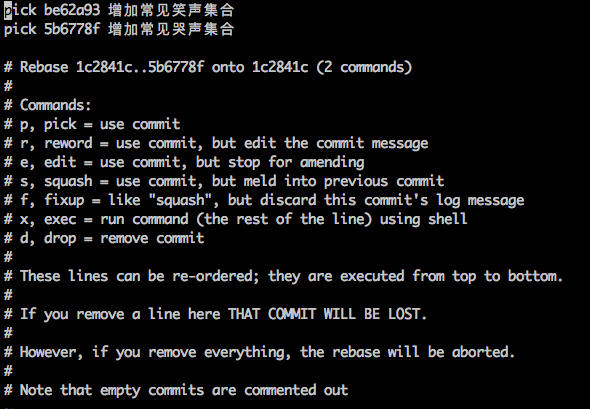
编辑界面:选择 commit 和对应的操作
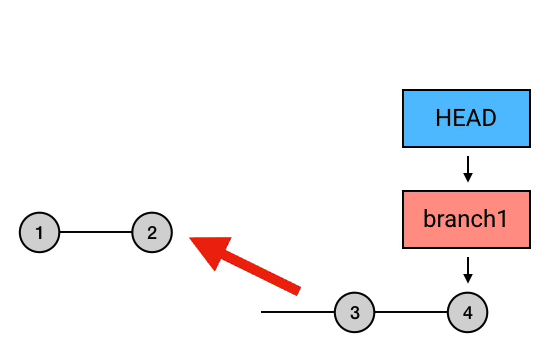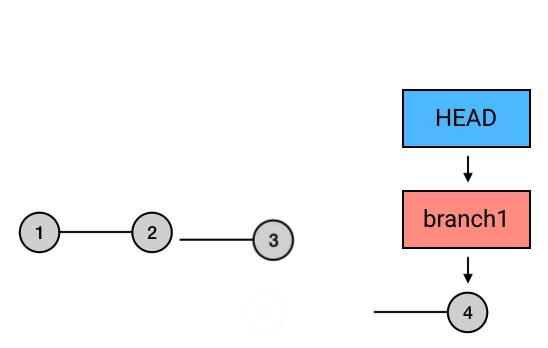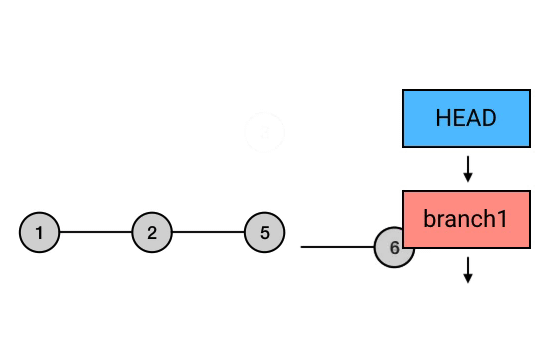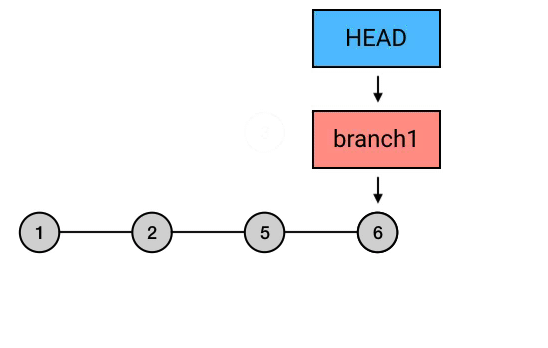
这个编辑界面的最顶部,列出了将要「被 rebase」的所有 commits,也就是倒数第二个 commit 「增加常见笑声集合」和最新的 commit「增加常见哭声集合」。需要注意,这个排列是正序的,旧的 commit 会排在上面,新的排在下面。
这两行指示了两个信息: 需要处理哪些 commits; 怎么处理它们。
你需要修改这两行的内容来指定你需要的操作。每个 commit 默认的操作都是 pick (从图中也可以看出),表示「直接应用这个 commit」。所以如果你现在直接退出编辑界面,那么结果仍然是空操作。但你的目标是修改倒数第二个 commit,也就是上面的那个「增加常见笑声集合」,所以你需要把它的操作指令从 pick 改成 edit 。 edit 的意思是「应用这个 commit,然后停下来等待继续修正」。把 pick 修改成 edit 后,就可以退出编辑界面了。
修改写错的 commit
修改完成之后,和上节里的方法一样,用 commit –amend 来把修正应用到当前最新的 commit:
|
|
继续 rebase 过程
在修复完成之后,就可以用 rebase –continue 来继续 rebase 过程,把后面的 commit 直接应用上去。然后,这次交互式 rebase 的过程就完美结束了,你的那个倒数第二个写错的 commit 就也被修正了.
|
|
总结
- 使用方式是 git rebase -i 目标commit;
- 在编辑界面中指定需要操作的 commits 以及操作类型;
- 操作完成之后用 git rebase –continue 来继续 rebase 过程。
高级4:比错还错,想直接丢弃刚写的提交?
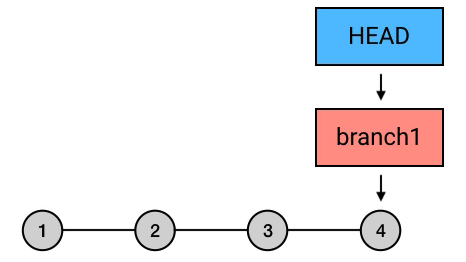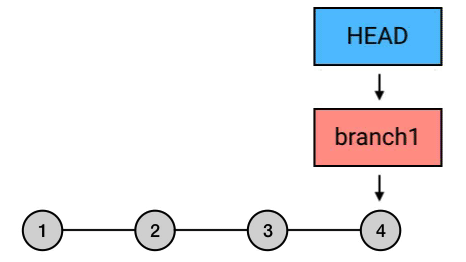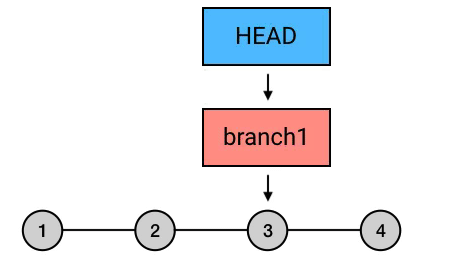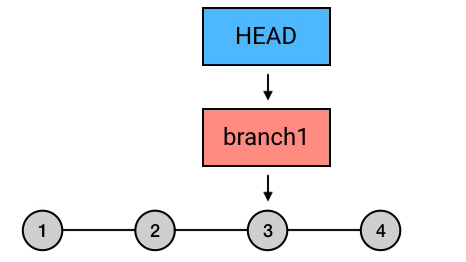
有的时候,刚写完的 commit 写得实在太烂,连自己的都看不下去,与其修改它还不如丢掉重写。这种情况,就可以用 reset 来丢弃最新的提交。
reset –hard 丢弃最新的提交
比如你刚写了一个 commit,写完回头看了看,你觉得「不行这得重新写」。那么你可以用 reset –hard 来撤销这条 commit(HEAD 表示 HEAD^ 往回数一个位置的 commit)。HEAD^ 表示你要恢复到哪个 commit。因为你要撤销最新的一个 commit,所以你需要恢复到它的父 commit ,也就是 HEAD^。那么在这行之后,你的最新一条就被撤销了
|
|
总结
这一节的内容是撤销最新的提交,方式是通过 reset –hard:
|
|
高级5:想丢弃的也不是最新的提交?
还没看懂。
高级6:代码已经 push 上去了才发现写错?
有的时候,代码 push 到了中央仓库,才发现有个 commit 写错了。这种问题的处理分两种情况:
出错的内容在你自己的 branch
假如是某个你自己独立开发的 branch 出错了,不会影响到其他人,那没关系用前面几节讲的方法把写错的 commit 修改或者删除掉,然后再 push 上去就好了。不过由于你在本地对已有的 commit 做了修改,这时你再 push 就会失败,因为中央仓库包含本地没有的 commits。但这个和前面讲过的情况不同,这次的冲突不是因为同事 push 了新的提交,而是因为你刻意修改了一些内容,这个冲突是你预料到的,你本来就希望用本地的内容覆盖掉中央仓库的内容。那么这时就不要乖乖听话,按照提示去先 pull 一下再 push 了,而是要选择「强行」push(-f 是 –force 的缩写,意为「忽略冲突,强制 push」):
|
|
这样,在本地修改了错误的 commits,然后强制 push 上去,问题就解决了。
出错的内容已经合并到 master
这就不能用上面那招了。同事的工作都在 master 上,你永远不知道你的一次强制 push 会不会洗掉同事刚发上去的新提交。所以除非你是人员数量和行为都完全可控的超小团队,可以和同事做到无死角的完美沟通,不然一定别在 master 上强制 push。
在这种时候,你只能退一步,选用另一种策略:增加一个新的提交,把之前提交的内容抹掉。例如之前你增加了一行代码,你希望撤销它,那么你就做一个删掉这行代码的提交;如果你删掉了一行代码,你希望撤销它,那么你就做一个把这行代码还原回来的提交。这种事做起来也不算麻烦,因为 Git 有一个对应的指令:revert。
它的用法很简单,你希望撤销哪个 commit,就把它填在后面:
|
|
上面这行代码就会增加一条新的 commit,它的内容和倒数第二个 commit 是相反的,从而和倒数第二个 commit 相互抵消,达到撤销的效果。
在 revert 完成之后,把新的 commit 再 push 上去,这个 commit 的内容就被撤销了。它和前面所介绍的撤销方式相比,最主要的区别是,这次改动只是被「反转」了,并没有在历史中消失掉,你的历史中会存在两条 commit :一个原始 commit ,一个对它的反转 commit。
总结
这节的内容是讲当错误的 commit 已经被 push 上去时的解决方案。具体的方案有两类:
- 如果出错内容在私有 branch:在本地把内容修正后,强制 push (push -f)一次就可以解决;
- 如果出错内容在 master:不要强制 push,而要用 revert 把写错的 commit 撤销。
高级7:reset 的本质–不止可以撤销提交
待补充
高级8:checkout 的本质
介绍
在前面的 branch 的部分,我说到 checkout 可以用来切换 branch。不过实质上,checkout 并不止可以切换 branch。checkout 本质上的功能其实是:签出( checkout )指定的 commit。
git checkout branch名 的本质,其实是把 HEAD 指向指定的 branch,然后签出这个 branch 所对应的 commit 的工作目录。所以同样的,checkout 的目标也可以不是 branch,而直接指定某个 commit:
|
|
另外,如果你留心的话可能会发现,在 git status 的提示语中,Git 会告诉你可以用 checkout – 文件名 的格式,通过「签出」的方式来撤销指定文件的修改。
总结
这节的内容是对 checkout 的本质进行简述:checkout 的本质是签出指定的 commit,所以你不止可以切换 branch,也可以直接指定 commit 作为参数,来把 HEAD 移动到指定的 commit。
checkout 和 reset 的不同
checkout 和 reset 都可以切换 HEAD 的位置,它们除了有许多细节的差异外,最大的区别在于:reset 在移动 HEAD 时会带着它所指向的 branch 一起移动,而 checkout 不会。当你用 checkout 指向其他地方的时候,HEAD 和 它所指向的 branch 就自动脱离了。
高级9:紧急情况:「立即给我打个包,现在马上!」
介绍
前面在讲 branch 的时候讲到,利用 branch 可以实现一人多任务的需求,从而可以轻松应对「嘿,这个先别做了,给你个新活」的情况。但有时,尤其是在互联网公司,你可能会遇到比这更紧急的情况:你正对着电脑发呆,忽然见到一个同事屁股着着火就跑来找你了:「快快快,立即给我打个包,现在马上,拜托拜托!」
这种情况和「这个 branch 先放放吧」不同,你没时间、也没必要当场慌慌张张把文件的所有改动做个临时的 commit 然后去救同事的火,救完火再重新把 commit 撤销回来。这时候你只要先把所有文件一股脑扔在一边就可以去给同事打包了,打完包再把刚才扔到一边的文件重新取过来就好。
这一「扔」一「取」,用的是 Git 的 stash 指令。
stash:临时存放工作目录的改动
“stash” 这个词,和它意思比较接近的中文翻译是「藏匿」,是「把东西放在一个秘密的地方以备未来使用」的意思。在 Git 中,stash 指令可以帮你把工作目录的内容全部放在你本地的一个独立的地方,它不会被提交,也不会被删除,你把东西放起来之后就可以去做你的临时工作了,做完以后再来取走,就可以继续之前手头的事了。具体说来,stash 的用法很简单。当你手头有一件临时工作要做,需要把工作目录暂时清理干净,那么你可以”git stash“。
就这么简单,你的工作目录的改动就被清空了,所有改动都被存了起来。然后你就可以从你当前的工作分支切到 master 去给你的同事打包了打完包,切回你的分支,然后”git stash pop“。你之前存储的东西就都回来了。很方便吧?
注意:没有被 track 的文件(即从来没有被 add 过的文件不会被 stash 起来,因为 Git 会忽略它们。如果想把这些文件也一起 stash,可以加上 `-u` 参数,它是 `–include-untracked` 的简写。就像这样”git stash -u
“。
高级10:branch 删过了才想起来有用?
branch 用完就删是好习惯,但有的时候,不小心手残删了一个还有用的 branch ,或者把一个 branch 删掉了才想起来它还有用,怎么办?
reflog :引用的 log
reflog 是 “reference log” 的缩写,使用它可以查看 Git 仓库中的引用的移动记录。如果不指定引用,它会显示 HEAD 的移动记录。假如你误删了 branch1 这个 branch,那么你可以查看一下 HEAD 的移动历史”git reflog“。从移动历史中可以看出 HEAD 的最后一次移动行为是「从 branch1 移动到 master」。而在这之后,branch1 就被删除了。所以它之前的那个 commit 就是 branch1 被删除之前的位置了,也就是第二行的 c08de9a。所以现在就可以切换回 c08de9a,然后重新创建 branch1。
|
|
这样,你刚删除的 branch1 就找回来了。
注意:不再被引用直接或间接指向的 commits 会在一定时间后被 Git 回收,所以使用 reflog 来找回删除的 branch 的操作一定要及时,不然有可能会由于 commit 被回收而再也找不回来。
查看其他引用的 reflog
reflog 默认查看 HEAD 的移动历史,除此之外,也可以手动加上名称来查看其他引用的移动历史,例如某个 branch ”git reflog master“。
额外说点:.gitignore——排除不想被管理的文件和目录
在 Git 中有一个特殊的文本文件:.gitignore。这个文本文件记录了所有你希望被 Git 忽略的目录和文件。
如果你是在 GitHub 上创建仓库,你可以在创建仓库的界面中就通过选项来让 GitHub 帮你创建好一个符合项目类型的 .gitignore 文件,你就不用再自己麻烦去写一大堆的配置了。不过如果你不是在 GitHub 上创建的项目,或者你对 GitHub 帮你创建的 .gitignore 文件有一些额外的补充,那么你可以自己来编辑这个文件。
.gitignore大概长这样(#是注释内容,*是通配符):
# ignore file type1
*.o
*.elf
tmp.s
# ignore file type2
bin/
gen/
out/file1/
总结
写给读者
Git 内容非常多,这本小册我已经尽量克制,可是还是写了二十多节出来。尽管这样,有些很有用的内容我依然没有写出来。因为我写这本小册的目的是解决大部分人「学不会 Git」和「用了很久却总用不好 Git」这两个问题,所以我在这本小册里重点讲的也是 Git 的学习和使用中那些既重要又困难的关键点。
如果你在整个阅读过程中是边读边练的,相信读到这里,你对 Git 已经有一个较为全面和深刻的认识了。接下来你只要在平时使用 Git 的过程中多留心一些,找机会把这本小册中的内容应用在实战,很快就可以成为众人眼中的「Git 高手」了。当然,到时候你也许也会发现,其实大家眼中的「Git 高手」远没有那么神秘,并不一定比别人懂很多,只是更加了解 Git 的工作原理和一些关键概念罢了。
几个「不难但却很有用」的 Git 技能点
除了这本小册里讲到的那些「关键点」,还有些 Git 的相关知识虽然也比较有用,但属于稍微研究一下就可以学会的内容,我就不讲了,只在这里做一个简单的列举,你在平时使用 Git 的时候记得抽空学习一下就好。
- tag:不可移动的 branch。tag 是一个和 branch 非常相似的概念,它和 branch 最大的区别是:tag 不能移动。所以在很多团队中,tag 被用来在关键版本处打标记用。
- cherry-pick:把选中的 commits 一个个合并进来。cherry-pick 是一种特殊的合并操作,使用它可以点选一批 commits,按序合并。
- git config: Git 的设置。git config 可以对 Git 做出基础设置,例如用户名、用户邮箱,以及界面的展示形式。内容虽然多,但都不难,整体看一遍,把 Git 设置成你最舒服的样子,从此就再也不用管它了。属于「一次付出,终身受用」的高性价比内容。
- Git Flow:复杂又高效的工作流。除了前面讲到的 “Feature Branching”,还有一个也很流行的工作流:Git Flow。Git Flow 的机制非常完善,很适合大型团队的代码管理。不过由于它的概念比较复杂(虽然难度并不高),所以并不适合新手直接学习,而更适合在不断的自我研究中逐渐熟悉,或者在团队合作中慢慢掌握。基于这个原因,我最终也没有在这本小册里讲 Git Flow,但我推荐你自己在有空的时候了解一下它。
更多内容
更多内容可到Git官网查看详细文档。
文章原创,可能存在部分错误,欢迎指正,联系邮箱 cao_arvin@163.com。