本文
主要普及ARM处理器的基础知识,不涉及处理器微架构具体设计细节。
| 版本 | 说明 |
|---|---|
| 0.1 | 初版发布 |
参考
| 名称 | 作者 | 来源 |
|---|---|---|
| ARM处理器详解 | 移知 | 网络 |
专业术语与缩略语
| 缩写 | 全称 | 说明 |
|---|---|---|
| PPA | Performance Power Area | 性能、功耗、面积 |
| ISA | Instructions Set Architecture | 指令集架构 |
| CISC | Complex Instructions Set Computer | 复杂指令集计算机 |
| RISC | Reduced Instructions Set Computer | 精简指令集计算机 |
| CPI | Cycle Per Instruction | 指令平均时钟周期数 |
| BTB | Branch Target Buffer | 分支目标地址缓存 |
| BHT | Branch History Table | 分支历史记录表 |
| RAS | Return address stack | 返回地址栈 |
| TTB | Transaction Table Base | 基地址转换表 |
| VA | Virtual Address | 虚拟地址 |
| PA | Physical Address | 物理地址 |
| ASID | Address Space Identifier | 地址空间编号(标记当前进程) |
| TLB | Translation Look-aside Buffers | 映射表缓存 |
| MMU | Memory Management Unit | 内存管理单元 |
| LSQ | Load Store Queue | 访存队列 |
| AMAT | average memory access time | 平均存储访问时间,用来衡量cache性能 |
| LRU | Least Recently Used | 最久未使用替换算法 |
| CCI | Cache Coherency Interconnection | cache一致性互连 |
| CCN | Cache Coherency Network | cache一致性网络 |
| HW | Hardware | 硬件设计 |
| SW | Sortware | 软件设计 |
| SECDED | Single error correct double error detect | 单比特错误纠正双比特错误检查 |
| SIMD | Single Instruction Multi Data | 单指令多数据,向量处理指令 |
| AMP | Asymmetric Multi-Processing | 非对称的多任务处理 |
| SMP | Symmetric Multi-Processing | 对称的多任务处理 |
| SCU | Snoop Control Unit | snoop控制单元,保持cache一致性 |
| DSU | DynamIQ Shared Unit | 相当于一个wrapper,将cluster包起来 |
RISC和ARM处理器架构
处理器架构与微架构
处理器架构是一个规范,是一个指令集,这个指令集定义了处理器的基本特性和基本功能。
处理器微架构,微架构是指一款处理器执行指令集的逻辑结构。
同一个处理器架构可以由不同的处理器微架构实现。可以简单理解为架构是软件层面的指令集功能,微架构是硬件层面的逻辑实现。
Memory Wall
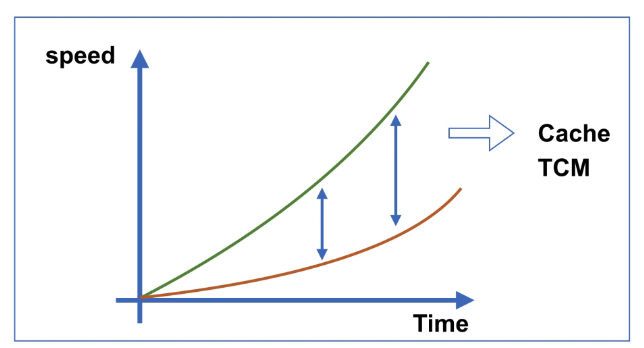
- Instructions/Seconds:x2 Every 2 Years
- Memory capacity:x2 Every 2 Years
- Memory Latenc:x1.1 Every 2 Years
处理器 PPA
- Performance:speed(IPC)、clock frequency、benchmark(dhrystone、coremark、specint2006、antutu等)
- Power:active、static、mw/w(功耗单位)
- Area:die(芯片裸片)、mm^2(面积单位)
- Power Efficiency:Performance/Power,如benchmark/Power
什么是CISC架构
- 是一种微处理器指令集架构(ISA)
- 指令集功能复杂,数量庞大
- 多用于高性能高功耗的CPU设计中,如Intel X86
- 多种指令都可以访问存储器
- 有少量寄存器
- 编译器设计简单
什么是RISC架构
- 是一种微处理器指令集架构(ISA)
- 指令集功能简单
- 多用于低功耗移动设备CPU设计中,如ARM
- 只有load/store指令可以访问存储器
- 有大量寄存器
- 编译器设计复杂
ARM架构处理器
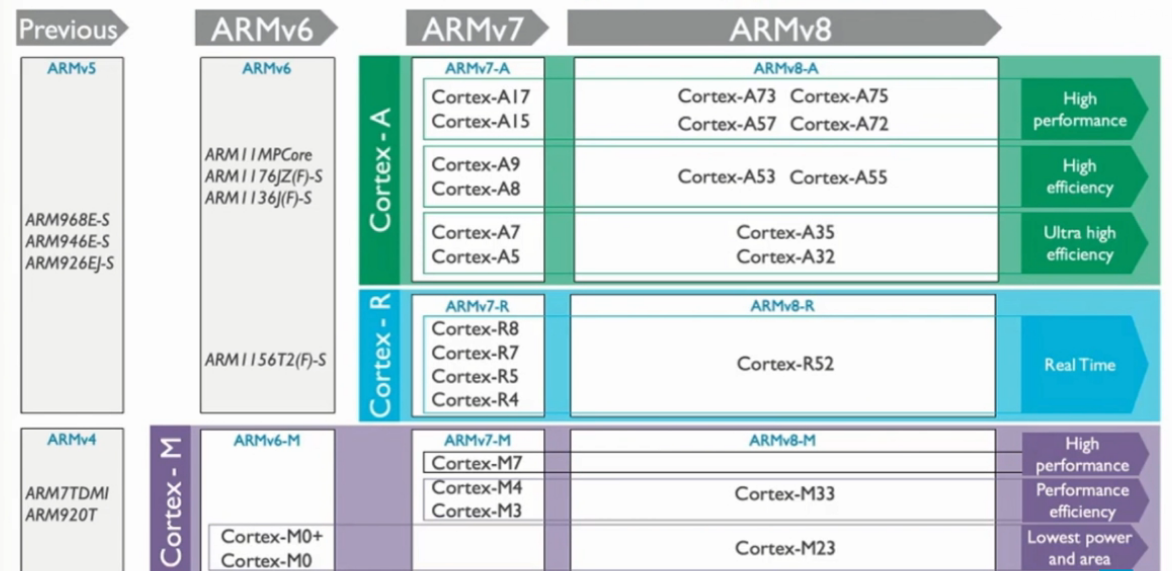

Cortex-A处理器
Cortex-R处理器
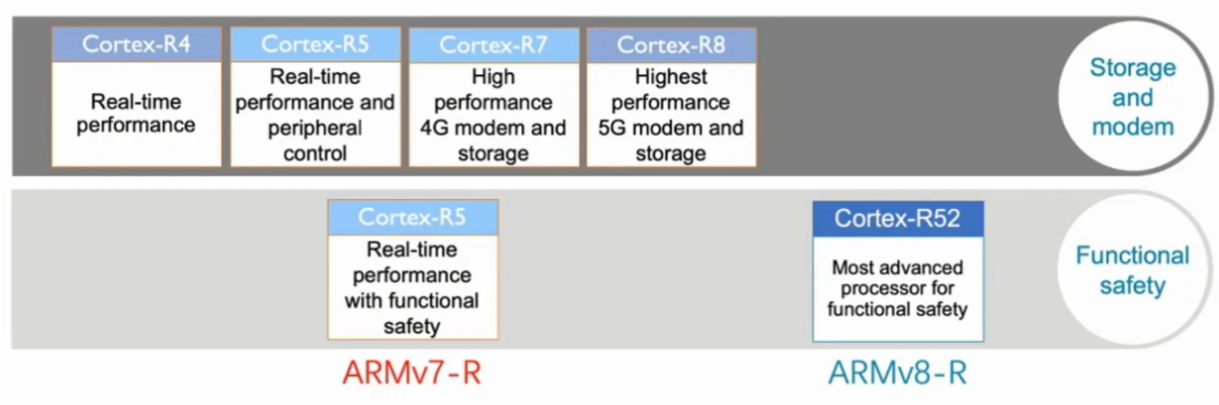
- 特点:
| Fast | High processing performance, Fast interrupt response | Scalable multi-core, Superscalar pipelines, Branch prediction |
|---|---|---|
| Realtime | Hard realtime deterministic, Meet realtime constraints | Tightly Coupled Memory, Low Latency Peripheral Ports, Fast low latency interrupt handling |
| Reliable | Dependable with safety features, High error resistance, Extended functional safety support | Memory protection and error correction, Dual core lockstep configuration, Hardware hypervisor in ARMv8-R |
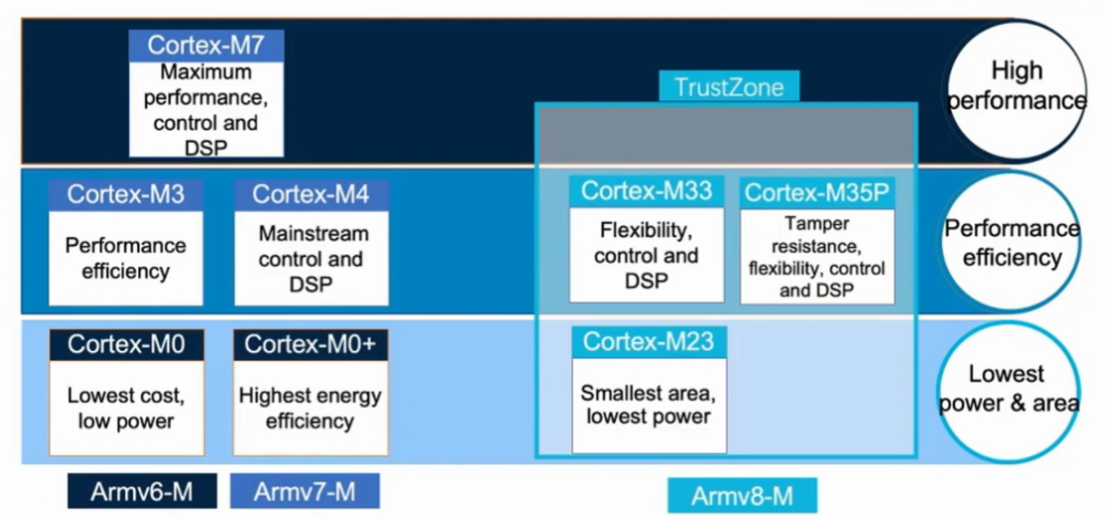
Cortex-M处理器
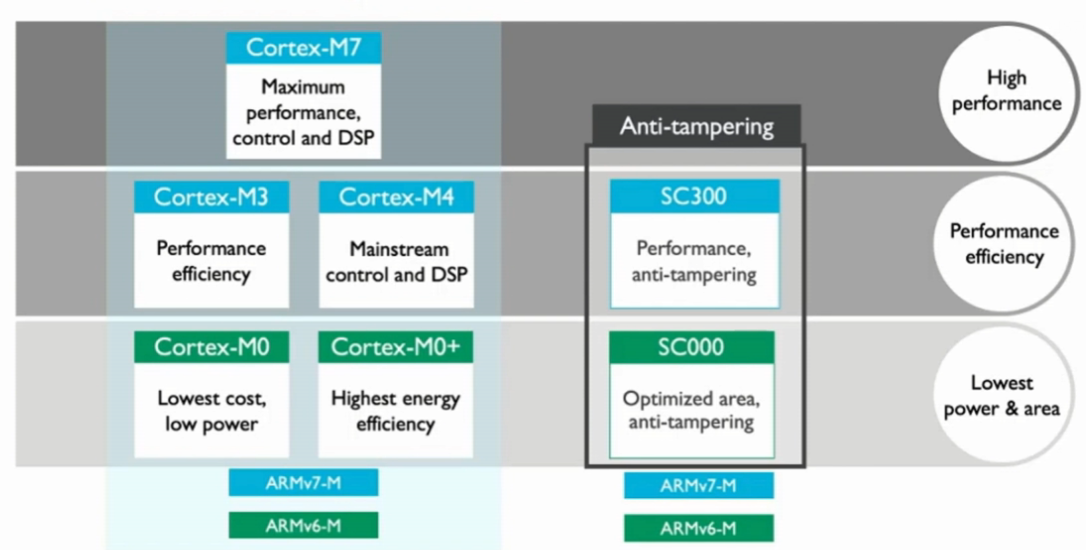
SecureCore处理器
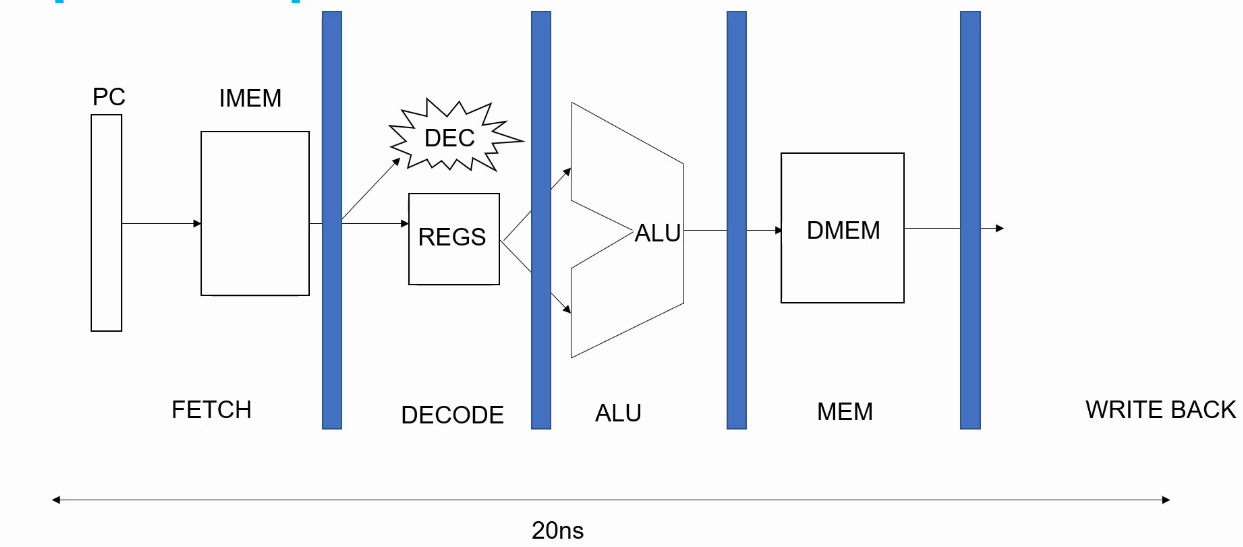
处理器流水线
流水线的结构
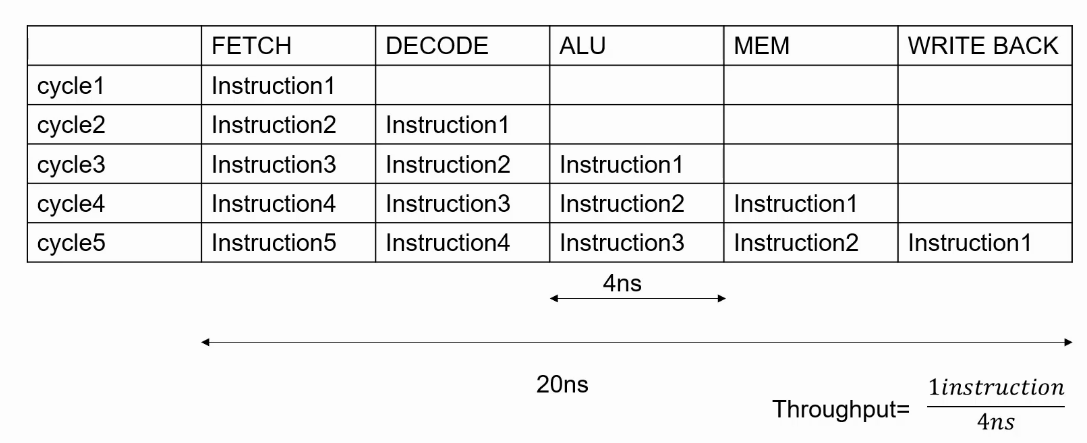
假设一个CPU没有pipeline,执行一条指令需要20ns,执行10条执行需要多长时间?若把这个CPU划分5级pipeline,且每一级pipeline时间相同,则理想情况下执行10条指令需要多长时间? 答案:20ns*10instr = 200ns,1*4ns*5cycle + 9*4ns*1cycle = 56ns
流水线的CPI
上述流水线结构中的CPI趋近于1,但是小于1,不能等于1的原因有两方面:
- Initial fill
- Pipeline Stall and Flush
流水线的Stall

流水线的Flush
流水线的控制依赖

假设在10级流水线CPU中,所执行指令中有50%的branch指令,其中50%的branch都是taken的,最终计算中branch是否taken是在第6级流水线,其他情况都是理想的,那么此时CPU的CPI是多少?答案是:1 + 0.5*0.5*5 = 2.25
流水线的数据依赖

判断如下I1和I2指令之间可能存在什么dependency?
ADD R1,R2, R3
SUB R2,R1, 1
答案是:RAW WAR
Dependancies和Hazard
注意:如果是顺序执行的处理器,只有RAW才会产生Hazard,WAR和WAW是假相关;如果是乱序执行的处理器,RAW、WAR、WAW都会产生Hazard。
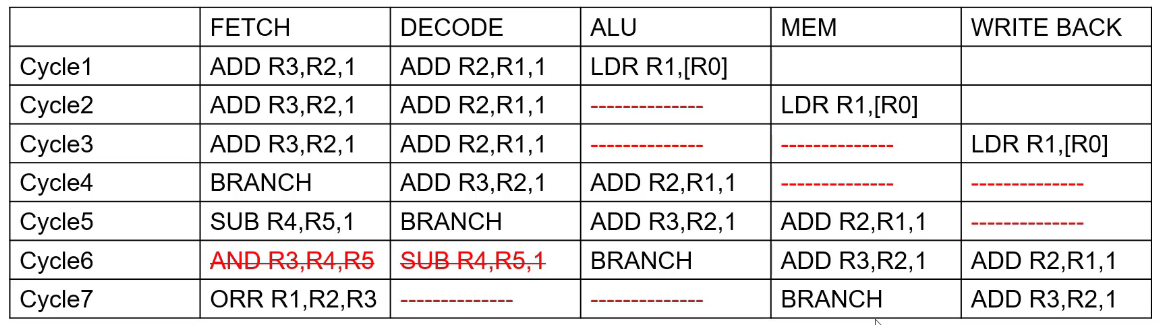
以下汇编中,需要在什么地方用到哪些解决Hazards/Dependencies的方法,假设branch指令最终结果是taken?
BEQ Label
ADD R1,R1,R1
SUB R2,R2,R2
Label:
LDR R1, [R0]
ADD R2, R1, 1
SUB R3, R2, 1
- Control Hazards:flush
- Data Hazards:stall
- Data Hazards:Forwarding

流水线的级数
更多流水线的级数会导致 :
- More Hazards: CPI会增大
- Less work per stage:Cycle Time会减小
Execution Time = #instructions * CPI * Cycle Time
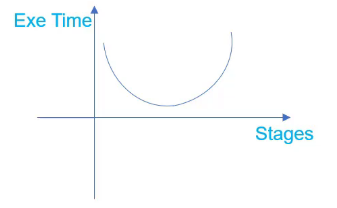
- 只考虑Performance的情况下:30-40 Stages pipeline
- 综合考虑Performance和Power的情况下:10-15 Stages pipeline (处理器流水线级数越大,控制逻辑越复杂,寄存器也越多,导致功耗面积增大)
分支指令和分支预测
流水线中的Branch

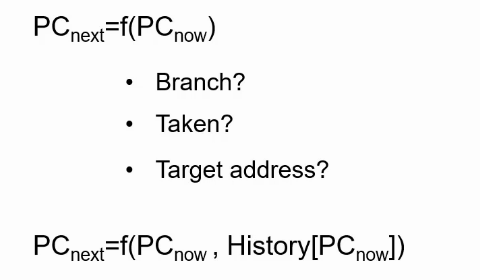
Branch指令预测
指令预测需要考虑三个问题:
- Is this a branch?
- Is it taken?
- If taken,what is the target address(PC)?

分支预测精确度

分支预测函数
Branch Target Buffer
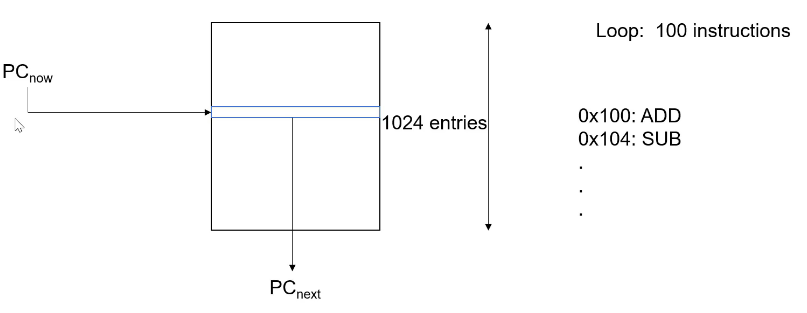
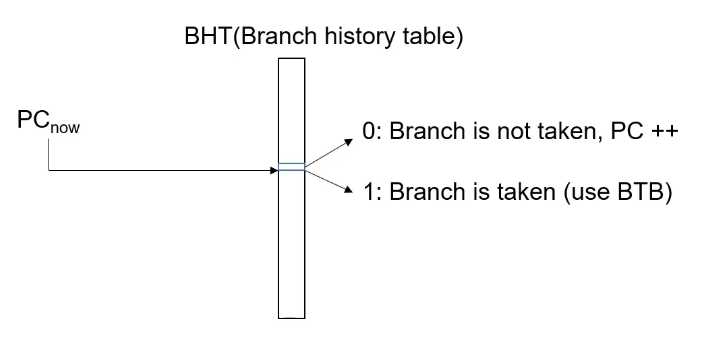
1-bit预测

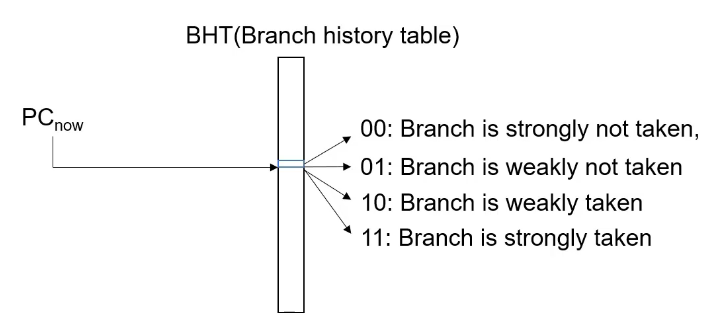
2-bit预测
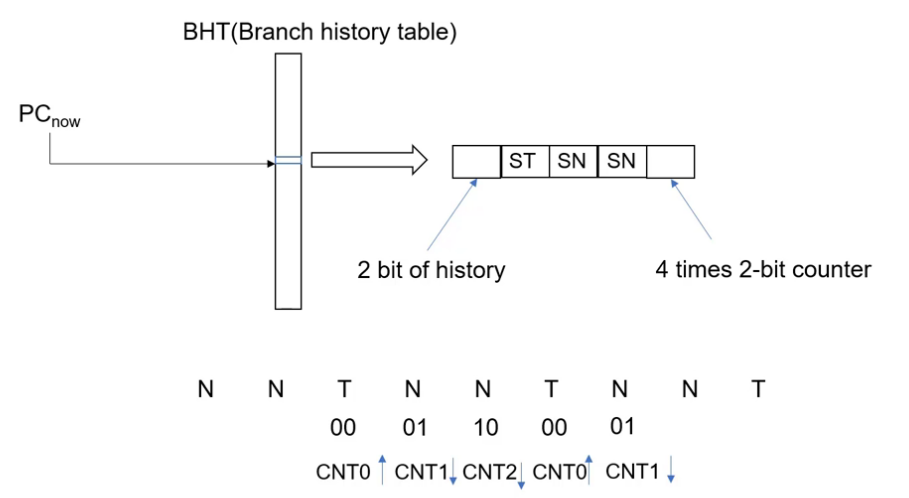
两级2-bit预测
关于分支预测的总结
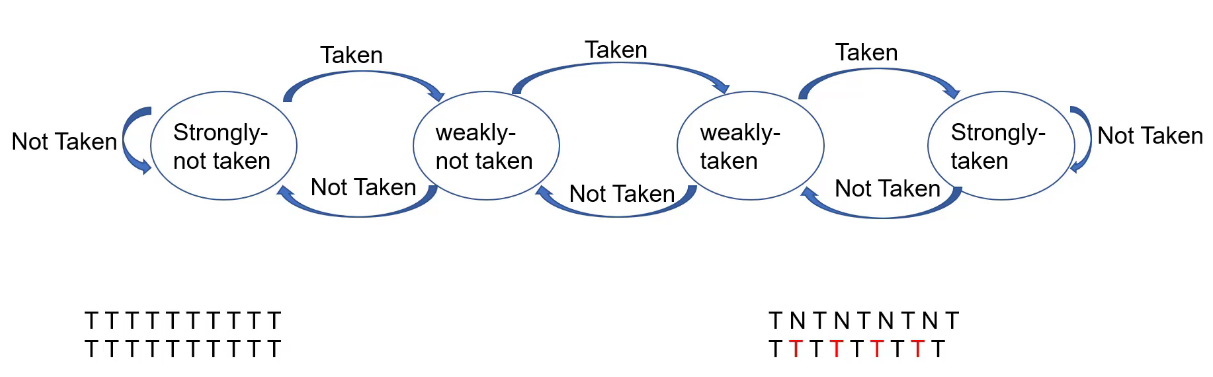
- 预测总Taken,但面对NNNN… (常Not Taken)情况,miss率较高。
- 1bit预测,解决NNNN… (常Not Taken),但面对NTNTNTNT… (单次翻转较多)情况,miss率较高。
- 2bit预测,解决NTNTNTNT… (单次翻转较多)情况,但面对NNTTNNTT… (两次翻转较多)情况,miss率较高。
- 两级2bit预测,解决NNTTNNTT… (两次翻转较多)情况。
- 经过多次改进,miss率不断在提高,但仍不可能降为0.
RAS(Return address stack)

分支指令分三种类型 :
- 条件跳转:Taken or Not Taken由预测算法判断,Target Address由BTB获取。
- 无条件跳转:始终Taken,Target Address由BTB获取。
- 函数返回:始终Taken,Target Address???
对于函数返回的目标地址,如果由BTB获取,会影响预测的准确性。比如第一次条件跳转至函数FUN,地址为0x1230,函数返回时将0x1230记录在BTB;当第二次无条件跳转至函数FUN,地址为0x1250,函数返回时从BTB获取的是0x1230,显然错误。所以这里引入RAS,在Call FUN时将返回地址记录在RAS。
其功能与栈指针作用相同,而将其实现在Fetch部件,可提高预测精确度。
Memory管理
Memory层级
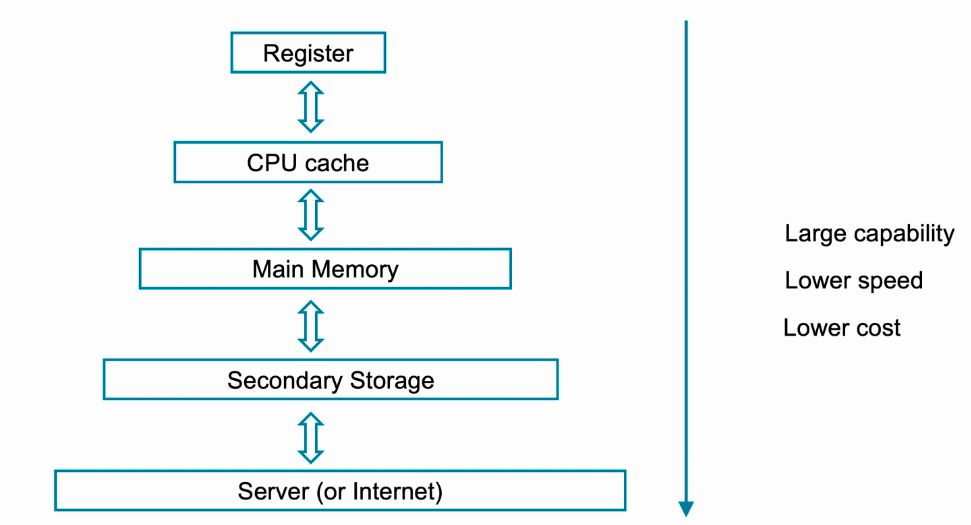
- Register:Flip-Flop
- CPU Cache:SRAM
- Main Memory:ROM,RAM,DDR
- Secondary Storage:Flash、硬盘
- Server(or Internet)
Memory管理
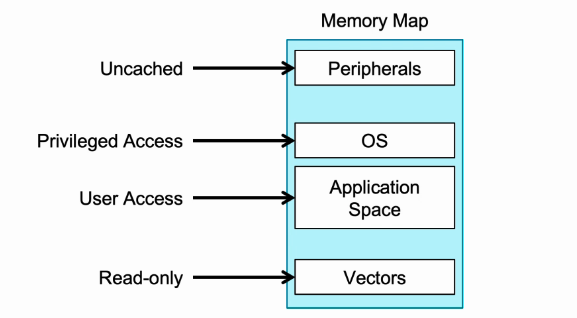
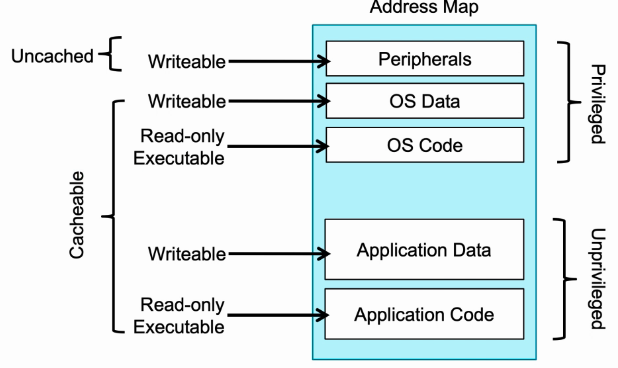
- 首先ARM的地址空间是统一编址的。
- 外设区域是不可缓存的。
- OS必须在特权操作下访问。
- 应用程序可以在用户或特权模式下访问。
- 异常向量表区域是只读的,不可修改。
虚拟地址与物理地址
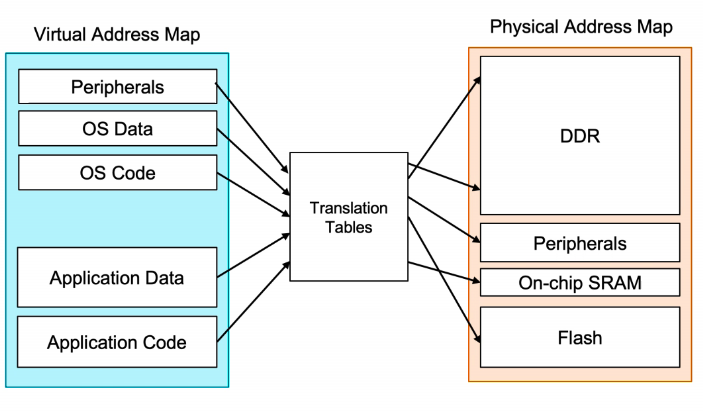
- 物理地址:物理地址空间是实在的存在于计算机中的硬件资源,包括DDR、外设、SRAM、Flash等。
- 虚拟地址:虚拟地址空间并不真实存在于计算机中。每个进程都分配有自己的虚拟空间,而且只能访问自己被分配使用的空间。
- 虚拟地址和物理地址之间存在映射关系,虚拟地址是软件层面的使用方法,而硬件实现时需要将虚拟地址根据映射关系,去访问对应物理地址的空间。
为什么需要虚拟地址?
一个应用程序(源程序)经编译后,通常会形成若干目标程序;这些目标程序再经过连接便形成了可装入程序。这些程序的地址通常都是从“0”开始的,程序中的其它地址都是相对于起始地址计算的,这些地址被称为“相对地址”。那么这样做的好处是什么?
- 方便编译器和操作系统安排程序的地址分布(起始地址和相对地址)。
- 方便进程之间隔离(每个程序根据映射关系划分自己的物理空间)。
- 方便OS合理化使用内存(可以使用不相邻物理空间来映射相邻虚拟地址,同时方便内存页的替换)。
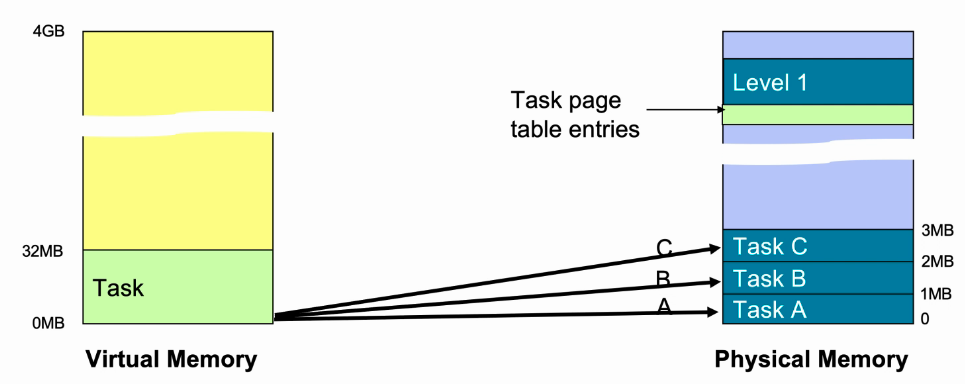
Multi-tasking
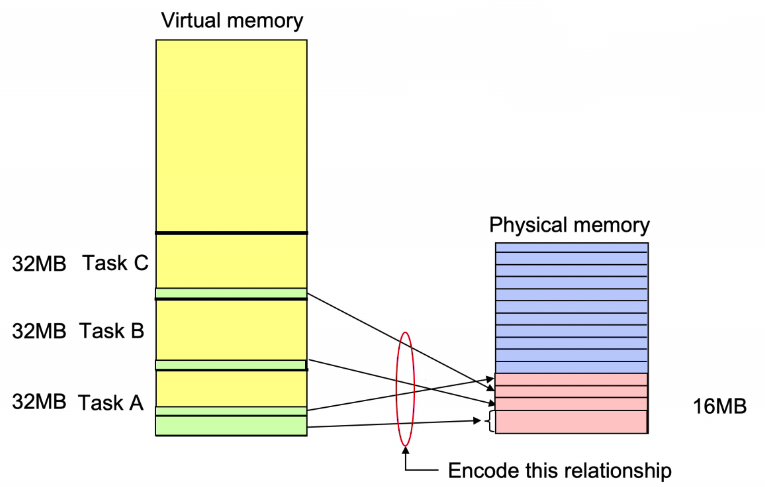
- 每个任务都是独立的,并且是并发的。
- 每个任务占用空间为32MB,三个任务占用空间为96MB。
- 实际运行时不必需要96MB,根据映射关系,可将3个任务的部分空间映射在物理内存,并在程序运行时进行动态替换。
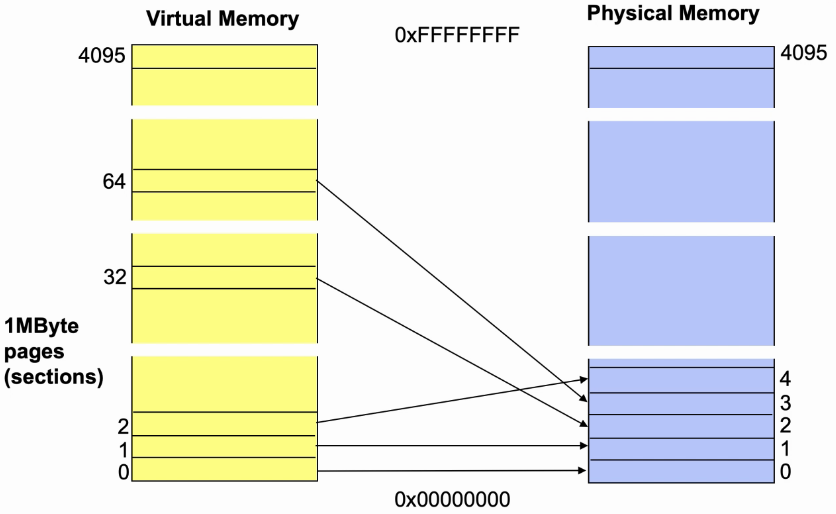
Translation Table(Page Table)
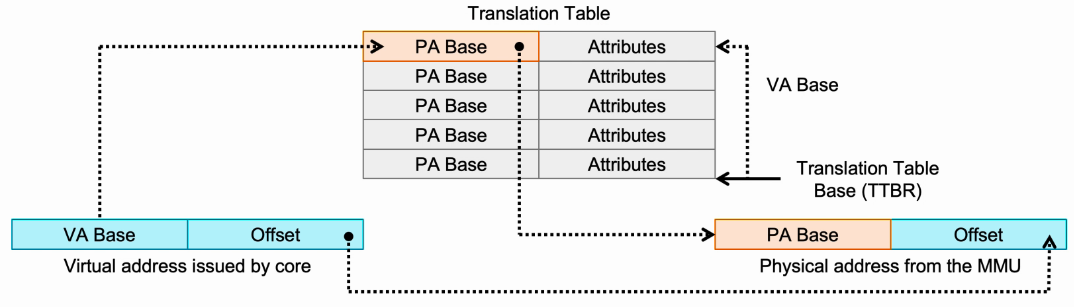
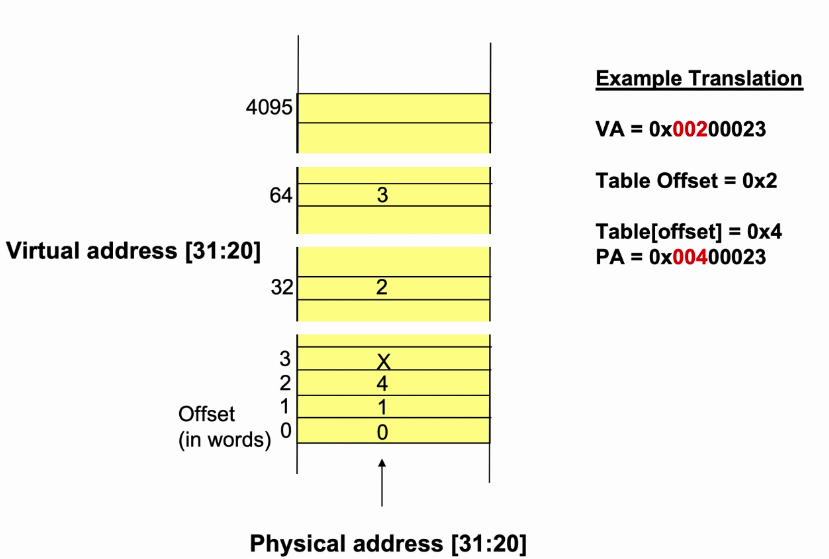
- 处理器架构定义64bit的虚拟地址:
- 高位标识访问哪个page,用作translation table中的索引。
- 低位作为物理块内的偏移量。
- 物理地址就是将translation table中的物理地址位与原虚拟地址中的低位的组合。
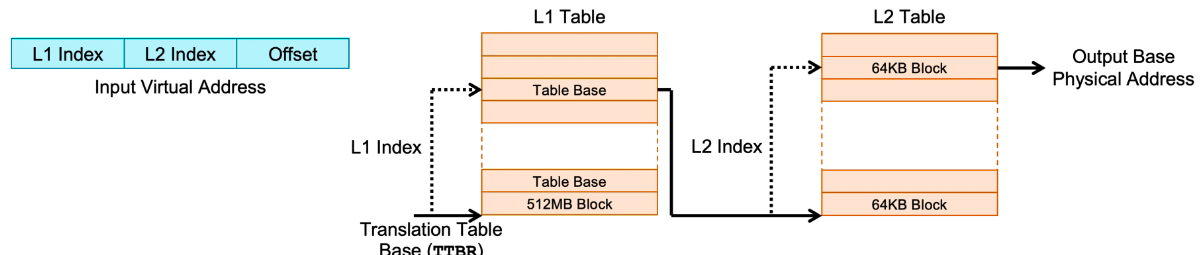
多级Page Table
- First-level tables将虚拟内存的区域以较大粒度进行粗略划分:
- 使用VA中的第一位字段对First-level tables进行索引。
- 在此示例中,每个table entrie包含512MB的物理空间。
- Second-level tables在First-level基础上,再进一步划分:
- Second-level tables使用VA的第二位字段进行索引。
- 每个table entrie包含62KB的物理空间。
- VA的最后一个位字段作为最终物理地址的偏移量。
-
多级页表与一级页表相比,可节省更多的资源,比如页大小为4KB(VA[12:0]),虚拟地址空间为4GB(VA[31:0]),一级页表需要1M个entry,如果采用两级页表,一级页大小为4MB(VA[22:0]),一级页表和二级页表个需要1K个entry 。
-
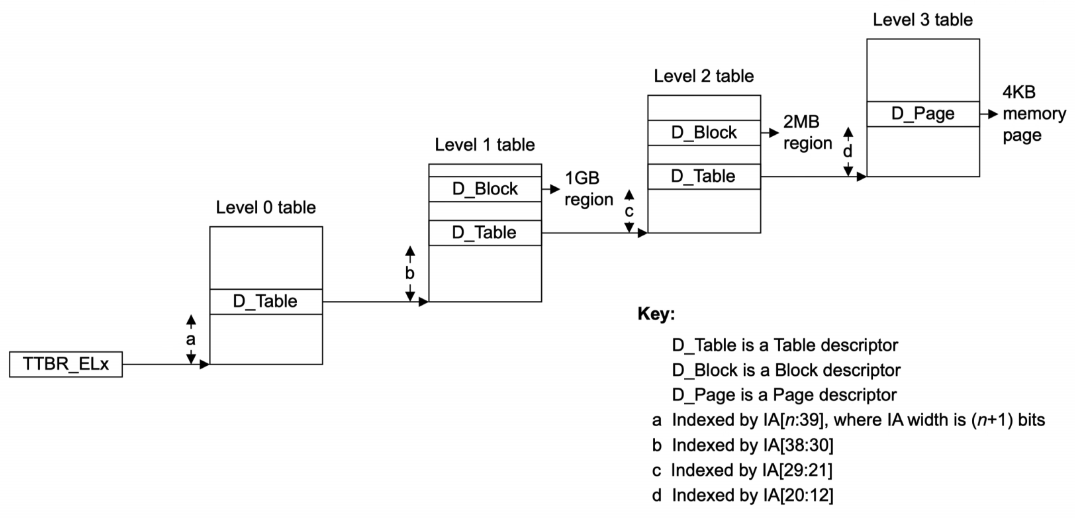
从内存中的First-level tables、Second-level tables…一级一级拿到Base Address,最后与VA的低位(页内偏移量)组合为物理地址的过程,称为 Called a page table Walk 。
Page Size
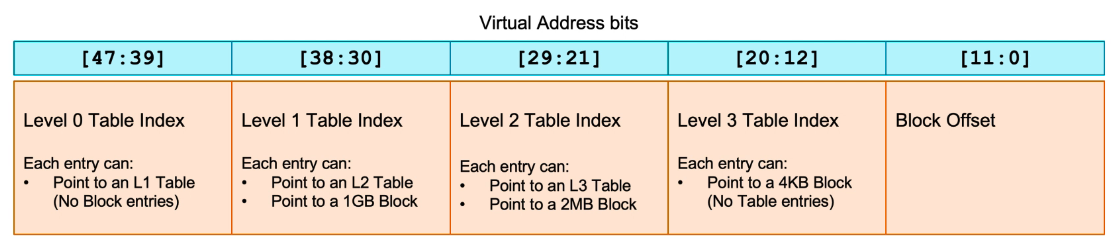
- AArch64 支持3种不同的Page Size:4KB、16KB、64KB。
- Page Size的大小决定于最低一级的Page Table。
- Page Size的大小可通过系统寄存器TTBR进行配置(如果实现了以上3种Page Size)。
- 举例:Page Size 4KB,4-level look up,48-bit address,9-bit address per level(512 entries)
进程切换和Memory管理
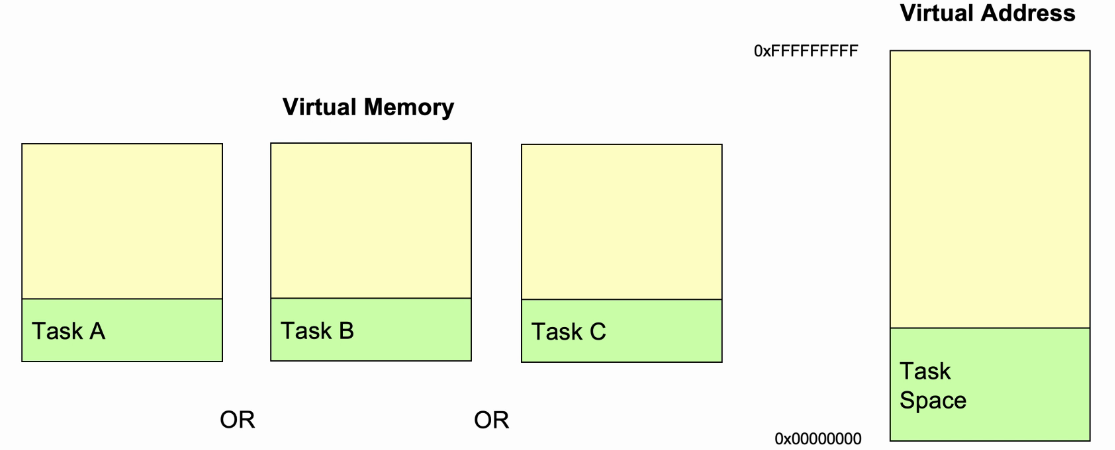
- 操作系统将一地址范围定义为task space,通常在内存底部。
- Task A、Task B、Task C使用的是同一块虚拟地址空间;对于OS而言统一分配一块独立的task space,供所有的任务使用,OS的工作就是切换不同的task由处理器执行。
- 如果多个任务想要运行在同一个虚拟地址空间,则需要将同一个虚拟地址空间映射到不同的物理地址空间。
- TLB存放的是cache的Transaction Table Entries。
- 如果OS切换任务,需要拿到另外一个任务的Transaction Table Entries,重新做page table Walk,同时需要清除TLB数据。
- 这样每次进行任务切换都需要进行TLB的清除,这样会导致性能降低。
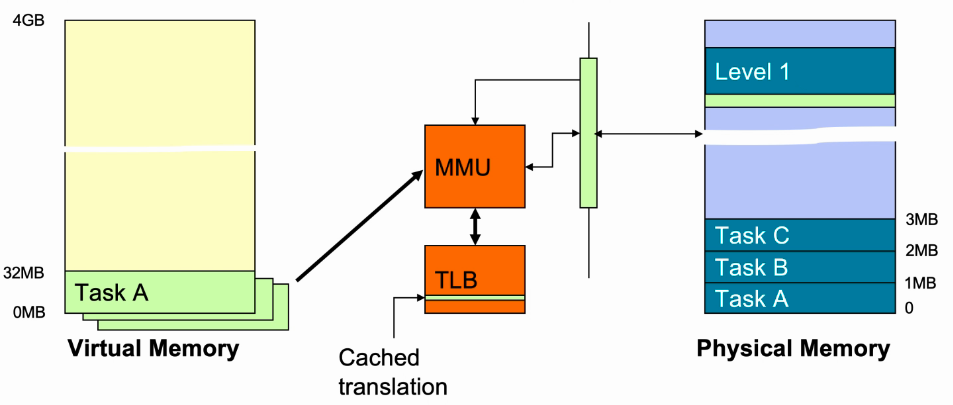
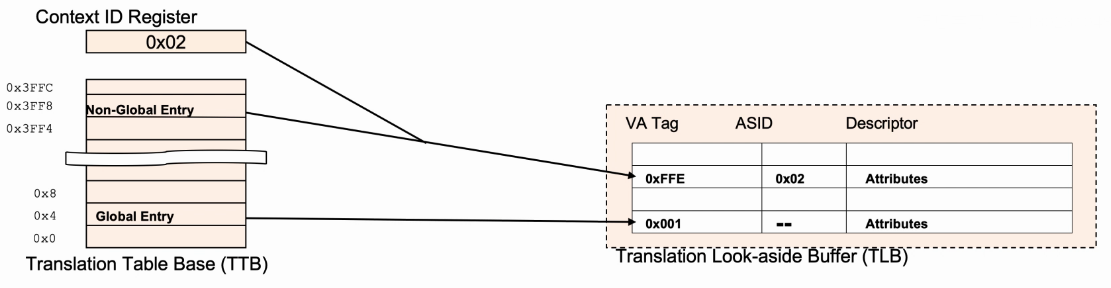
- ASID(Address Space Identifier)用于标识当前运行的进程,ASID是8bits位宽,存储在Context ID Register。
- Transaction Table Entries可以标记为Global或Non-Global(nG bit)。
- 对于Global entry,所有进程都可以使用。
- 对于Non-Global entry,只有特定的进程才可以使用,这里需要额外存储ASID Value。
- 通过增加ASID,当不同任务使用相同虚拟地址,OS在进行任务切换时,需要匹配ASID,如果ASID不匹配,则TLB不hit,这样可避免每次进程切换都清除TLB。
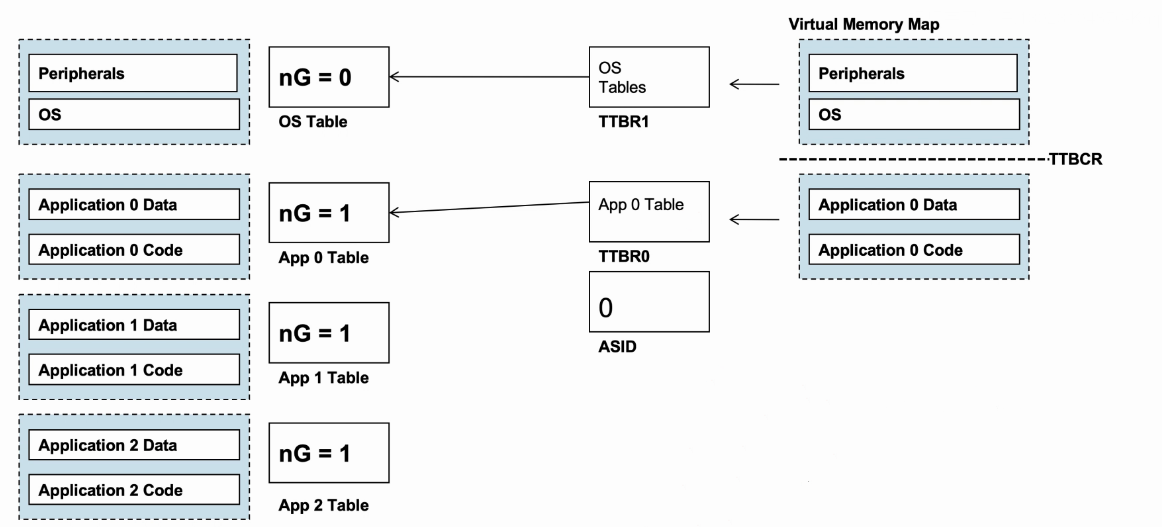
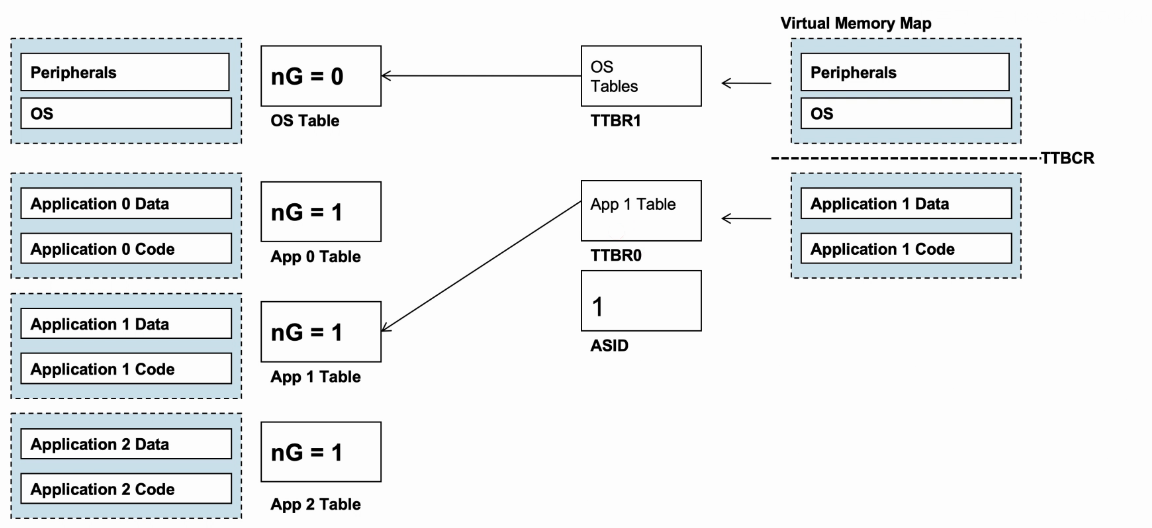
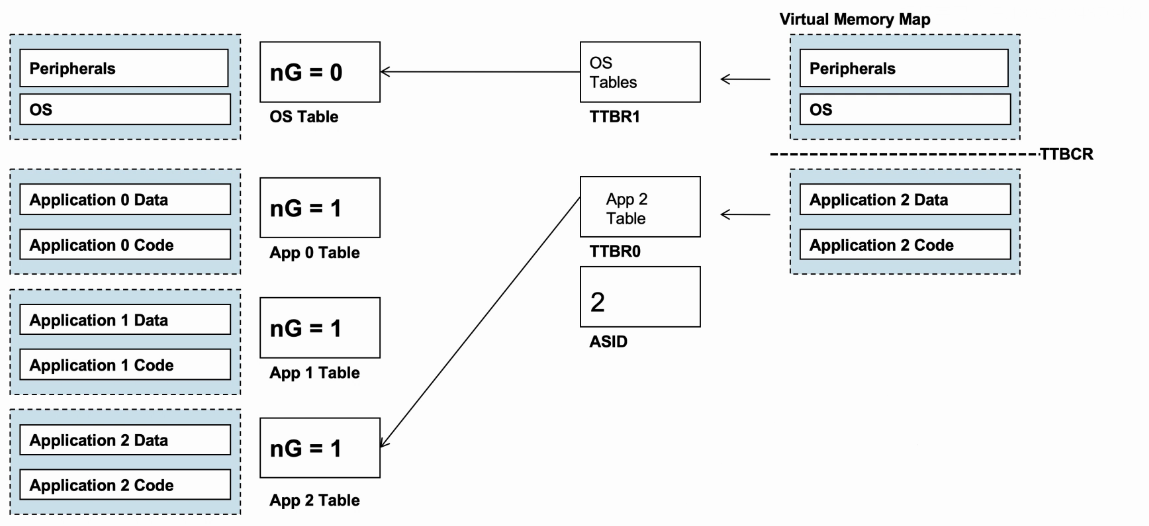
- 举例说明:
- nG为0代表Global entry,nG为1代表Non-Global entry。
- 每个进程都有自己的transaction table(kernal space的静态表)和ASID。
- OS可以通过更新TTBR0和ASID来切换进程,而无需清除TLB。
TLB
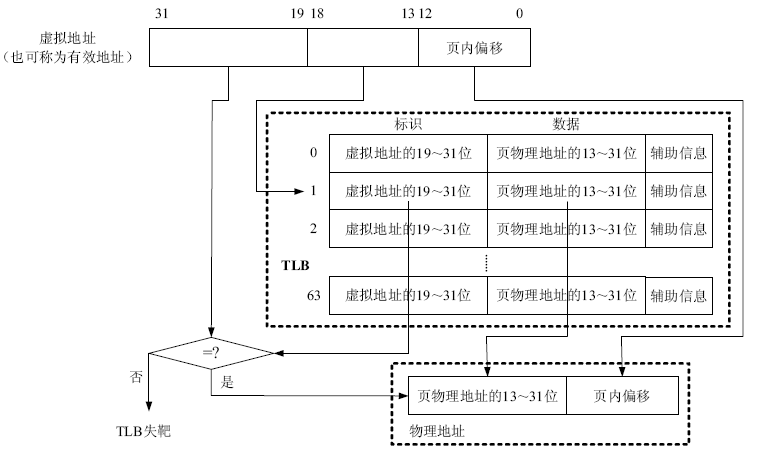
页表一般都很大,并且存放在内存中,所以处理器读取指令/数据需要访问两次内存:首先通过查询页表得到物理地址,然后访问该物理地址读取指令/数据。为了减小对内存访问导致的处理器性能下降,引入了TLB。
-
TLB类似于存储Transaction Table的cache:
- TLB的目的是实现VA转PA。
- 减小从外部存储器获取页表的访问时间。
-
TLB较小,而cache很大:
- L1 Cache容量8〜64KB。
- L1 TLB entries数目4〜64 entries,每个entry 大约4word。
-
TLB仅存储最终的Transaction Table:
- 首先页表本质仍是一块存储区域,可以通过访问存储获取页表项。
- 通过访问TLB,1cycle就能将VA转换为PA。
- 通过访问cache来得到PA,几级页表就需要访问几次cache,获得所有级的页表项才能将VA转换为PA。
-
关于通过访存实现VA转PA的过程(假设两级页表):
- 访问L1页表项,通过虚拟地址中的L1页表号和TTBR中的基地址来访存,拿到L1页表项。
- 访问L2页表项,通过虚拟地址的L2页表号和L1页表项中的基地址来访存,拿到L2页表项。
- 将最终的L1和L2页表项的基地址与虚拟地址的页内偏移量组合为物理地址。
MMU
-
MMU就是专门处理虚拟地址到物理地址的转换。
- 从硬件上读取内存中的Transaction Table。
- Transaction Table的基址寄存器(TTBR)保存Transaction Table的物理基地址。
- TLB缓存最近访问的Transaction Table。
-
开启MMU后,所有CPU的内存访问都要通过MMU进行处理。
- MMU将通过TLB完成VA转PA,当TLB miss时,则需要进行Table Walk操作。
- 只要MMU实现VA转PA后,才可以访问cache。

Memory Model
- 典型系统的内存映射被划分为多个逻辑区域。
- 每个区域可能需要不同的内存属性,比如访问权限。
- Normal类型(非外设)的存储,存放代码的程序段和数据段,其存储介质可能是DRAM,SRAM,flash,ROM等。
- 将地址区域标记为Normal,将告诉处理器访问该位置没有任何副作用。
- 将地址区域标记为Normal,可以使处理器执行许多优化操作。
- Re-ordering:可更改地址访问顺序。
- Merging:多次相邻区域访问可合并为一个访问。
- Speculation:预测访问。
- Unaligned accesses:非对齐访问。
- 标记为Normal的地址,可以是cacheable也可以是non-cacheable。
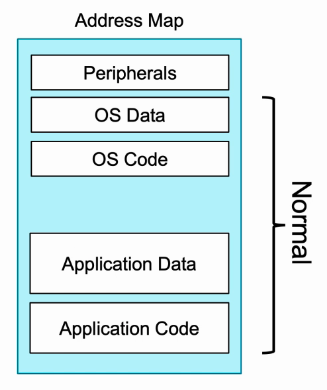
- Device类型的地址空间用于访问外围设备。
- 将地址区域标记为Device会告诉处理器访问可能会有副作用(side effects)。
- 如果地址区域标记为Device,不允许以下访问操作:
- Perform speculative data accesses:预测访问。
- Re-order accesses:可更改地址访问顺序。
- Re-size accesses:更改访问大小。
- Device类型的地址空间不能存放代码的程序和数据。
- Device类型的地址空间不能cacheable,但是可以bufferable(将外设送来的数据暂时存放,以便处理器将它取走)。
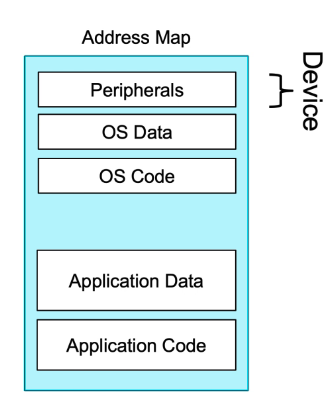
- Strongly Ordered:是限制性最强的存储类型,不可以cacheable,也不可以bufferable。
- 它的访问具有与Device相同的限制,并且不允许提前终止(提前终止是指存储系统一旦缓存了数据,但在该数据未到达最终的从设备之前,即表示写入已完成)。
- 当未开启MMU时,所有的存储访问都认为是Strongly Ordered,因此,在启动过程中尽早启用MMU,否则会影响性能。
处理器性能
性能的衡量指标
- Latency(延迟):指令从取指到写回寄存器所需要的时间。
- Throughput(吞吐量):单位时间内执行的指令数量。
- 但是Throughput并不等于Latency的倒数。
- 举例:五级流水结构,假设Latency为20s,也就是每拍需要4s,而理想情况下的流水操作每拍完成一条指令,那么Throughput为0.25/s
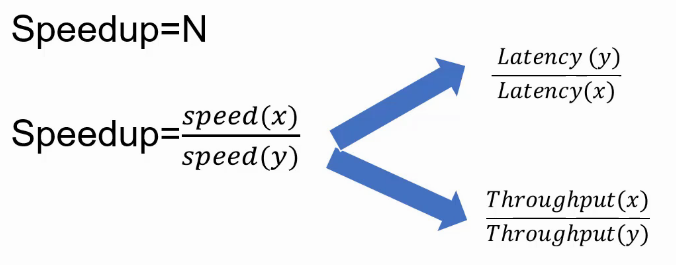
比较性能
- SpeedUp简单说就是一个处理器与另一款处理器的运算速度之比(X is N times faster than Y):
- SpeedUp与Latency成反比。
- SpeedUp与Throughput成正比。
衡量性能
- Performance 近似等于 1/(Execution time),但是程序的执行时间,是指哪些程序的执行呢?
- 通常使用的应用程序吗?
- 这些应用程序众多,选择哪些,不选择哪些?
- 这些应用程序是否具有一定代表性?
- 怎么获取这些应用程序?
- 所以,选择标准的测试程序:Benchmark。
- Benchmark专为性能测试而生。
- Benchmark是一套测试程序,包含众多测试程序。
- 每一个测试程序都具有某种应用场景的代表性,比如整型运算和浮点运算。
Benchmark类型
- Real Benchmark :
- 具有非常强的应用代表性,比如可测试客户终端在Browsing(浏览)的应用场景,CPU性能如何。
- 但是在CPU开发中没有完善的OS和硬件驱动,因此Real Benchmark的测试环境要求较高。
- Kernels Benchmark :
- 从应用程序中提取的一些典型的重要的算法,如Geekbench。
- Synthetic Benchmark :
- 与Kernels Benchmark相比更小的测试片段,非真实的应用程序,如Dhrystone。
Benchmarkn标准
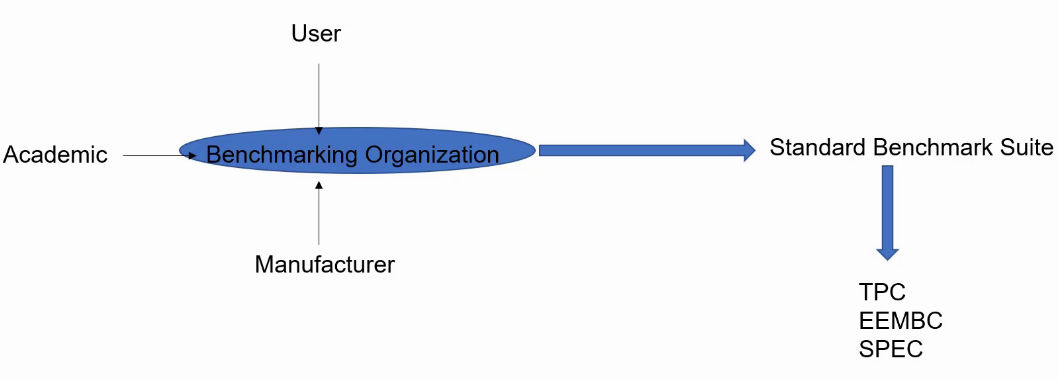
- Benchmark组织从一些厂商、研究机构、终端客户中搜集信息形成一套标准的Benchmark测试程序。
- TPC:针对DataBase(数据库)和WebServer。
- EEMBC:针对嵌入式程序,如CoreMark。
- SPEC:针对整型和浮点的运算,如SPEC2000和SPEC2006,以及最新的SPEC2017。
性能的Iron Law
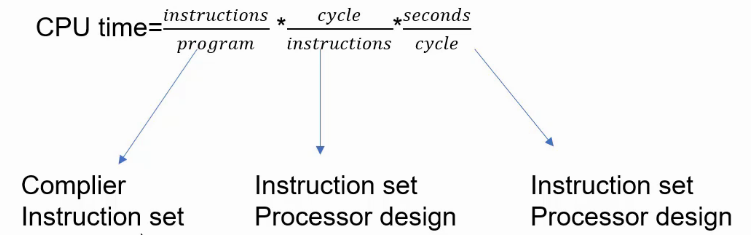
- 关于CPU的性能,是存在这样一条铁律:CPU time = instr num per program * cycle num per instr * time per clock 。
- 减小instr num per program,需要优化编译器,同时与指令集相关,单指令功能越复杂,需要的指令数目越少。
- 减小cycle num per instr,需要优化硬件设计结构,同时与指令集相关,单指令功能越简单,指令需要的cycle数目越少。
- 减小time per clock,需要优化工艺,同时与指令集和硬件设计结构相关,减少单cycle的逻辑运算复杂度。
- 实际三者相互制约,再设计CPU的过程,往往在这三者之间做权衡,尽量达到理想状态。
效能(power efficiency)
衡量一款处理器还有一个标准,那就是效能,也就是能耗比,尤其在移动端处理器能效指标非常重要。
Memory Ordering
Memory Ordering介绍
- Data Dependency:Forwarding和Stall
ADD R0, R1, R2
SUB R3, R2, R0
- Control Dependency:Branch prediction和Flush
- Memory Dependency?R0 等于 R2?
STR R1, [R0]
LDR R3, [R2]
Load Store Queue
LDR R1, [R1]
STR R2, [R3]
LDR R4, [R4]
STR R5, [R0]
LDR R5, [R8]
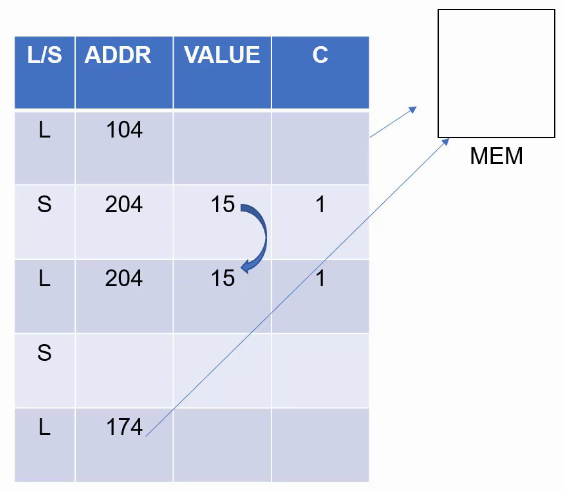
- 访问存储器时的Dependency,就是指Store在前,Load在后,访问同一个地址。
- 如果Store和Load地址已经计算出,Load明确知道自己要去访问Store指令的数据,这时候可以通过数据的forward来提高性能。
- 如果Store地址未计算出,Load指令不知道是否会发生Dependency怎么办?
- In Order:顺序执行,待Store完成后再执行Load。
- Wait for all previous store address:确定不发生Dependency再执行Load。
- Go anyway:直接执行Load,当发现发生Dependency时,进行Reload,甚至是flush掉load后续的指令(后续指令有可能与load指令的目的寄存器相关)。
- 往往这种Go anyway的投机方式会使CPU性能提高。
Out of order load/store execution
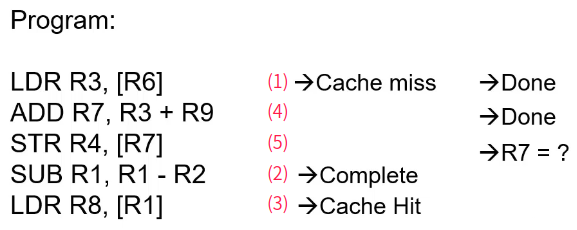
- 红色数字代表指令执行顺序。
- 首先执行的是第一条指令“LDR R3, [R6]”,但是发生cache miss,需要向下一级访问存储,这个过程需要一些时间。
- 由于第二条指令“ADD R7, R3, R9”的R3依赖第一条指令的R3, 第三条指令的“STR R4, [R7]”的R7依赖第二条指令的R7,所以暂时不能执行。
- 越过第二条第三条指令,第四条指令“SUB R1, R1, R2”与前面指令没有依赖关系,可以执行。
- 第四条指令完成后,可以执行第五条指令“LDR R8, [R1]”。(注意这里的完成是指R1的写回结果已经计算完成,但由于前面指令未结束,是不可以写回体系结构寄存器的。)
- 接着,第一条指令已经load回结果,结束第一条指令。
- 第二条指令此时也可以执行,获得R7。
- 第三条指令此时也可以执行,将R4数据存入R7地址。
- 这里存在一个问题,第三条指令STR和第五条指令LDR是有可能存在依赖的(R1与R7相同),但是R7的结果需要一些时间才可以得知,但是第五条指令在未知是否依赖的前提下进行了前瞻执行,如果在获取R7后,判断是否形成依赖,如果形成依赖,需要reload,甚至flush掉后续其他指令。
In order load/store execution
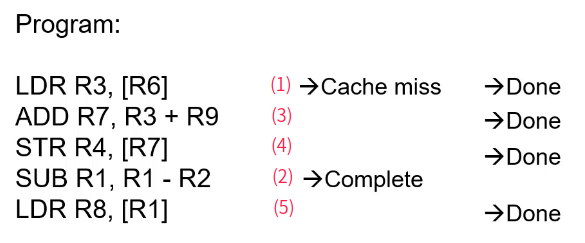
- 红色数字代表指令执行顺序。
- 首先执行的是第一条指令“LDR R3, [R6]”,但是发生cache miss,需要向下一级访问存储,这个过程需要一些时间。
- 由于第二条指令“ADD R7, R3, R9”的R3依赖第一条指令的R3, 第三条指令的“STR R4, [R7]”的R7依赖第二条指令的R7,所以暂时不能执行。
- 越过第二条第三条指令,第四条指令“SUB R1, R1, R2”与前面指令没有依赖关系,可以执行。
- 第四条指令完成后,第五条指令“LDR R8, [R1]”,是访存指令,需要等待前面所有访存指令执行完成才可以执行。
- 接着,第一条指令已经load回结果,结束第一条指令。
- 第二条指令此时也可以执行,获得R7。
- 第三条指令此时也可以执行,将R4数据存入R7地址。
- 前面访存指令全部完成,可以执行第五条指令“LDR R8, [R1]”,不会发生依赖。
ARM cache管理
Locality原则(局部性)
- 空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的。
- 时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息。
|
|
以上述代码为例:
- data:数组a的元素(空间局部性);每一次循环的sum值(时间局部性)。
- instr:指令代码段顺序存放(空间局部性);每一次循环相同操作(时间局部性)。
memory层级
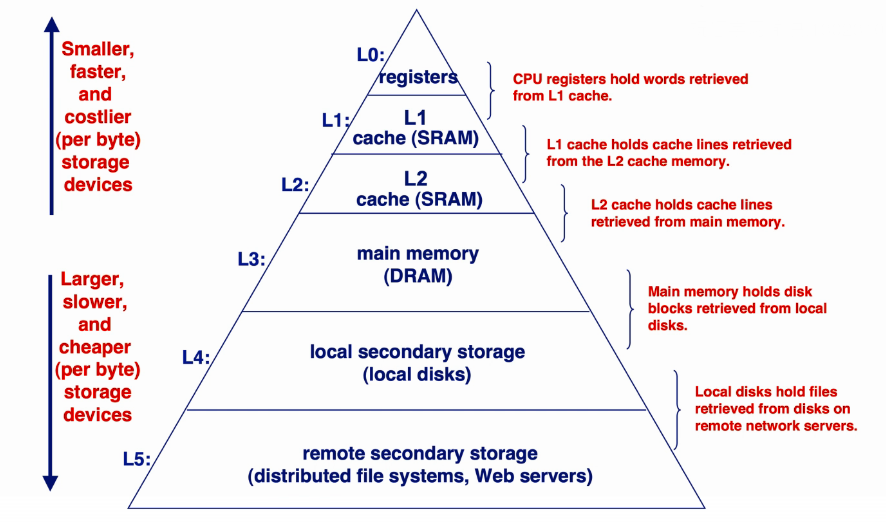
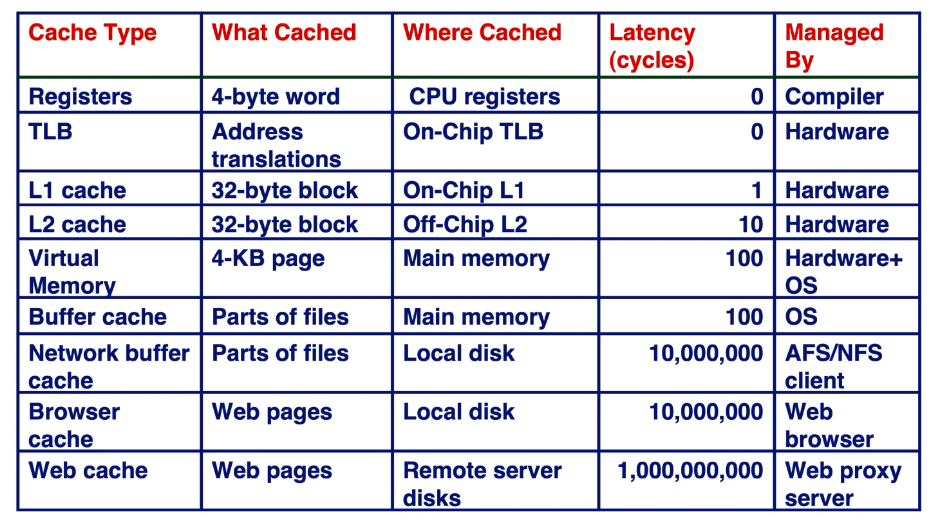
cache lookup
- cache的特点就是存储量小,访问速度快。
- cache是主存的缩影,存储这主存的部分数据。
- cahce的访问:
- cache hit:访问的数据存在cache里。访问时间快。
- cache miss:访问的数据不存在cache里,去更低一级的存储寻找,并将其缓存到cache。访问时间慢。
cache performance
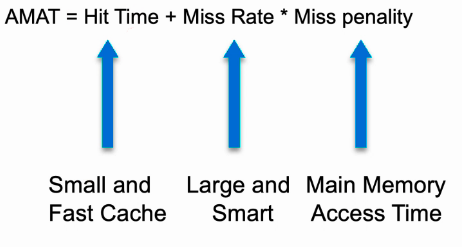
- cache性能衡量指标:AMAT(average memory access time)。
- 要想减小hit time,需要cache容量小,访问速度快。
- 要想减小miss rate,需要cache容量大,另外cache要足够smart,因为数据访问存在局部性,如何更好的利用局部性原则很关键,比如更优化的替换策略等。
- 访问主存的时间最长,往往也最不容易优化。
- 除此之外,多级cache,cache的相连结构,cacheline大小,访问主存带宽等众多因素,都会影响cache的性能。
cache size
- L1 Cache直接参与运行程序的load/store指令:
- 16KB~64KB
- 如果最大容量,命中率可达90%
- 如果最小容量,访存时间可达1~3cycles
cache organisation
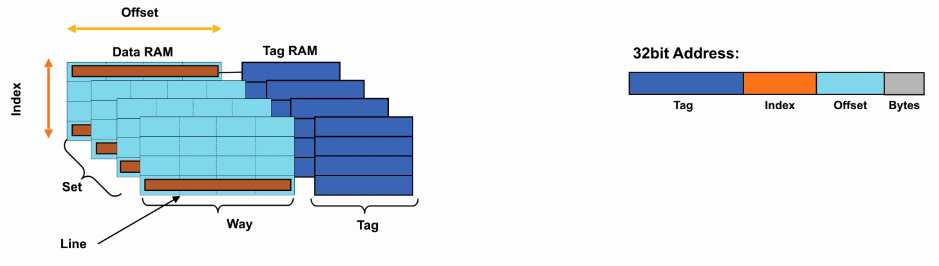
- 如何判断hit还是miss?
- 首先得到访问地址(物理地址)(地址高位做命中判断,低位做cache索引)。
- 根据访问地址,索引到cache entry。
- 将cache entry的tag部分与访问地址高位比较,相同则hit,不同则miss。
- cache line/block:cache每个entry存放的数据量。
- 1Byte?显然不行,粒度太小,不足以满足访问指令的需求。
- 1KByte?显然不行,粒度太大,没有访问指令需要访问如此大的连续空间。
- 32~128Byte?合理大小。
- cache容量一定的条件下,cache line越大,存放的entry量越小,miss率也就越高,所以cache line的大小需要合理。
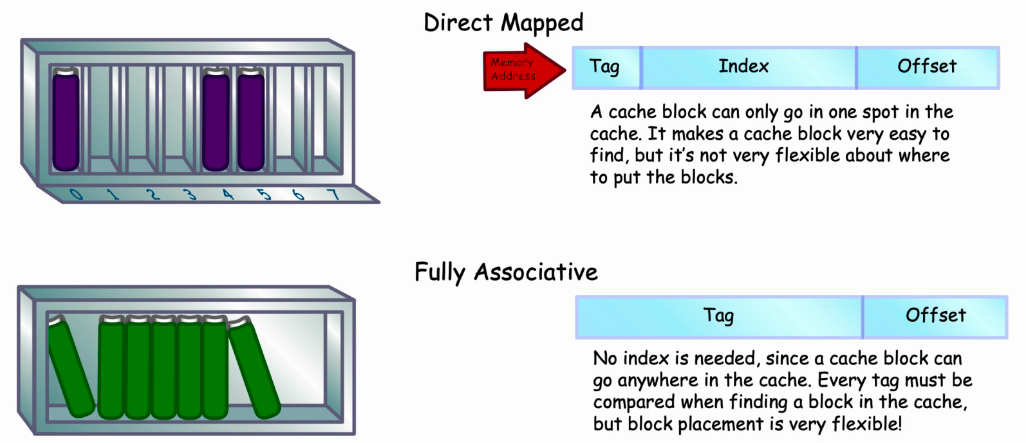
cache Type
- 直接映射:
- 主存与缓存分成相同大小的数据块。
- 主存容量应是缓存容量的整数倍,将主存空间按缓存的容量分成区,主存中每一区的块数与缓存的总块数相等。
- 主存中某区的一块存入缓存时只能存入缓存中块号相同的位置。
- 优点:地址映象方式简单,数据访问时,只需检查区号是否相等即可,因而可以得到比较快的访问速度,硬件设备简单。
- 缺点:容易产生冲突,替换操作频繁,命中率比较低。

- 全相联(Fully Associative):
- 主存与缓存分成相同大小的数据块。
- 主存的某一数据块可以装入缓存的任意一块空间中。
- 优点:命中率比较高,Cache存储空间利用率高。
- 缺点:每次访问都要与全部内容比较,速度低,成本高,因而应用少。
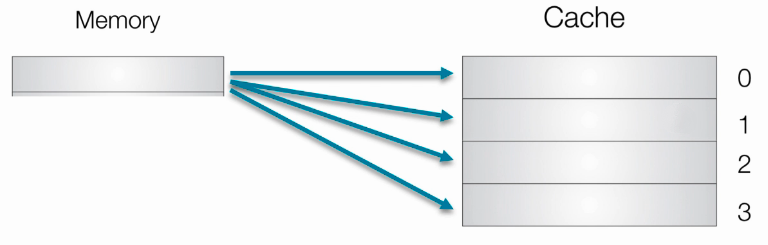
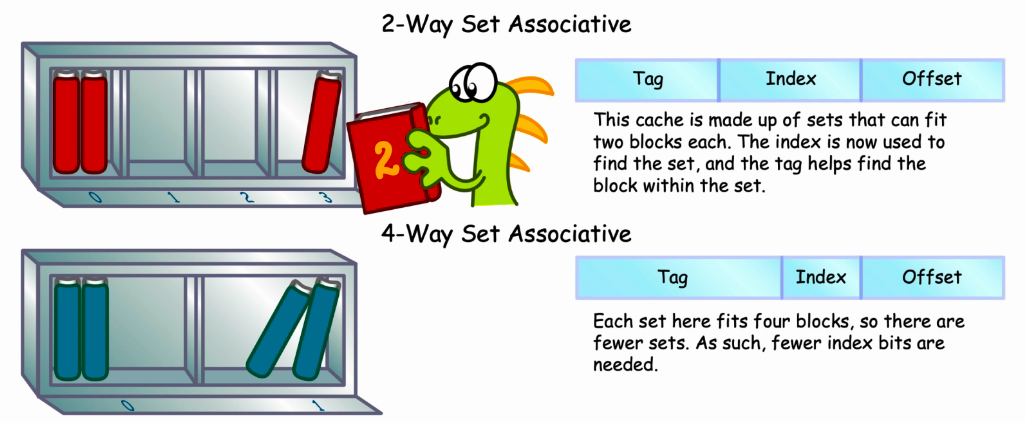
- 组相连:
- 主存和Cache都分组。
- 主存中一个组内的块数与Cache中的分组数相同。
- 组间采用直接映射,组内采用全相联映射。
- 适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
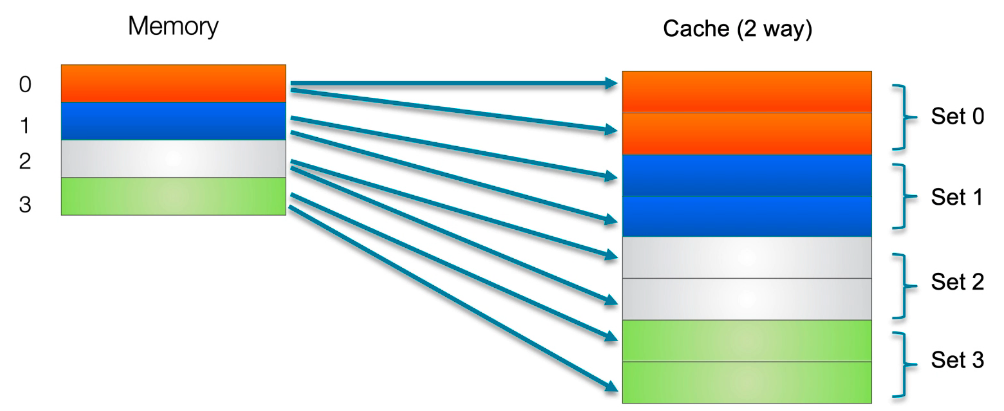
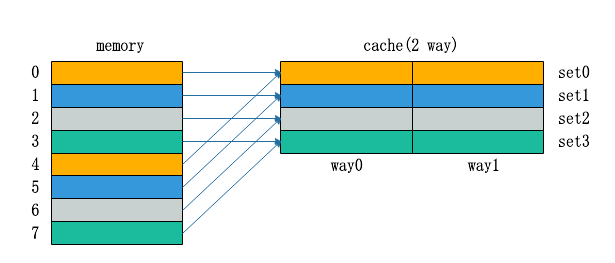
Cache的Tag、Index、offest

ARM Cache & Cache Policy
- ARM Cache :
- 容量小,访问速度快。
- 存储最近访问的数据。
- 避免对外部BUS的访问,进而减小了带宽需求和功耗。

- Cache Structure :
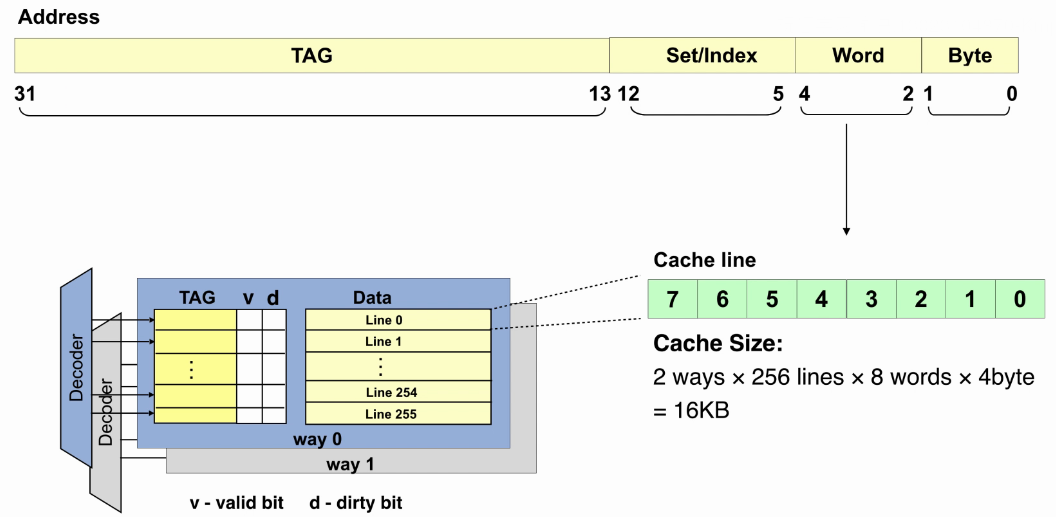
- Line:cache数据的存放单位量,一般是4Words或8Words。
- Way:组相联映射中,每个数据块可以存放在cache的不同way中。
- Set:同一个Index下的所有Way。
- Tag:memory的地址标记,来自访问地址的高位,用来判断miss or hit。
- Index:索引cache的Set号。
- 补充:可以将cache认为是二维数组(行x列),每个元素是一个cacheline,每一行是一个set,每一行有几个元素就是几Way。
- Example:16KB 2-Way Cache :
- 2-Way Set Associative Cache :
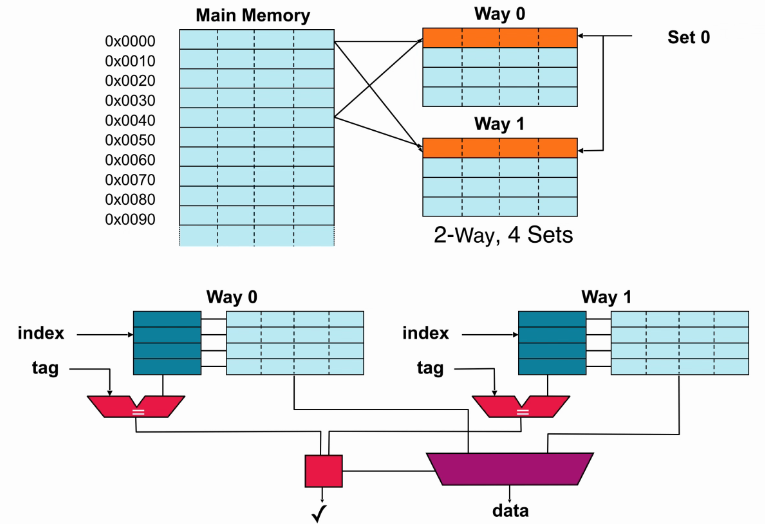
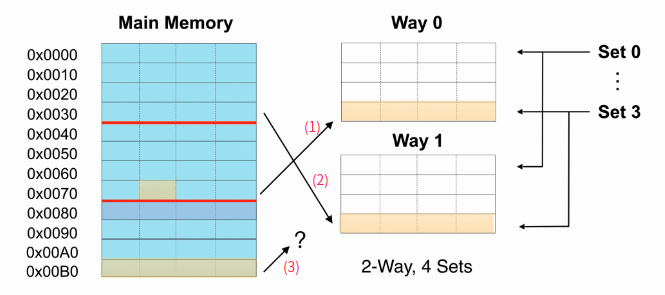
- replacement Strategies
- Random
- Round Robin
- Least Recently Used(LRU)
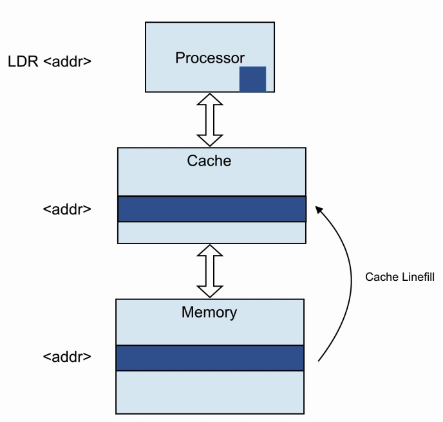
- Read Allocation :
- 执行Load指令,发现cache miss。
- 访问memory,将memory数据缓存到cache。注意:cache缓存数据是以cacheline为单位的,而此时load指令可能只取cacheline的一部分。
- 完成load指令,将load数据送至处理器。
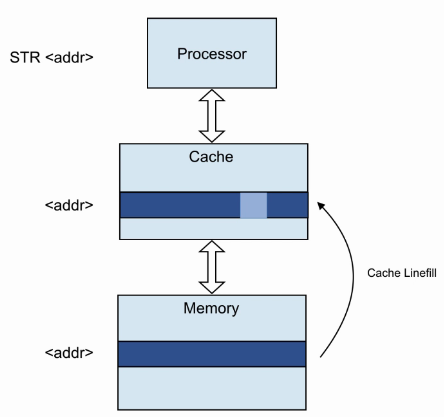
- Write Allocation :
- 执行Store指令,发现cache miss。
- 访问memory,将memory数据缓存到cache。注意:cache缓存数据是以cacheline为单位的,而此时store指令可能只取cacheline的一部分。
- 完成store指令,将store数据写入cacheline,并标记为dirty。
- Cache Write Strategy :
- Write Back:只是写到Cache里,Memory的内容要等到cache保存的要被别的数据替换或者系统做cache flush时,才会被更新。优点是CPU执行的效率提高,缺点是实现起来技术比较复杂。
- Write Through:当写数据进Cache时,也同时更新了相应的Memory里的内容。优点是简单,缺点是每次都要访问memory,速度比较慢。
Further Understand Cache Type
cache一致性
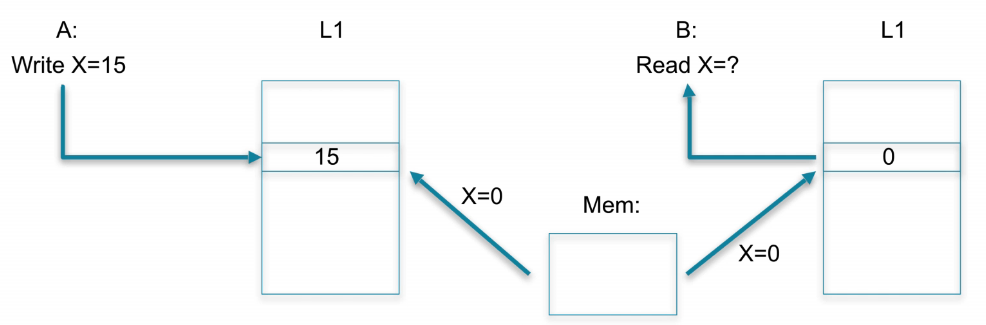
cache Coherency Problem
- 从软件角度,存储是共享的:假如两个core, CoreA writes x=15, CoreB read x, see 15
- 从硬件角度,每个core的cache是私有的:每个core都有一个L1 cache。
cache Coherency Definition
- cache与cache之间数据可能不一致。
- cache与memory之间数据可能不一致。
- 软件做法:将cache数据先放入memory,另外一个core将memory数据缓存至cache。
- 硬件做法:通过硬件的协议逻辑,保证数据一致性。

Evolution of ARM coherency support
- unicore:单core不需要做数据一致性。
- MPcore:多core之间维护数据一致性。
- System Wide Coherency:系统级数据一致性需要保证cluster多core的一致性,和cluster与cluster之间数据一致性(总线互连)。
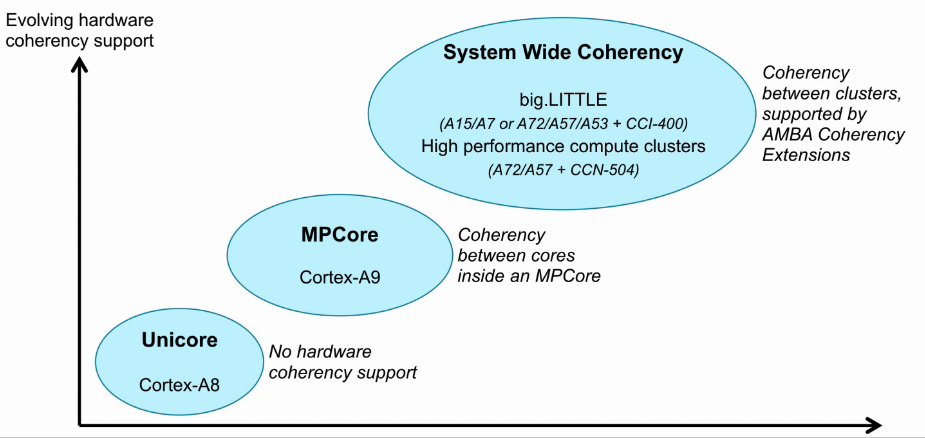
Cortex-A处理器的一致性
- Cortex-A8处理器为单核处理器,不需要数据一致性的保证。
- Cortex-A9及以后的处理器为多核处理器,需要硬件支持数据的一致性,不同cluster之间需要通过总线互连的方法保证数据一致性。
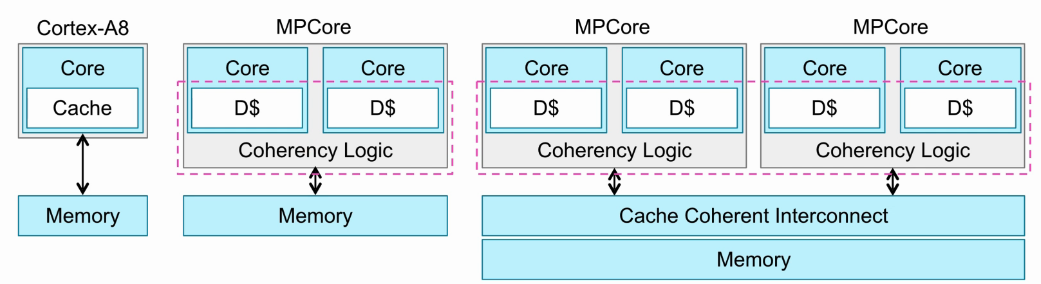
- 在没有一致性机制的系统里(如Mali GPU),软件必须保证所访问的L1/L2数据是clean。
- ACE-Lite接口允许没有cache的处理器去监测其他处理器的cache,确保自己访问的数据是clean状态。
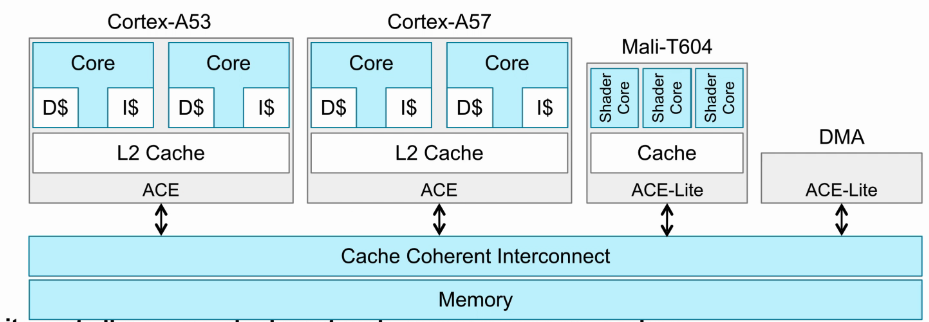
MOESI Protocol
- cache一致性的实现主要基于MESI或MOESI协议(这些state额外存储在L1 cache):
- Modified:cacheline is dirty and present in only one L1 cache
- Owned:cacheline is possibly in more than one L1 cache and is dirty
- Exclusive:cacheline is clean and present in only one L1 cache
- Shared:cacheline is clean and may be present in more than one L1 cache
- Invalid:cacheline is valid
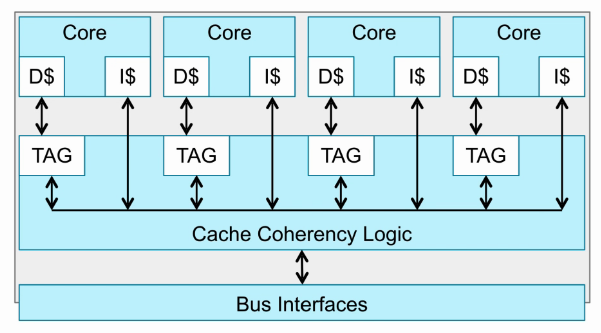
Coherency logic
- 首先这个cluster里有4个core,每个core都有Dcache和Icache。
- Dcache的TagRam会复制一份到Cache Coherency Logic。
- 当一个core访问某个地址空间,先从L1 Cache查找,如果miss,则在Cache Coherency Logic的其他core TagRam查找。
- 如果找到对应的地址空间,则去对应core的L1 Cache拿到数据。
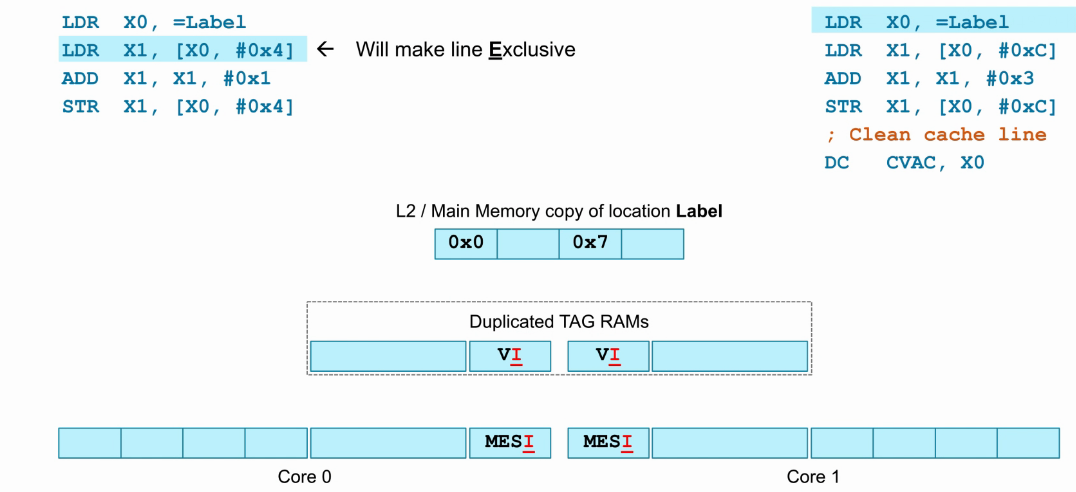
Coherency logic举例
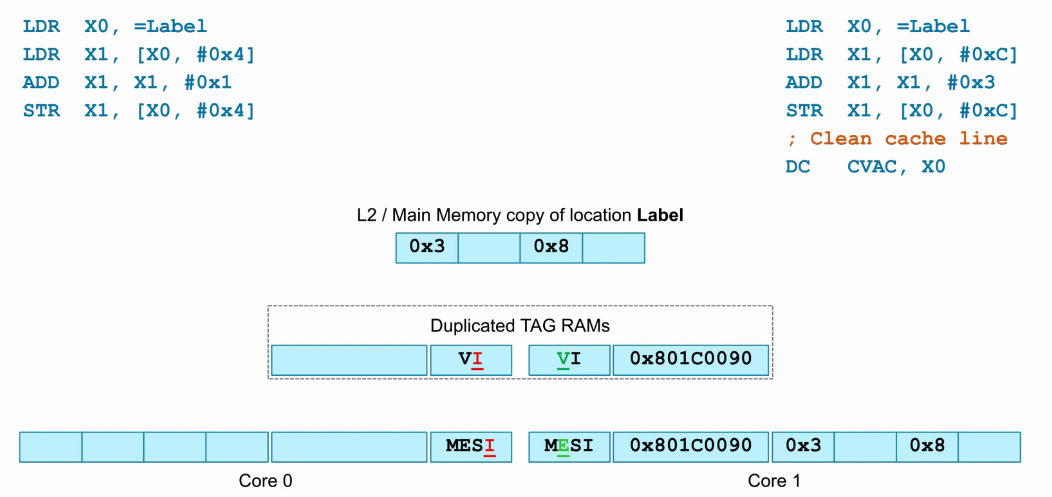
- 如下图,core0和core分别执行各自的指令。
- 起始core0和core1的cache以及core外(cluster)的Dup_TAG_RAM,都处于invalid状态。
- label是一个cacheline对齐的访存地址,core0执行“LDR X1, [X0, #0x4]”指令,发生cache miss,此时将L2或主存中的相应cacheline缓存至core0 cache,并置为Exclusive状态,因为只有core0 cache存在此cacheline,并且与L2或主存数据一致。
- core0相应cacheline的Dup_TAG_RAM同步为valid。
- 如下图,展示了上一步的执行结果,core0处于Exclusive状态,core1处于Invalid状态。
- core1的cache以及core外(cluster)的Dup_TAG_RAM,都处于invalid状态。
- 此时执行core1的“LDR X1, [X0, #0xc]”指令,发生cache miss,此时查找Dup_TAG_RAM,发现core0内存在该cacheline,将core0内该cacheline缓存至core1 cache,并置为Share状态,因为core0 cache和core1 cache都存在此cacheline,并且与L2或主存数据一致。
- core1相应cacheline的Dup_TAG_RAM同步为valid。
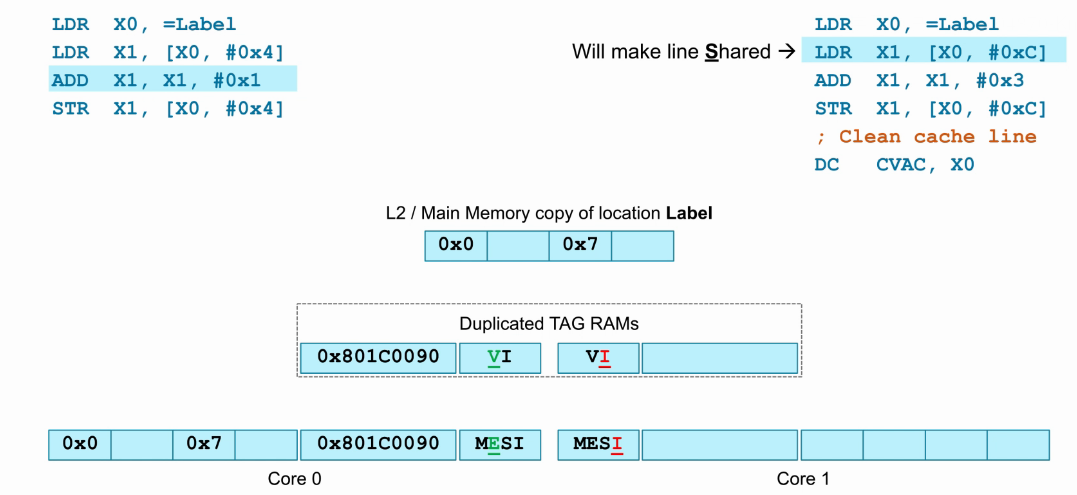
- 如下图,展示了上一步的执行结果,此时core0和core1都保持Share状态。
- 此时core0将load回来的数据0x7加1后,写回原地址,也就是“STR X1, [X0, #0x4]”指令。
- core0 cache中的该cacheline数据进行了更新,并更改为Modify状态,因为此时core0 cache数据是最新的。
- core1 cache中相应的cacheline数据已经与最新的数据不同,所以置为invalid,同时Dup_TAG_RAM也同步为invalid。
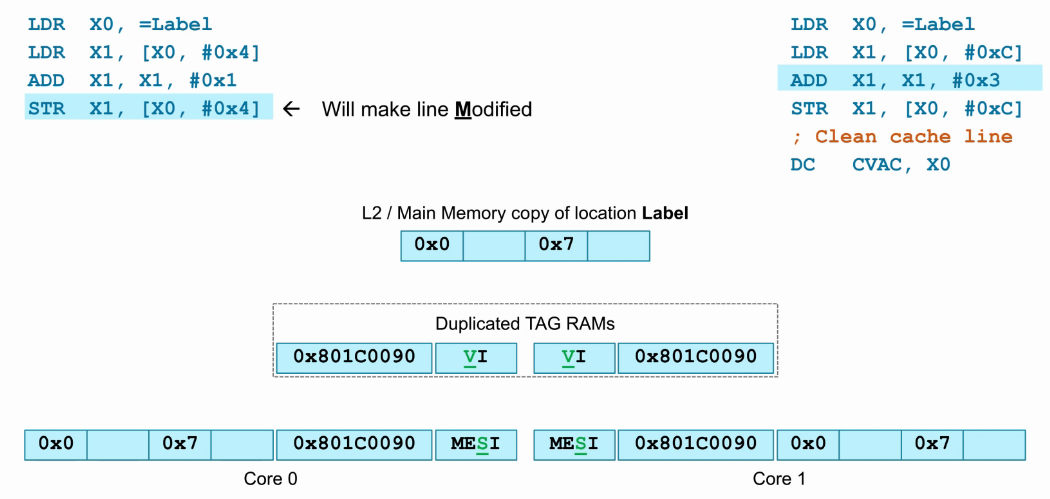
- 如下图,展示了上一步的执行结果,core0处于Modify状态,core1处于Invalid状态。
- 此时core1将load回来的数据0x0加3后,写回原地址,也就是“STR X1, [X0, #0xc]”指令。
- core1 cache中的该cacheline数据进行了更新,并更改为Modify状态,因为此时core1 cache数据是最新的,同时Dup_TAG_RAM也同步为Valid。
- 除此之外,还会将core0中该cacheline的数据更新到core1。
- core0 cache中相应的cacheline数据已经与最新的数据不同,所以置为invalid,同时Dup_TAG_RAM也同步为invalid。
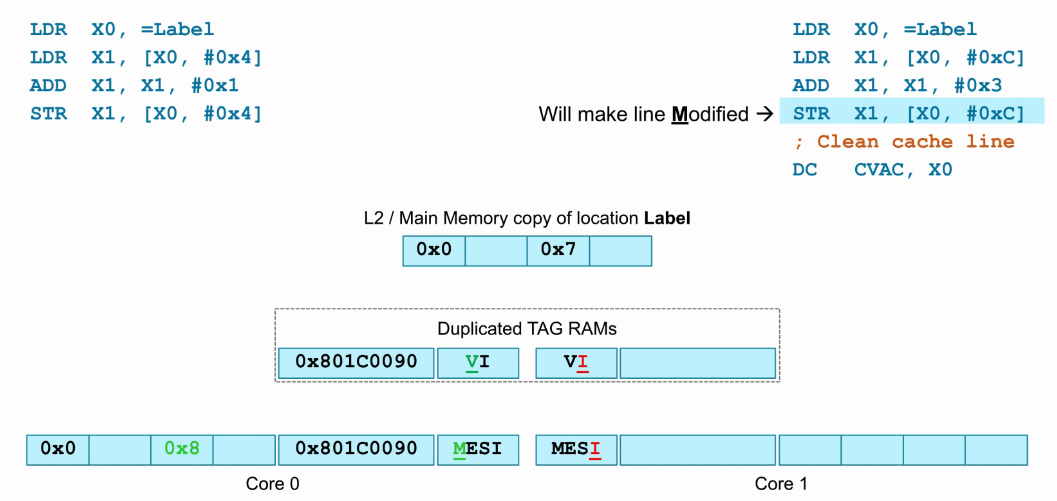
- 如下图,展示了上一步的执行结果,core0处于Invalid状态,core1处于Modify状态。
- 此时core1执行“DC CVAC, X0”指令,clean cacheline,也就是将cacheline更新到L2/主存。
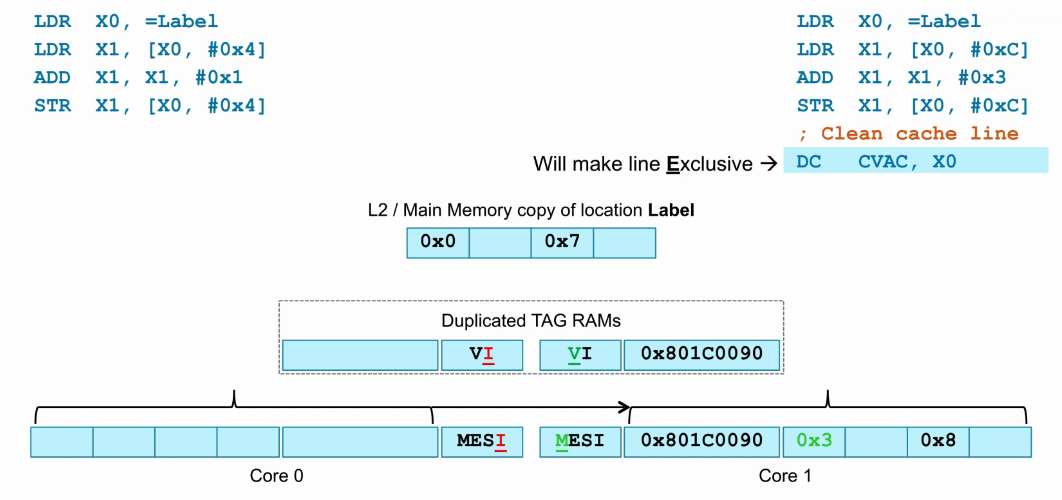
- 如下图,展示了上一步的执行结果,core0处于Invalid状态,core1处于Exclusive状态,因为此时core1 cache中该cacheline与L2/主存数据一致,且只有core1 cache存在该cacheline。
Multi-cluster coherency
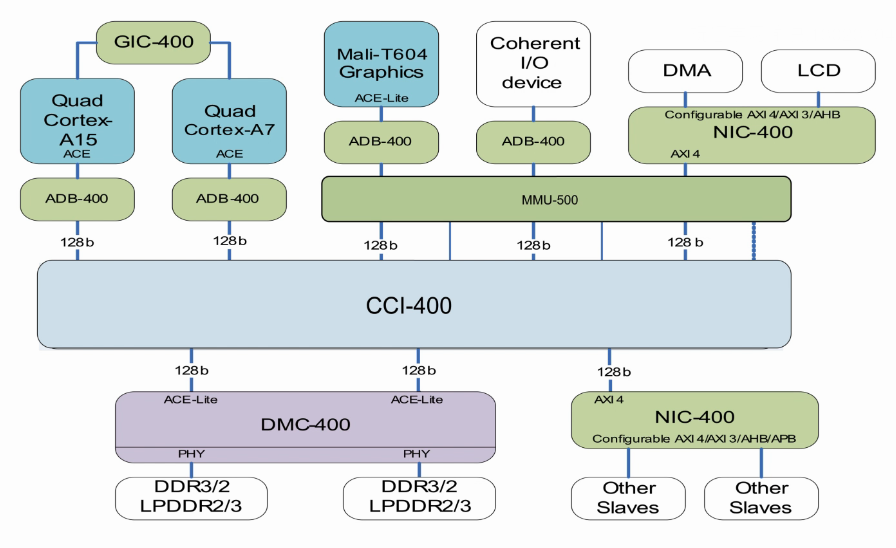
- 以上讲的是cluster内core与core之间的cache一致性,那么cluster与cluster之间是如何保存cache一致性呢?请看下图。
- 以下是Big.little结构,大核是A15,小核是A7,A15与A7内都有4个core。
- cluster与cluster之间保持cache一致性,是通过总线来实现的。首先每个cluster内存在一个ACE接口,会互相监测(snoop)对方cache的数据,如果对方cache不存在所访问的数据,则从下一级存储去取,如果对方cache存在所访问的数据,则从对方cache去获取。
- 目的就是减少主存(DDR)的访问,一是减少访存时间,二是减少BUS访问阻塞,三是减少Memory controler的访问请求,四是减少功耗。
AMBA Protocol发展
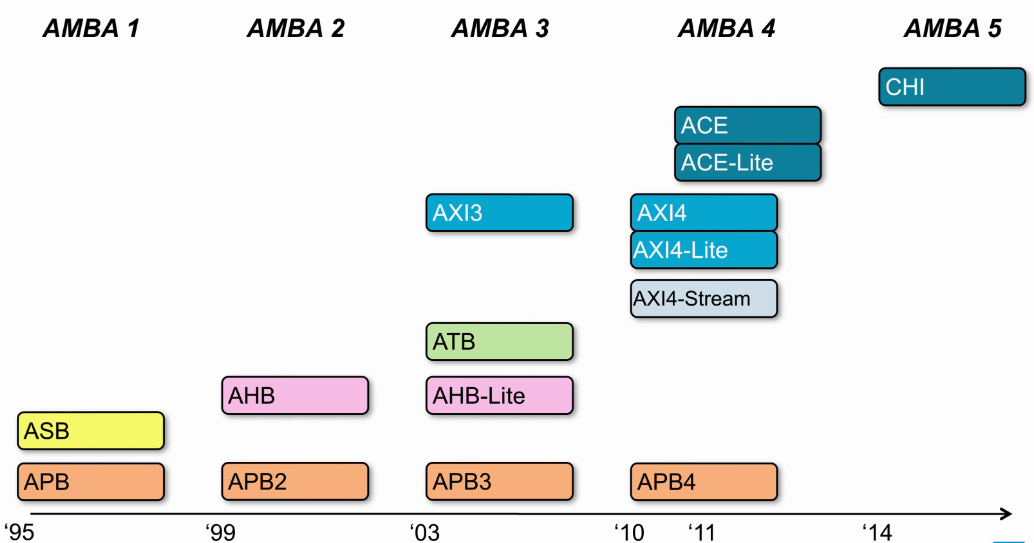
- 多core要保证cache一致性,所以添加了ACE协议。
- CHI相比ACE要复杂很多,这些都是保证cache一致性的重要协议。
CCI & CCN
- CCI只支持ACE cluster。


Cluster Coherency举例
- Read :
3个Master,也就是3个cluster。这里的Master概念是对CCI而言的。
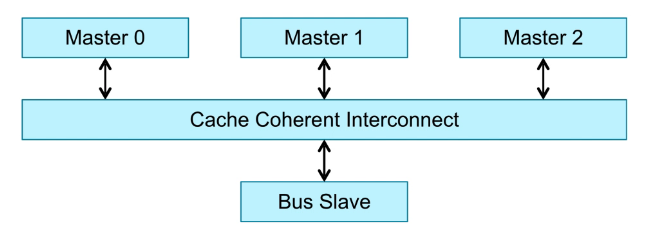
Master0发送一个read请求。
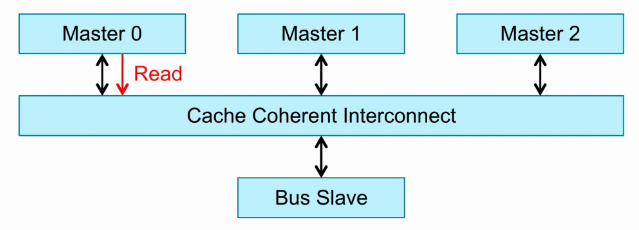
Cache Coherent Interconnection监测Master1和Master2,看Master1和Master2有没有Master0访问的数据。
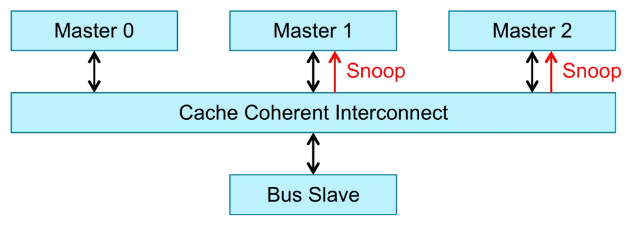
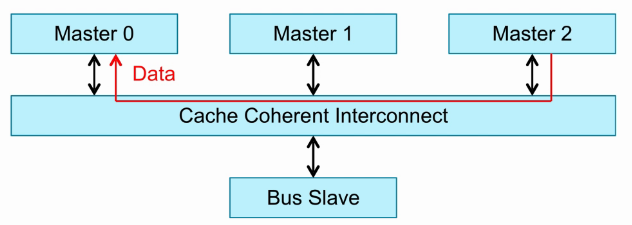
如果Master2存在Master0访问的数据,则通过CCI将Master2的数据返回给Master0。
如果Master1和Master2都不存在Master0访问的数据,只能通过CCI访问BUS Slave,发出BUS请求,从主存(DDR)中取数据。
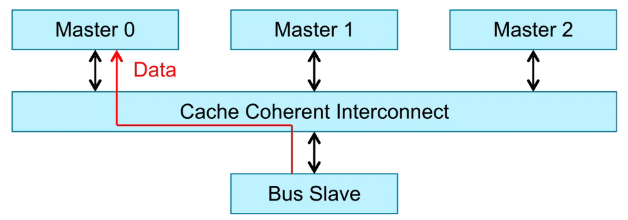
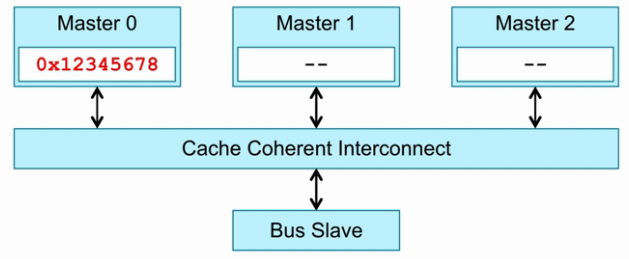
- Write :
3个Master,也就是3个cluster。这里的Master概念是对CCI而言的。
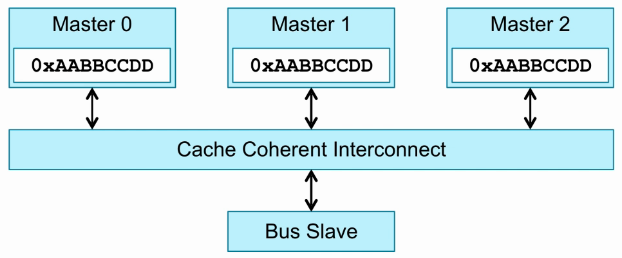
Master0发送一个write请求。
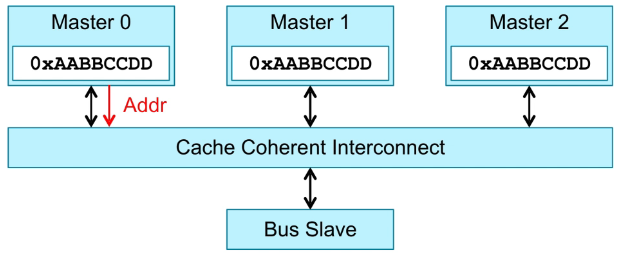
Cache Coherent Interconnection监测Master1和Master2。
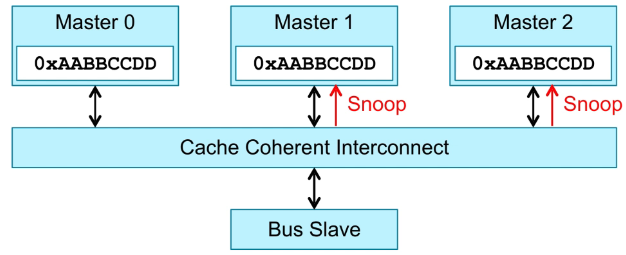
写操作导致Master1和Master2与Master0数据不同,这时要将Master1和Master2对应的数据置为Invalid,之后要返回Response给CCI。
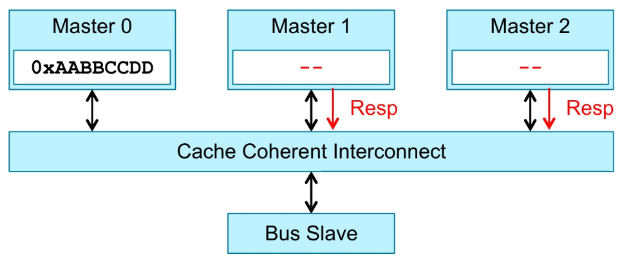
CCI接收Master1和Master2的Response后,返回Response给Master0。
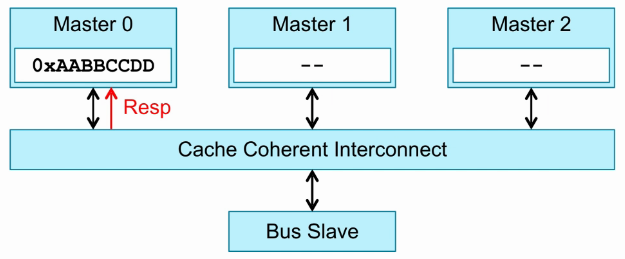
Master接收CCI的Response,确保Master1和Master2已经完成相应操作,才将数据写入cache。
ARM处理器的容错机制
Fault Tolerance介绍
- 设计的系统,我们希望能够按照自己期望的逻辑去工作,但是系统工作时可能由于某些原因导致不稳定。
- 物理环境:X射线、高温…
- 系统环境:存在未知的bug…
Faults、Error、Failure
-
Fault:Deviate(偏离) from specific behavior
- 例如 5+3=7
- 这种Fault又被称为Latent Error(潜在的错误)
- 意思是逻辑中存在Fault,但是不执行不会导致系统Error。
-
Error:Actual behavior within system differ from specific behavior
- 触发后的Fault,真正的error。
- 例如 add指令执行5+3,得到结果7,并写回的寄存器。
-
Failure:System deviates from specific behavior
- 系统行为发生错误。
- 例如 预定一个会议,计划是8点钟,由于执行了5+3指令,导致时间变为了7点钟。
-
以上Fault、Error、Failure依次递增的:
- Fault不一定导致Error,显然只要不执行就可以;
- Error不一定导致Failure,比如系统执行“5+3 >0”,显然即使5+3=7,,但不影响系统的结果。
Reliability and Availability
-
System states(系统状态):
- Service Accomplishment(系统正常的工作状态)
- Service Interruption(系统中断状态)
-
Reliability(可靠性):Continuity of correct service(系统正确运行的连续性),也就是Service Accomplishment状态。
-
Availability(可用性):Readiness for correct service(系统正确运行的准备时间),也就是Service Interruption状态。
-
Availability实际是一个比例,比如Service Accomplishment状态保持90小时,Service Interruption状态保持10小时,那么Availability是90%。
Fault类型
-
By Causes:
- Design faults(Sortware/Hardware bugs)
- Operation faults(User wrong operation)
- Environment faults(Fire, X-ray)
-
BY duration(持续时间):
- Permanent(永久性):Hardware broken
- Intermittent(间歇性):Last for while but recurring
Faults容错技术
-
2-way Redundancy(冗余):
- Two modules do the same work, then compare
- Error detection(检测)
-
3-way Redundancy(冗余):
- Three modules(or more) do the same work, then vote(投票)
- Expsensive, but can detect and correct 1 module error
-
以上只是通用的解决方法,对于正确性要求比较严格或在特殊环境下运行的系统,可采用3-way方法,但是对于存储数据来说,采用2-way或3-way的代价很大,所以对于memory的容错技术,提供了新的方法。
-
Parity:
- A Parity bit is generate within a specific granule
- Error detection
- 也就是常说的奇偶校验。

- ECC:
- ECC bits are generate from a chunk of data
- SECDED(Single error correct double error detect)
- 由于奇偶校验只能检查错误,而ecc可以纠正单比特错误,检查双比特错误,所以在memory的容错技术中应用最广。

Cache ECC
-
ECC(Error Checking and Correction)。
-
ECC由最简单的奇偶校验演变而来,先来介绍奇偶校验。
-
奇偶校验 :
优点:结构简单,只需异或计算就可以实现,数据量小时(8比特)实现代价小。
缺点:不能修正错误,只知道8比特中有部分比特发生错误,无法判断哪几个比特发送错误;有偶数个比特位时,无法判断出错;数据位宽较大时实现代价大:如1024比特数据,需要256bit的校验位。
实现:每8bit数据增加一位Parity,作为校验位,将这8bit异或相加,假设结果为5,如果是奇校验(数据和校验位一共奇数个1),那么Parity为0(因为0+5为奇数),如果为偶校验(数据和校验位一共偶数个1),那么Parity为1(因为1+5为偶数)。当发生1bit错误时,可以根据Parity检查出数据错误。
- ECC校验 :
优点:大量数据位实现代价低:8比特数据需要5个校验位,256字节(256*8比特)的数据值需要5个列校验位和11行校验位;能够纠正错误:在内存中ECC能够容许错误,并可以将错误更正,使系统得以持续正常的操作,不致因错误而中断
缺点:当数据只有单比特错误时,ECC能够进行错误修复;超过2比特的数据错误,将无法修复,ECC只能输出多比特错误信号;不保证能检测超过2比特的错误。
实现:待补充
Synchronization
Synchronization示例
- 线程A和线程B都在对count进行操作,而且两个线程可能由不同的core执行。
- 不同的core去执行,从时间上来看,指令间相互穿插执行,同时对count进行操作,导致结果无法确定,这时候就需要同步的处理。
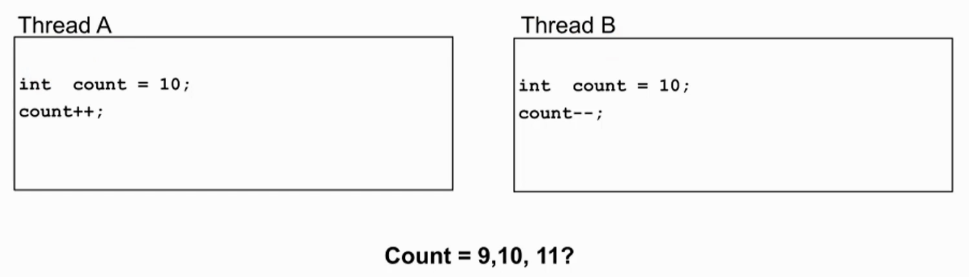
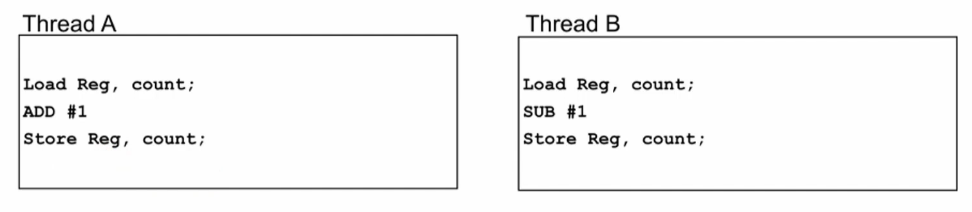
示例分析
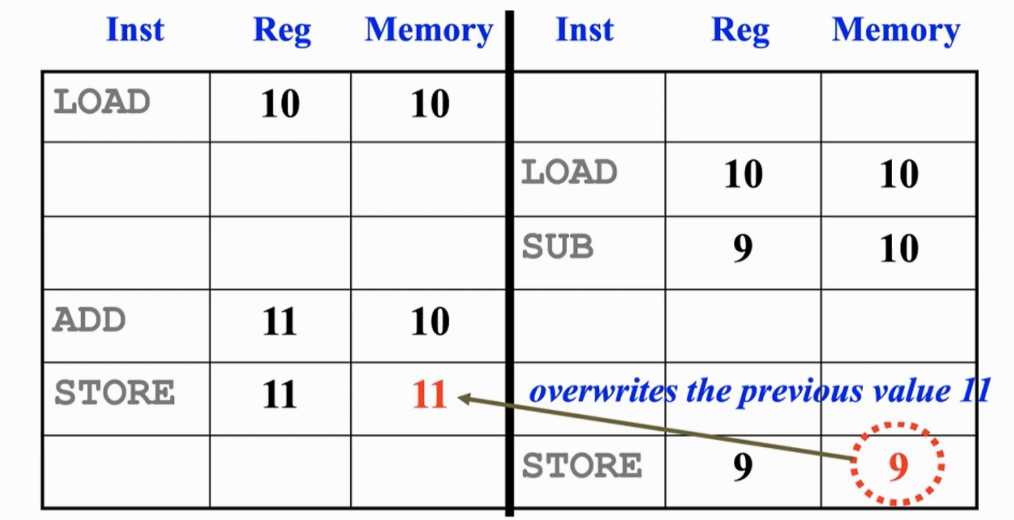
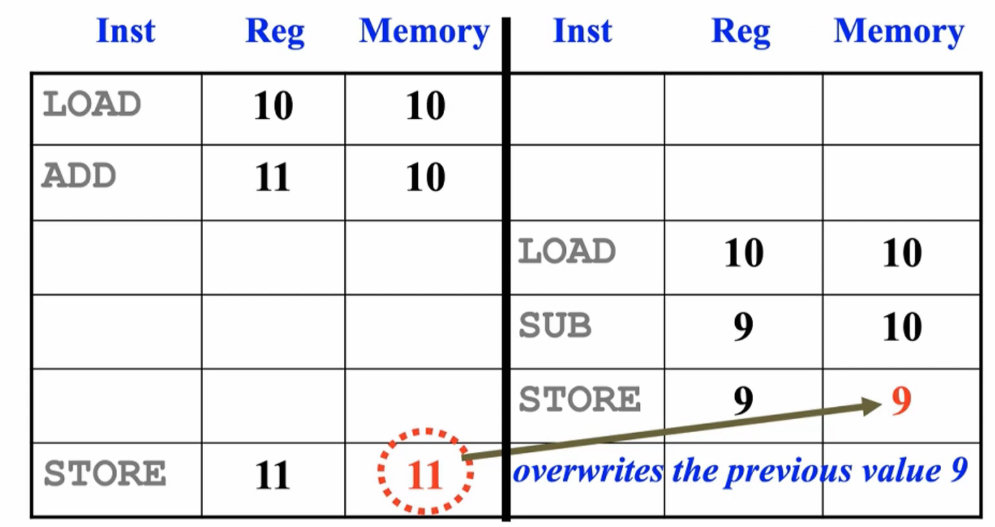
- 线程间出现竞争:
- 两个线程对共享资源进行操作。
- 程序的执行结果取决于程序指令的执行顺序。
- 为了避免竞争的发生,应该在竞争相关的线程间做同步,也就是先执行线程A程序段,再执行线程B程序段,或者相反。
原子访问必要性
- 上文提到的线程间竞争,主要是因为read-modify-write程序段,而这样的程序段是经常出现的。
- 这样的read-modify-write程序段,使用共享数据时,这几条指令必须是原子指令,也就是这几条指令像一个原子一样是一个整体,必须顺序完成,中间不可穿插其他指令。

- Critical Sections(关键代码段):
- 访问share资源的关键代码段
- 为了保证Critical Sections的执行,需要进行上锁,只要当拿到钥匙后,才可以执行。
- 上锁方法:Mutex、Semaphore、Flag、Lock…
同步锁
-
什么是锁?
- 是一个存放在memory中的lock值。
- lock值一般使用一个整数,0/1/2…
- 只要程序间能达成握手协议即可。
-
怎么获取lock?
- 先初始化lock为0,也就是未上锁状态。
- Critical Sections程序中去检查是否已上锁,如果已上锁状态则等待,如果未上锁状态则可以执行。
- 执行的第一步是要上锁,也就是将lock设置为1。
- 执行完所有程序后,需要解锁,也就是将lock设置为0。

- 这样线程A和线程B都有检查是否已上锁的逻辑,是否能保证指令能够正确执行呢?换句话说,上锁的逻辑线程间有没有可能存在竞争?答案是存在。
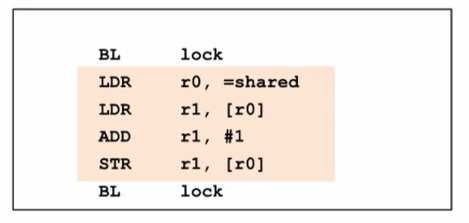
实现锁的指令
-
ARM架构里,使用Load Exclusive指令代替上文查锁和上锁指令的LDR:
- LDXR(A64)
- LDREX(A32 and T32)
-
ARM架构里,使用Store Exclusive指令代替上文查锁和上锁指令的STR:
- STXR(A64)
- STREX(A32 and T32)
-
Exclusive指令的作用是什么?后文介绍。
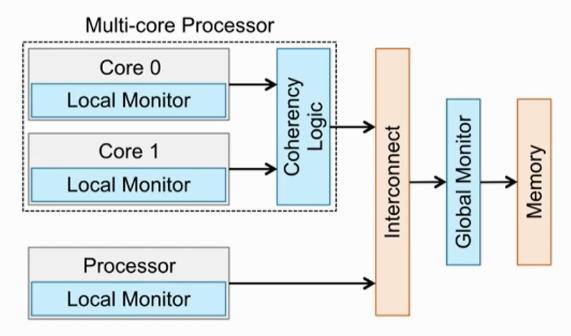
Exclusive Monitor
- 要想实现Load/Store Exclusive操作,需要硬件Exclusive Monitor的支持。
- Exclusive Monitor的作用就是监测Lock地址。
- 每个CPU core内都会有一个local monitor,监测其他core的访问地址,如果某线程使用的lock,local monitor会记录lock地址,其他线程再访问该地址时,是无法访问的。
- 每一个cluster都会有一个Global Monitor,其功能与local monitorx相似,监测其他cluster的访问地址。
- 如果core0访问lock地址,且存储属性为non-sharable,那么core0不会与其他core共享lock数据,只需要查看local monitor,不需要查看global monitor。
monitor工作原理
LDREX Rx, [Ry]
STREX Rx, Ry, [Rz]
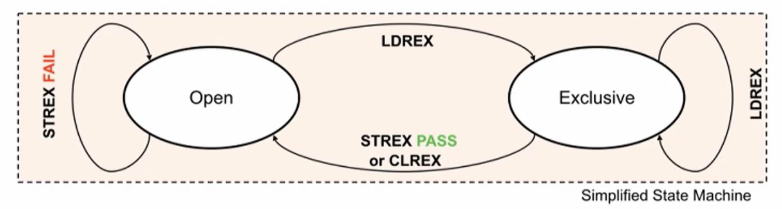
- Open状态:其他线程可访问
- Exclusive状态:其他线程不可访问
- LDREX用来读取内存中的值,并标记对该段内存的独占访问。
- 如果执行LDREX指令时,Ry指向内存区域为非独占访问(OPEN),将Ry指向内存数据保存到Rx寄存器中,同时标记对Ry指向内存区域的独占访问。
- 如果执行LDREX指令时,Ry指向内存区域为独占访问,不影响指令功能。
- STREX在更新内存数值时,会检查该段内存是否已经被标记为独占访问,并以此来决定是否更新内存中的值。
- 如果执行STREX指令的时候发现已经被标记为独占访问了,则将寄存器Ry中的值更新到寄存器Rz指向的内存,并将寄存器Rx设置成0。指令执行成功后,会将独占访问标记位清除。
- 如果执行STREX指令的时候发现没有设置独占标记,则不会更新内存,且将寄存器Rx的值设置成1,STREX Fail。
- 举例说明:假设系统中有两个处理器内核,而一个程序由三个线程组成,其中两个线程被分配到了第一个处理器上,另外一个线程被分配到了第二个处理器上。且他们的执行序列如下:
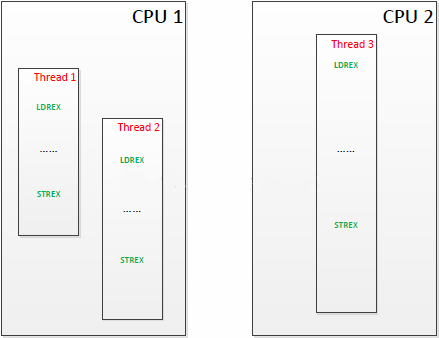
- CPU2上的线程3最早执行LDREX,锁定某段共享内存区域。它会相应更新本地监视器和全局监视器。
- 然后,CPU1上的线程1执行LDREX,它也会更新本地监视器和全局监视器。这时在全局监视器上,CPU1和CPU2都对该段内存做了独占标记。
- 接着,CPU1上的线程2执行LDREX指令,它会发现本处理器的本地监视器对该段内存有了独占标记,同时全局监视器上CPU1也对该段内存做了独占标记,但这并不会影响这条指令的操作。
- 再下来,CPU1上的线程1最先执行了STREX指令,尝试更新该段内存的值。它会发现本地监视器对该段内存是有独占标记的,而全局监视器上CPU1也有该段内存的独占标记,则更新内存值成功。同时,清除本地监视器对该段内存的独占标记,还有全局监视器所有处理器对该段内存的独占标记。
- 下面,CPU2上的线程3执行STREX指令,也想更新该段内存值。它会发现本地监视器拥有对该段内存的独占标记,但是在全局监视器上CPU1没有了该段内存的独占标记(前面一步清空了),则更新不成功。
- 最后,CPU1上的线程2执行STREX指令,试着更新该段内存值。它会发现本地监视器已经没有了对该段内存的独占标记(第4步清除了),则直接更新失败,不需要再查全局监视器了。
- 所以,可以看出来,这套机制的精髓就是,无论有多少个处理器,有多少个地方会申请对同一个内存段进行操作,保证只有最早的更新可以成功,这之后的更新都会失败。失败了就证明对该段内存有访问冲突了。实际的使用中,可以重新用LDREX读取该段内存中保存的最新值,再处理一次,再尝试保存,直到成功为止。
同步过程
- LDXR指令,独占访问,将lock值读取到w1。
- 比较是否为已上锁状态,如果已上锁,则循环读取lock,如果未上锁,则向下执行。
- STXR指令,独占访问,进行上锁操作,也就是将已上锁状态值写入lock指向的地址。
- STXR指令执行不一定成功,因为可能有其他线程已经先执行STXR指令。
- 判断STXR指令是否执行成功,若未成功,则重新执行查锁操作。
- 只有STXR指令执行成功,才是真正拿到锁,拥有执行权限。

- 待拿到执行权限后,开始执行程序段,程序段执行完成后,需要解锁。
- 解锁操作很简单,就是项lock指向的地址写未上锁状态值。

总线原子访问
- 原子访问(Atomic access)。

- Lock访问(AXI3 only):如果一个Master lock访问slave,那么其他Master则无法访问slave。这样会对系统性能造成一定影响。
- 早些的ARM处理,如ARM7,由SWP指令实现lock访问。
- Coretex-M3/M4(采用AHB协议,非AXI)通过bit-banding操作实现lock访问。
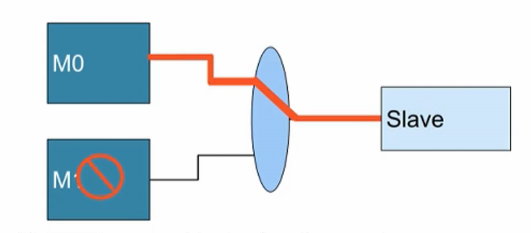
- 在AXI4中只有Exclusive访问,取消了lock访问,对于Exclusive访问,其他Master仍可以访问Slave,不会影响性能。
总线Exclusive访问机制
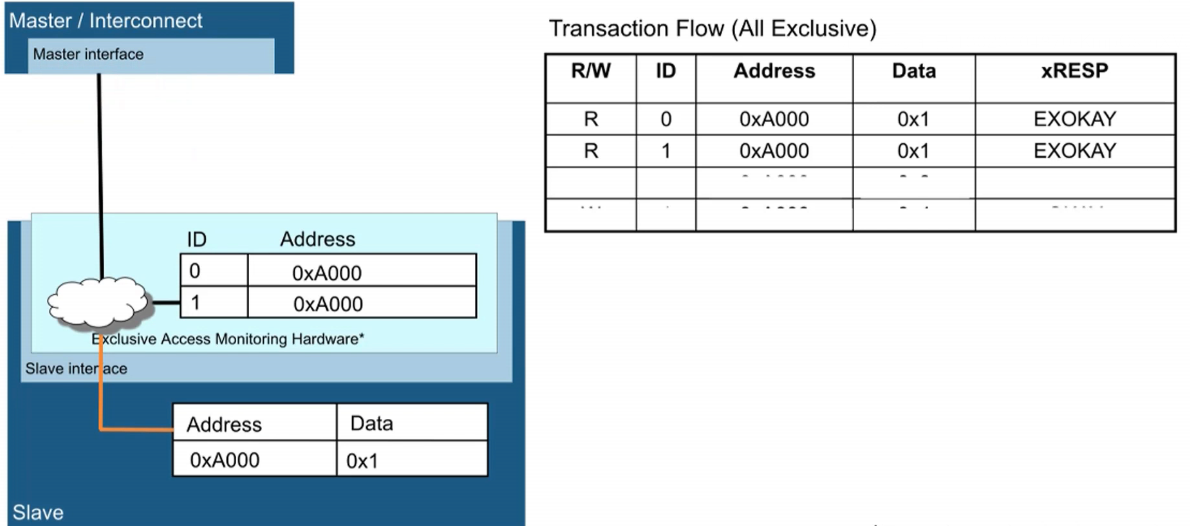
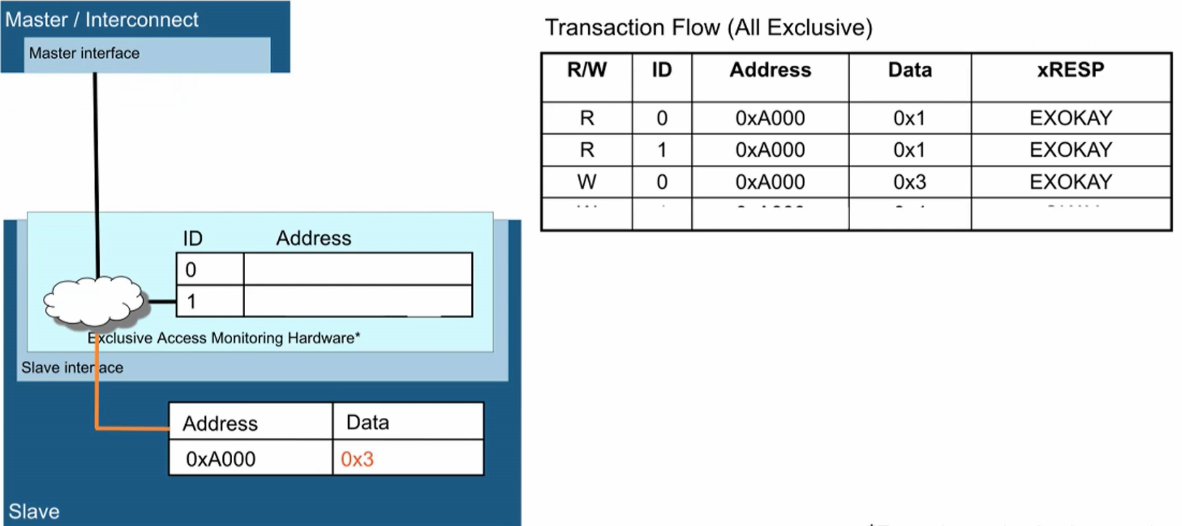
- 0x1代表未上锁,0x3代表已上锁。
- Master0去读0xA000地址,数据为0x1(未上锁),返回EXOKAY,将0xA000地址置为Exclusive。
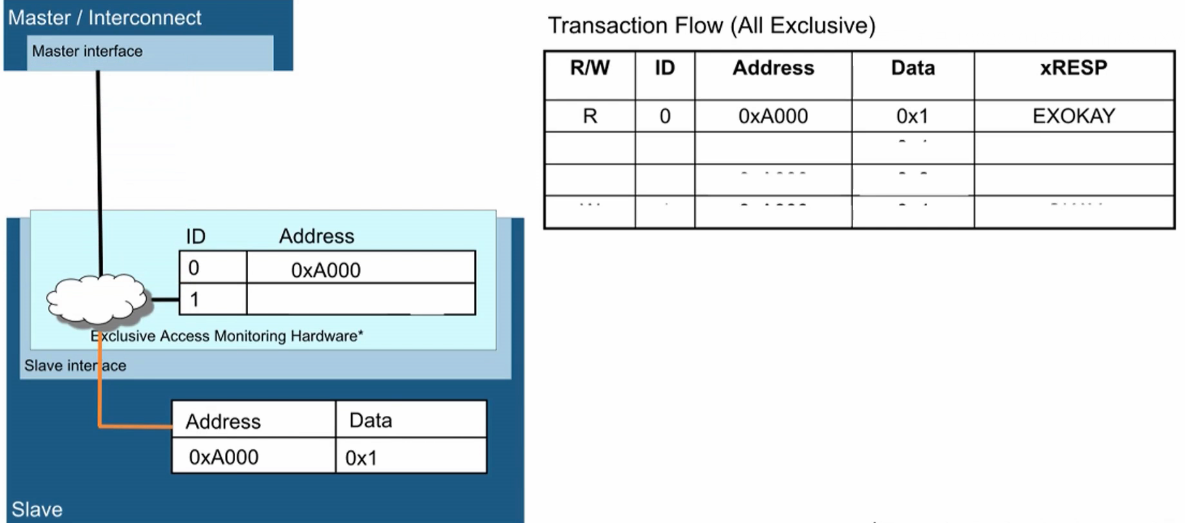
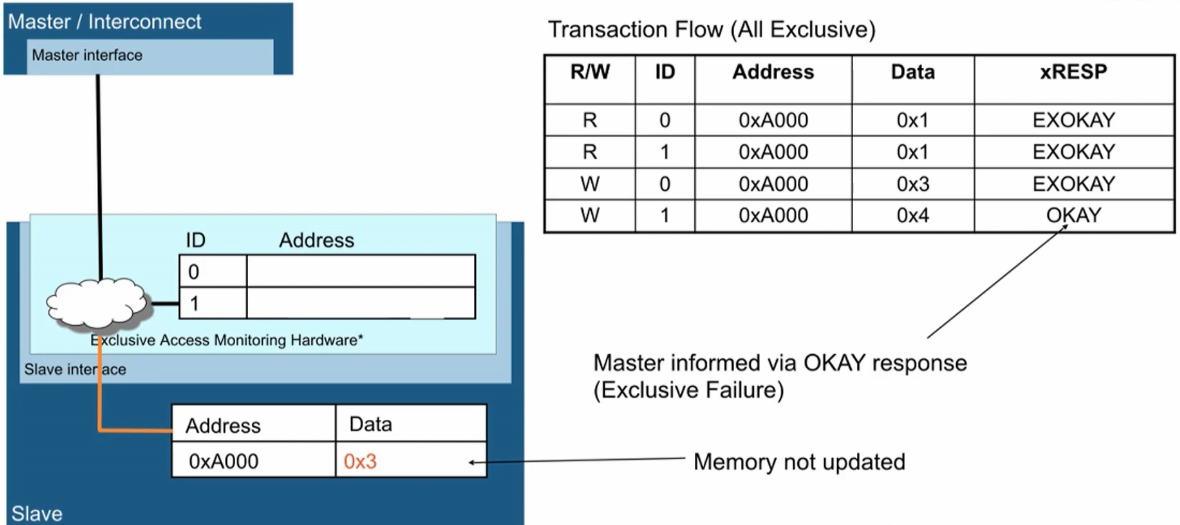
- Master1也去读0xA000地址,数据为0x1(未上锁),返回EXOKAY,0xA000地址仍保持Exclusive。
- Master0去写0xA000地址,写数据为0x3(上锁),返回EXOKAY,上锁成功,0xA000地址置为OPEN状态。
- Master1也去写0xA000地址,写数据为0x3(上锁),返回OKAY,上锁失败,0xA000地址保持OPEN状态。
多核并行处理
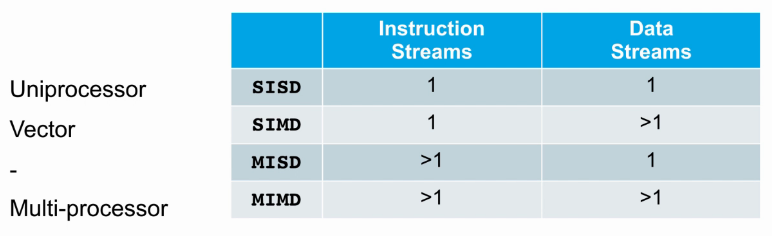
Multi-Processing 介绍
- How many instruction stream(同时可以执行多少指令)?
- How many data stream(同时可以运算多少数据)?
ARM NEON指令
- NEON指令是一种Advanced SIMD指令的扩展。
- 操作数寄存器被视为包含多个元素的向量。
- 在多个lane上同时执行操作。
- NEON多用于图像处理等循环运算较多的运算场景。
NEON和SIMD的优势
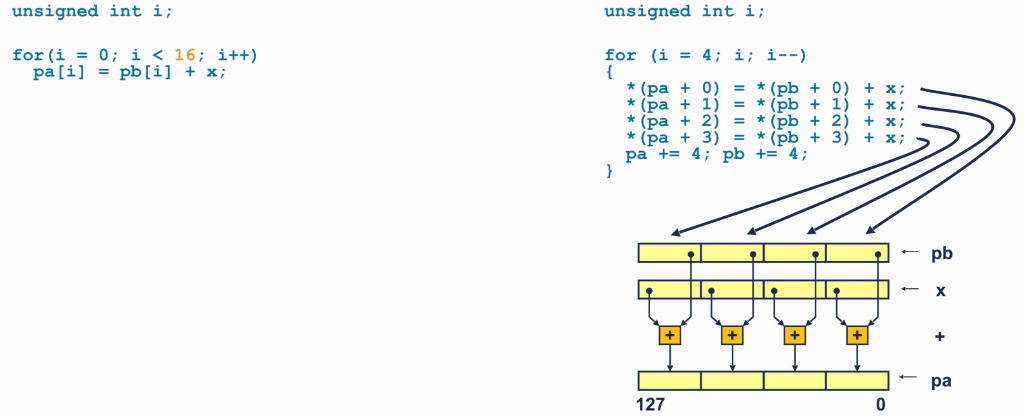
SIMD和NEON指令比较
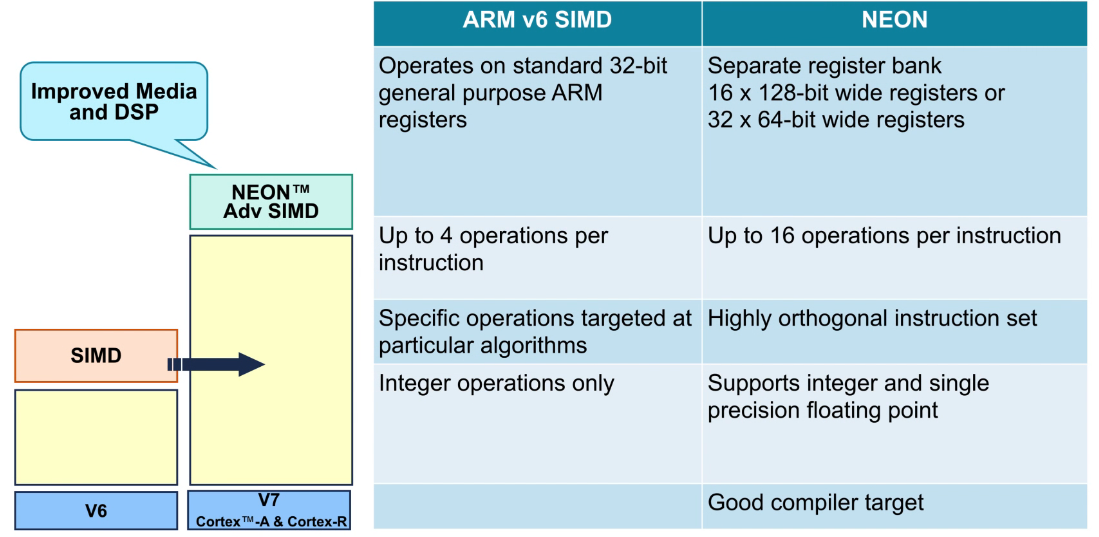
AMP(Asymmetric Multi-Processing)
-
每个CPU可能运行不同的程序:
- 可能会看到不同的内存映射。
- 可能有自己的一组中断。
-
通过共享内存进行数据交换:
- 必须对CPU L1 cache进行一致性管理
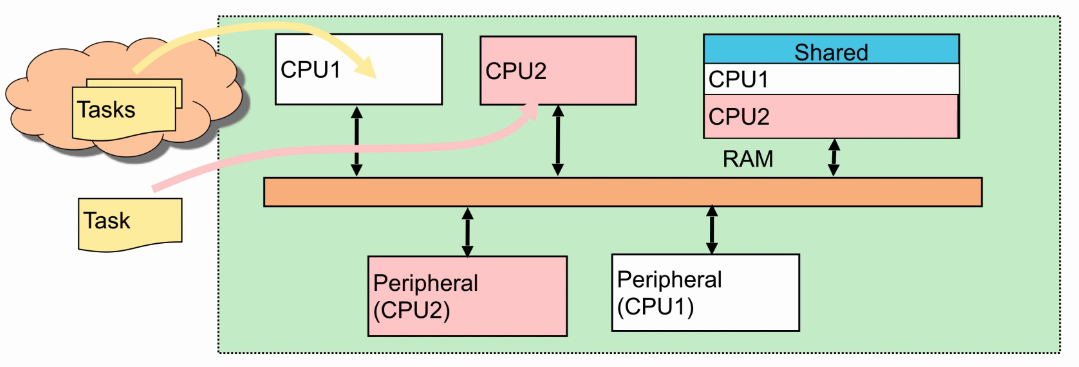
SMP(Symmetric Multi-Processing)
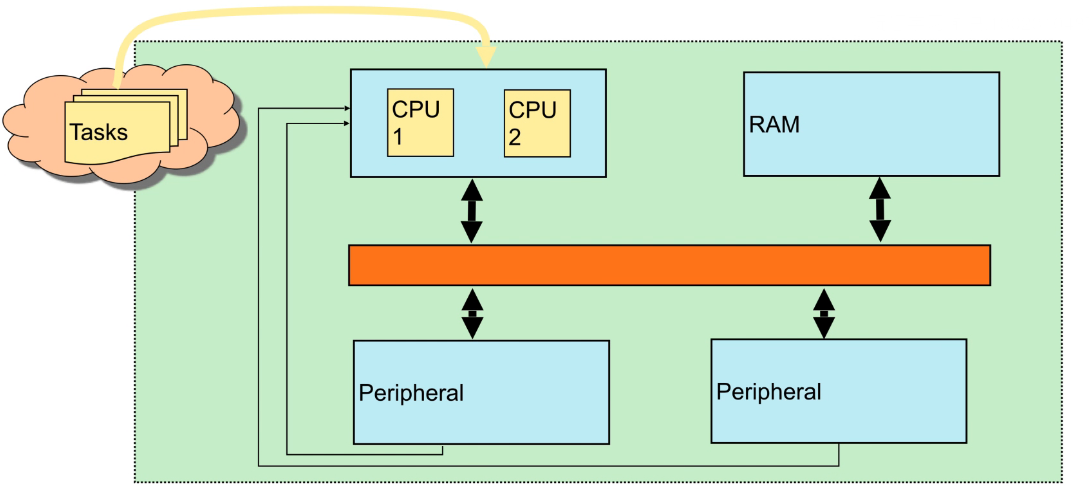
multi-Processing问题
- 两个CPU都执行load指令:
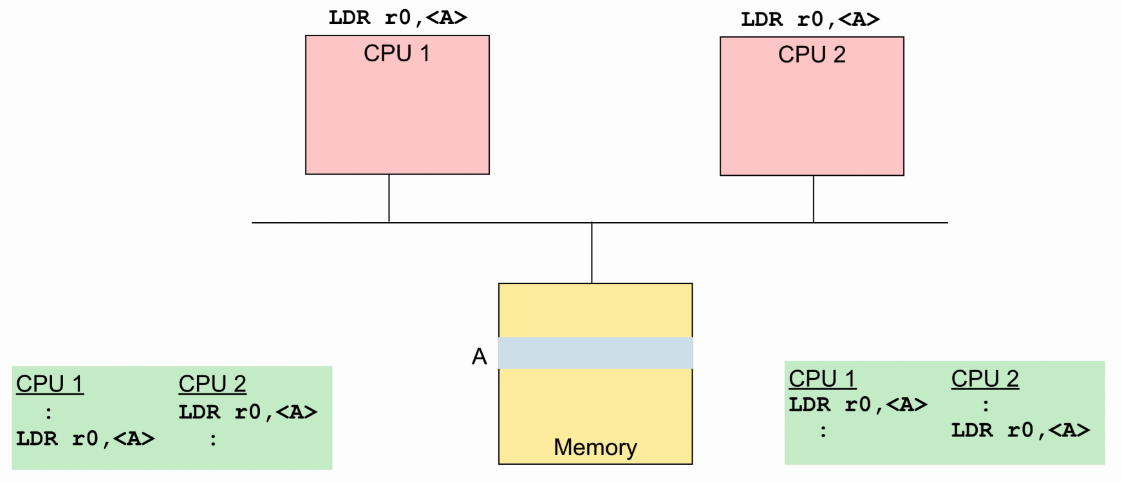
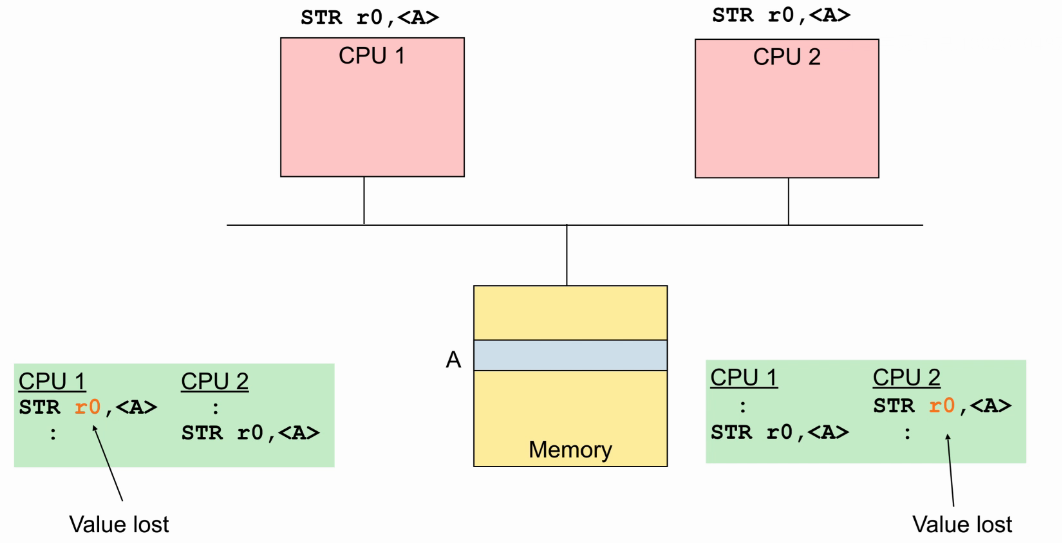
- 两个CPU都执行store指令:
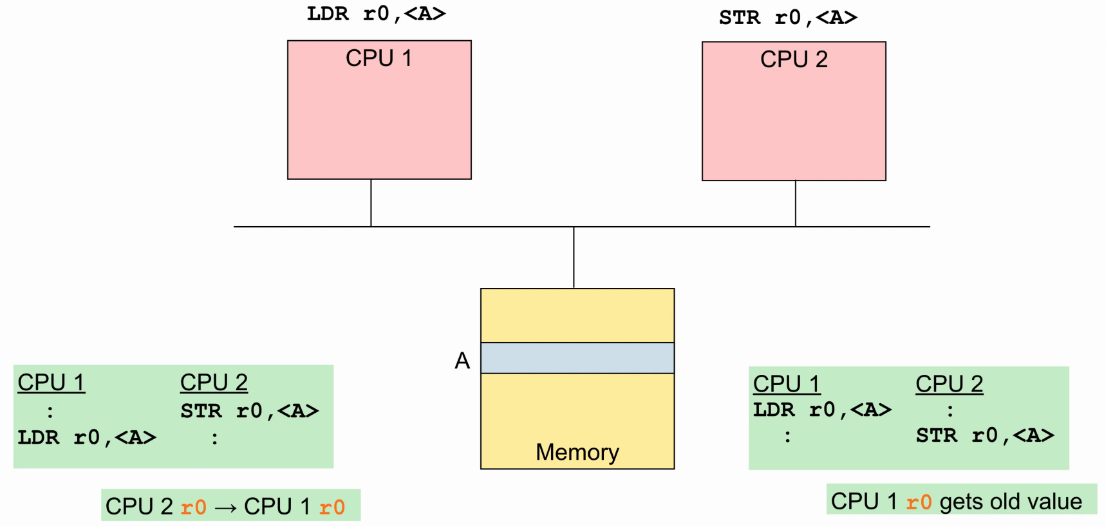
- 一个CPU执行store指令,另一个执行load指令:
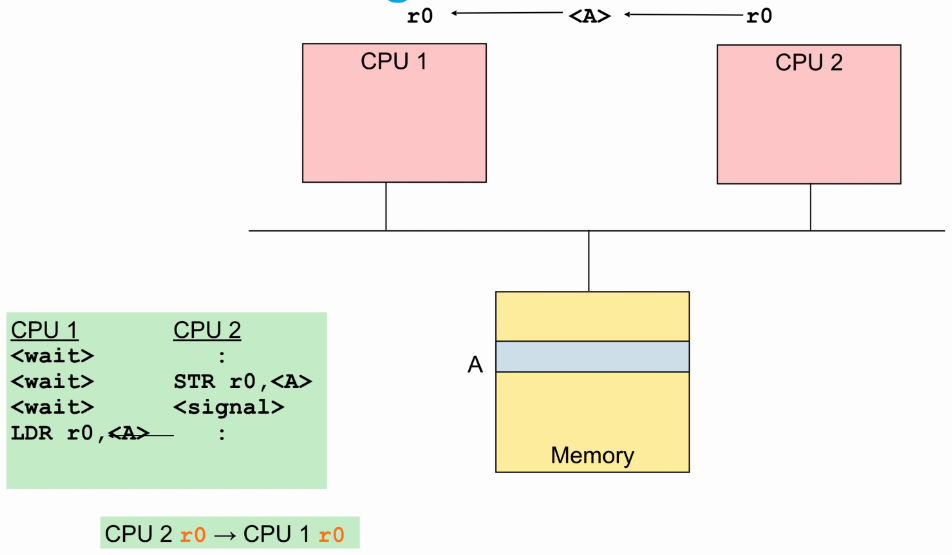
多处理器同步
- 多个core之间通过握手协议,CPU1必须等CPU2完成store指令后才能去load。
- 如果两个store发生冲突,也需要通过握手协议,确保指令执行顺序与期望相同。
Cluster处理器
- cluster翻译成中文为簇。
- 每个cluster可以包含1~4个core。
- 每个core都有自己私有的资源,比如L1 cache,cluster内包含的多个core共享的资源,比如L2 cache。

为什么需要big.LITTLE?
- 以前的结构里,一个cluster内4个core,4个core是同频的。
- 在手机的应用场景中,比如看电影、打游戏等,对性能要求较高,可能4个core在全速运行,而有些场景如收发邮件、听音乐等,对性能要求不高,4个core不需要全速运行,甚至可以在低频下工作,这样可以节省功耗。
- 从应用场景来分析,也就是分为两类,一是对性能要求高,二是对功耗要求高。
- 大小核的设计,就是根据不同应用场景,来选择选用高性能核运行还是低功耗核运行。

big.LITTLE处理器?
- 以Coretex-A7和Coretex-A15为例:首先大小核必须都属于同一个架构,这里A7和A15都属于ARM-v7架构。
- Coretex-A7:属于低功耗核。
- 8~11 stages, In-Order and limited dual-issue
- Coretex-A7:属于高性能核。
- 15+ stages, Out-of-Order and multi-issue, register rename
- 在一般应用程序中,性能比Cortex-A9平均高40~60%
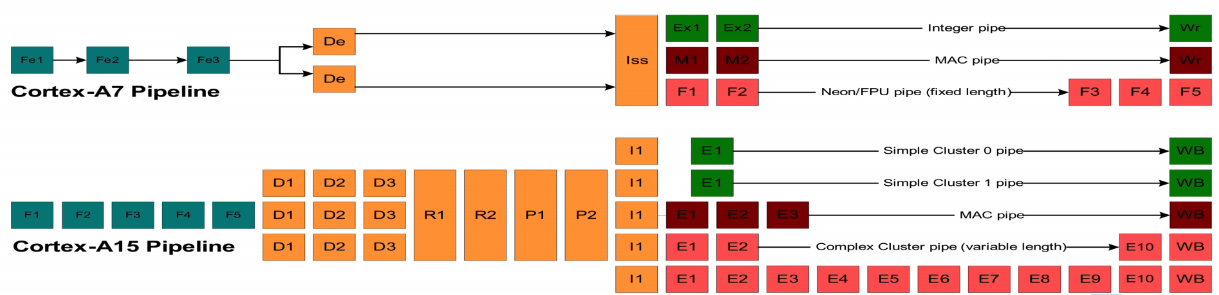
big.Little架构
- 一般的cluster架构:
- OS运行在一个cluster的CPU。
- cluster内有snoop control unit,来维护L1 cache的数据一致性。
- cluster内有中断控制器,将中断信息分配给对应的cpu。
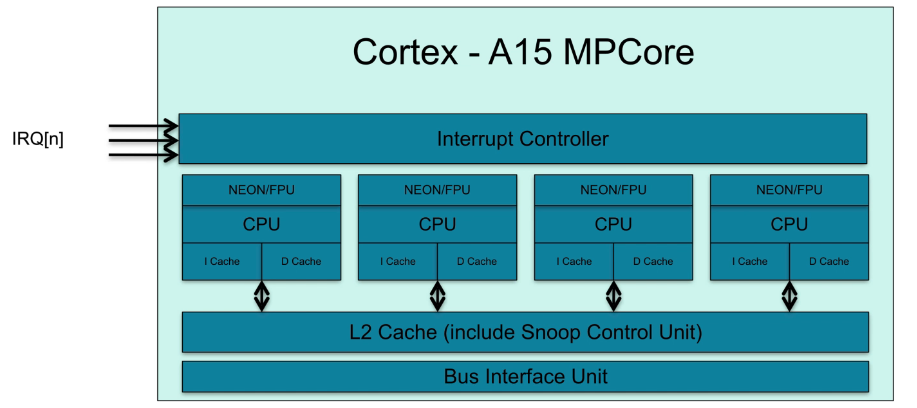
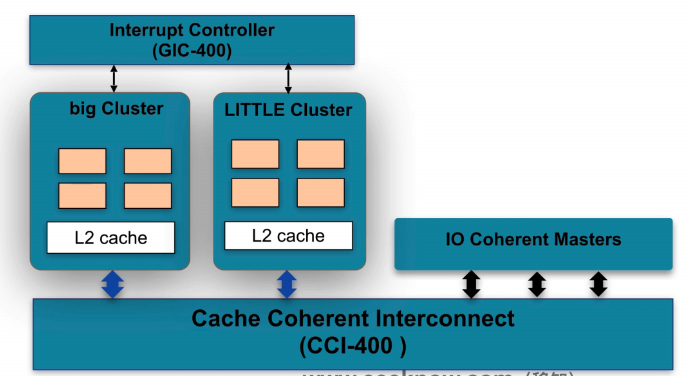
- big.LITTLE架构:
- 两个cluster,cluster内的cache数据一致性维护不变。
- OS运行在两个cluster中的CPU。
- 两个cluster共享一个中断控制器,将中断信息分配给对应的cluster,cluster再分配给对应的cpu。
- cluster间的数据一致性,通过CCI(Cache Coherent Interconnect)来维护。
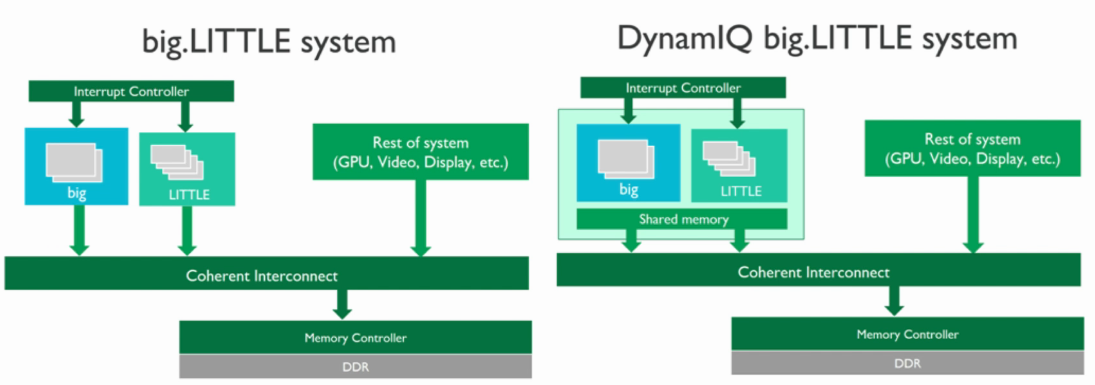
DynamIQ架构
- big.LITTLE结构中,有一个big cluster和一个little cluster,然后cluster之间通过CCI维护cache的数据一致性,这样通过BUS connection和访问内存来实现cluster间的交互,效率比较低。
- 在DynamIQ结构中,将big cluster和little cluster放在一起,通过Shared Memory(L3 cache)来完成cluster之间的交互,减少cluster对外部memory访问,从而提高性能,并且降低功耗。
- 举例:Kirin 980
- Kirin 970采用传统的big.LITTLE,Kirin 980采用DynamIQ big.LITTLE。
- 性能提高75%,效能提高58%。
- 两个Big core,A76 2.6G
- 两个Middle core, A76 1.92G
- 四个Little core, A55 1.8G
- 可见DynamIQ架构中,支持不同频率的core。

DSU(DynamIQ Shared Unit)
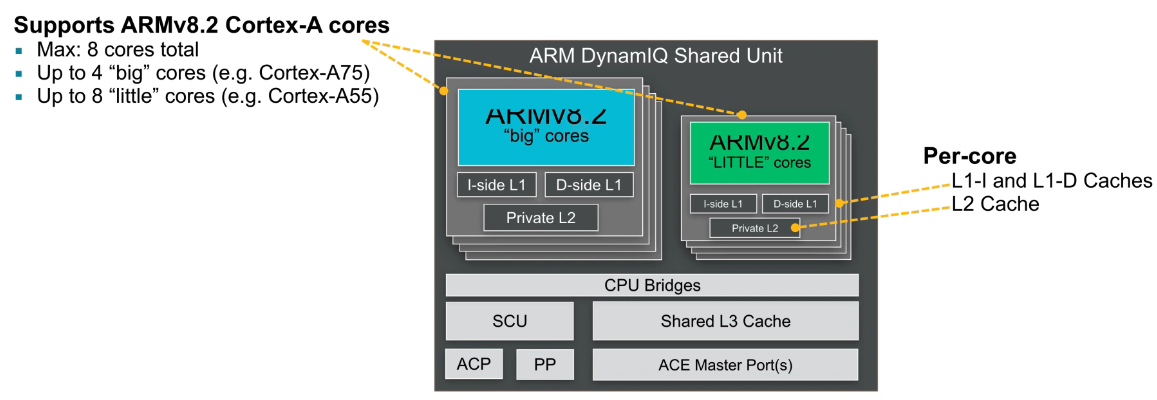
ARM多核系统和互联
多核挑战
- core的数量增加,on-chip(内部存储cache)的挑战。
- 更多的read和write bus请求,导致总线堵塞,需要提高bus的带宽(频率或数据宽度)。
- 更多的write shared location,为了维护cache数据一致性,会将其他core的cacheline invalid,这样会增加cache miss率。
- core的数量增加,off-chip(外部存储DDR)的挑战。
- 更多的on-chip cache
- 更多的访问主存请求(功耗和访问时间)
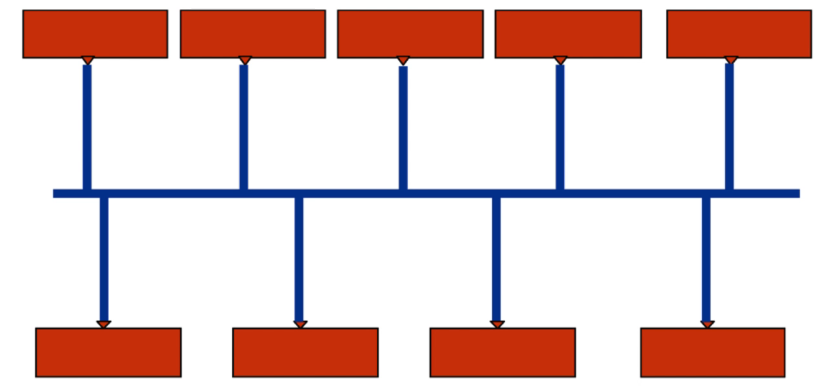
Shared Bus(Shared结构)
- 早期的bus结构。
- 比较简单的核间通信方式,内核挂在通信总线上,实现简单。
- 没两个核通信都需要占用总线,导致其他的核不能通信,通信效率极低。
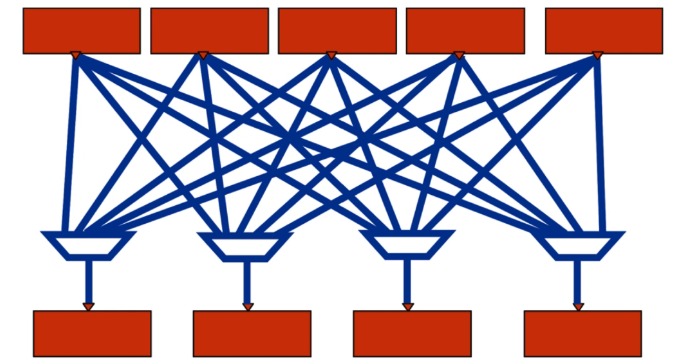
Cross Bar(交叉结构)
- 通信效率较高,每个core两两相连。
- 核太多,需要消耗大量的互联资源,通常用于四个核的处理器。
- 连线异常复杂,对后端布局布线有较大影响,频率难以提高。
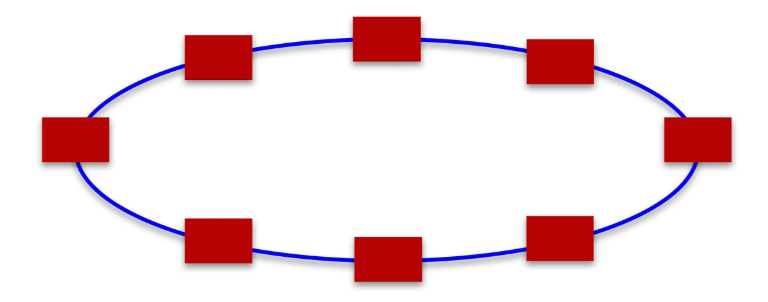
Ring(环形结构)
- 越近的两个core通信效率越高,通信连线并不复杂,实现成本低。
- 解决了绕线阻塞。
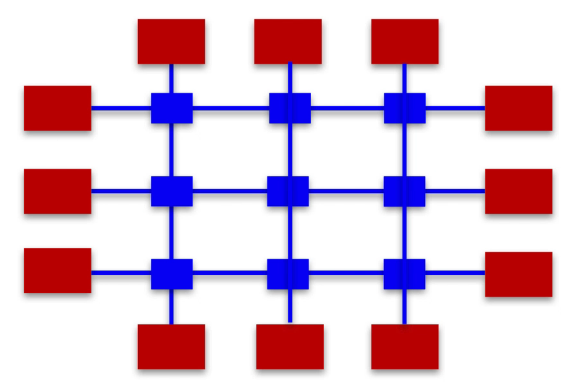
Mesh(网络结构)
- 适用于core数非常多的情况。
- 结构简单,易于扩展,通信效率高。
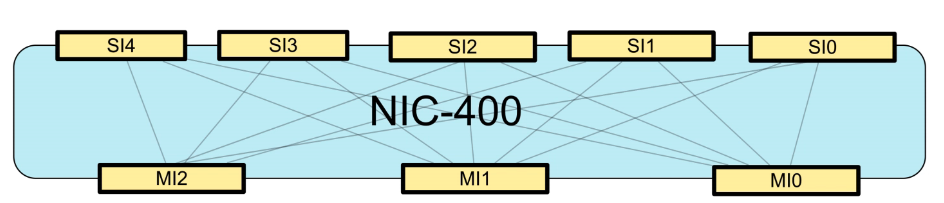
ARM NIC IP
- NIC(Network Interconnect)
- 不支持cache一致性(AXI/AHB/APB)
- Crossbar结构
- 适用于单cluster结构
ARM CCI IP
- CCI(Cache Coherent Inteconnect)
- AMBA 4 ACE-based Crossbar interconnect IPs
- core内支持ACE接口,可通过ACE协议维护cache一致性。

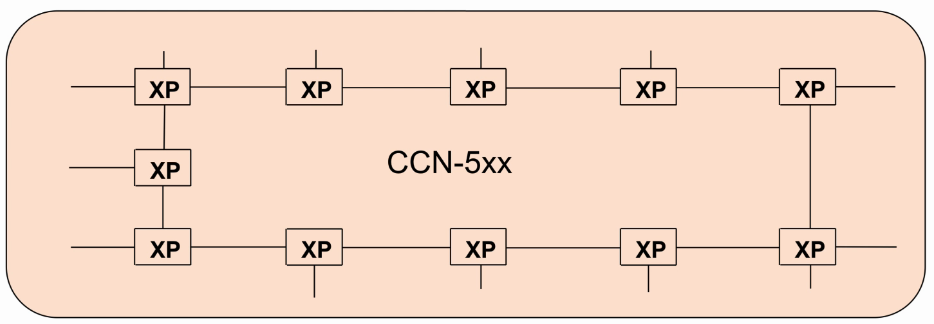
ARM CCN IP
- CCN(Cache Coherent Network)
- AMBA 5 CHI-base ring-bus interconnect IPs
- CCN-502/504/508/512…
- Crosspoints(XP)
- Has four ports, connected to processor, IO master, DRAM, peripherals
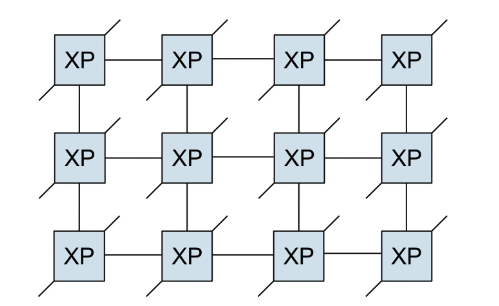
ARM CMN IP
- CMN(coherent Mesh Network) for high-end networking and enterprise applications
- Crosspoints(XP)
- Has six ports, connected to processor, IO master, DRAM, peripherals…
文章原创,可能存在部分错误,欢迎指正,联系邮箱 cao_arvin@163.com。